


一、模型概述
Lumina-Image 2.0是一款参数量为2.6B的DiT模型,它是一个开源且具备高效性、统一性和透明性的先进图像生成模型。这一模型在图像质量的呈现、排版的合理性、对复杂提示的精准理解以及资源利用效率等诸多关键方面都有着十分亮眼的表现。
-
开源的特性使得全球范围内的开发者和研究人员能够轻松获取并使用这一模型,进行二次开发和深入研究;
-
高效性保证了在实际应用场景中,能够快速生成符合需求的图像,节省大量的时间成本;
-
统一性则体现在模型对于不同类型的输入文本和多样化的图像生成需求,都能采用统一的架构和算法进行处理;
-
透明性则让使用者能够清晰地了解模型的运行机制和处理过程,便于进行调试和优化。

二、性能评测表现
Lumina-Image 2.0在图像生成领域所展现出的强大实力,通过一系列权威的Benchmark评测结果得到了充分的验证。在用于衡量生成图像与输入文本对齐程度,也就是生图文本跟随能力的DPG benchmark评测中,它成功斩获了87.2的高分,这一成绩超越了目前市面上已有的众多文生图模型。在另一个重要的GenEval评测中,其得分也达到了0.73,仅仅落后于DeepSeek发布的Janus-Pro-7B。这些出色的评测结果充分表明,尽管Lumina-Image 2.0只有2.6B的参数量,相较于一些大型模型来说规模较小,但它却具备相当优秀的文本跟随能力。这意味着该模型能够精准地理解用户输入的文本描述,并将其转化为高度匹配的图像内容,极大地满足了用户对于图像生成准确性的需求。
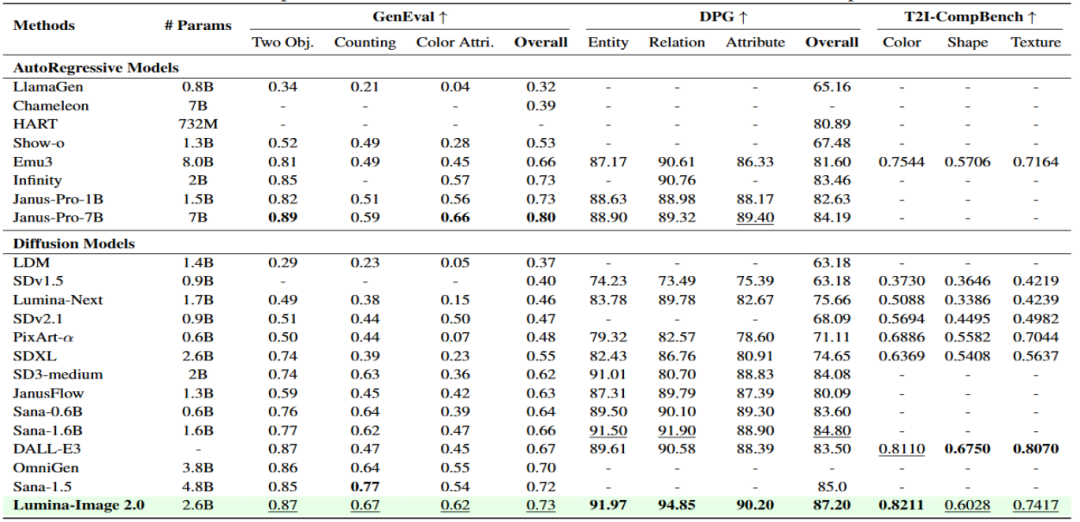
三、模型技术架构
Lumina-Image 2.0是一个基于扩散变换器(diffusion transformer)的先进图像生成模型,其参数量为26亿;这一模型的核心架构包含了以下几个至关重要的组件:
1、文本编码器
Lumina-Image 2.0选用了Gemma-2B作为文本编码器,这一组件能够高效地将用户输入的文本描述转换为模型可以理解和处理的向量表示。Gemma-2B是谷歌开源的一个小型LLM模型,具有强大的语言理解和特征提取能力。它能够深入分析文本中的语义信息、情感倾向、关键特征等内容,并将这些信息转化为紧凑且富有表现力的向量,为后续的图像生成过程提供准确的文本语义指导。
2、VAE(变分自编码器)
模型采用了FLUX-VAE-16CH作为图像的编码和解码器,在图像生成过程中发挥着关键作用。VAE能够有效地对图像进行编码,将高维的图像数据压缩为低维的特征向量,同时保留图像的关键细节和纹理信息。在解码阶段,它又能够根据这些特征向量,准确地还原出高质量的图像。FLUX-VAE-16CH的16通道设计,为图像的特征提取和表示提供了更丰富的信息维度,使得生成的图像在细节和纹理表现上更加细腻、逼真。
3、扩散模型
扩散模型是Lumina-Image 2.0的核心部分,它通过逐步去除噪声的方式来生成图像。具体来说,扩散模型首先在初始阶段向图像中添加大量的噪声,然后通过一系列的迭代步骤,逐渐去除这些噪声,使得图像从噪声状态逐渐转变为清晰、真实的目标图像。在这个过程中,模型通过学习大量的图像数据,掌握了图像的统计规律和特征分布,从而能够在去噪过程中生成符合真实图像特征的结果。扩散模型的这种生成方式,使得Lumina-Image 2.0能够生成多样性高、质量优秀的图像。

四、模型功能特点
1、高分辨率图像生成
Lumina-Image 2.0支持1024分辨率的图像生成,从官方给出的demo以及实际生成的图像来看,其生成的图像质量表现堪称卓越。无论是细腻入微的纹理、丰富多彩的色彩,还是清晰锐利的细节,都能给人带来强烈的视觉震撼。在高分辨率图像的生成过程中,模型能够充分利用其强大的技术架构和丰富的训练数据,精准地还原出每一个细节,使得生成的图像在视觉效果上与真实图像几乎无异。这一特性使得Lumina-Image 2.0在对图像质量要求极高的领域,如广告设计、影视制作、游戏开发等,具有广阔的应用前景。
例如,在广告设计中,设计师可以利用Lumina-Image 2.0快速生成高分辨率的产品宣传图片,为广告创意提供更多的可能性,提升广告的视觉吸引力和传播效果;在影视制作中,它可以用于生成逼真的场景概念图、角色设计图等,为影视创作提供前期的创意支持;在游戏开发中,能够帮助开发者快速生成高质量的游戏场景和角色模型,提高游戏的开发效率和品质。
2、多语言支持
该模型支持中英双语,这主要得益于其采用的2B的Gemma-2B文本编码器。Gemma-2B作为谷歌开源的一个小LLM模型,本身就具备强大的多语言支持能力,为Lumina-Image 2.0的多语言功能奠定了坚实的基础。这一特性使得全球不同语言背景的用户都能方便地使用Lumina-Image 2.0进行图像生成。
比如,中国的创作者可以用中文描述自己的创意和需求,让模型生成符合预期的图像;而国外的开发者也可以用英文与模型进行交互,实现自己的创作想法。多语言支持功能极大地拓展了Lumina-Image 2.0的用户群体和应用范围,使其能够在全球范围内得到更广泛的应用和推广。
3、多图生成能力
Lumina-Image 2.0还支持尚未完全公开的多图生成能力,这一功能进一步拓展了其应用范围。在一些需要批量生成图像的场景中,如电商平台的商品展示图制作、漫画创作等,多图生成能力可以大大提高工作效率。
例如,电商商家可以一次性生成多个不同角度、不同风格的商品展示图,满足线上销售对于多样化图像展示的需求,吸引更多的消费者;在漫画创作中,创作者可以利用这一功能快速生成多个漫画分镜图,为漫画创作提供更多的素材和创意灵感,加快漫画的创作进度。
五、模型适用场景
Lumina-Image 2.0凭借其强大的功能和出色的性能,在多个领域都有着广泛的应用前景,包括但不限于以下几个方面:
1、创意设计
艺术家和设计师可以利用Lumina-Image 2.0快速生成创意草图和设计概念。在设计过程中,他们只需输入简短的文本描述,模型就能迅速生成一系列具有创意的设计方案,为设计师提供丰富的灵感来源。设计师可以在此基础上进行筛选和优化,大大缩短了设计周期,提高了设计效率。
2、广告与营销
广告公司可以使用该模型生成吸引人的广告图像。通过输入广告主题、产品特点、目标受众等文本信息,模型能够生成符合广告需求的高质量图像,帮助广告公司更好地传达广告信息,吸引消费者的注意力,提升广告的效果和影响力。
3、游戏开发
游戏开发者可以利用Lumina-Image 2.0生成游戏场景和角色设计。在游戏开发的前期阶段,开发者可以通过模型快速生成各种游戏场景的概念图和角色设计图,为游戏的美术风格和剧情设定提供参考。这不仅能够加快游戏的开发进度,还能为游戏带来独特的视觉风格和艺术魅力。
六、模型使用方法
1、环境准备
在使用Lumina-Image 2.0之前,需要先搭建好必要的依赖环境,以下是详细的安装步骤:
1)创建Conda环境并安装PyTorch:
conda create -n Lumina2 -yconda activate Lumina2conda install python=3.11 pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia -y
这一步骤的作用是创建一个名为Lumina2的Conda环境,并在该环境中安装指定版本的Python、PyTorch及其相关的视觉和音频处理库,为后续的模型运行提供基础的软件环境。
2)安装依赖:
pip install -r requirements.txt通过运行这一命令,系统会自动安装模型运行所需的其他依赖库,确保模型能够正常运行。requirements.txt文件中包含了所有依赖库的名称和版本信息,系统会根据这些信息从Python Package Index(PyPI)等软件源中下载并安装相应的库。
3)安装Flash-Attn:
pip install flash-attn --no-build-isolationFlash-Attn是一种高效的注意力机制实现,能够显著提高模型的计算效率。安装Flash-Attn可以进一步提升Lumina-Image 2.0的运行速度,使其在处理大规模数据时更加高效。
2、数据准备
数据格式应为包含图像路径和描述的JSON文件,例如:
{"image_path": "path/to/your/image","prompt": "a description of the image"}
在这个JSON文件中,“image_path”字段指定了图像的存储路径,“prompt”字段则包含了对该图像的文本描述。模型在训练和微调过程中,会根据这些数据进行学习和优化,以提高生成图像的质量和准确性。
3、微调(Fine-Tuning)
准备好数据后,可以通过运行脚本进行微调:
bash scripts/run_1024_finetune.sh微调是指在预训练模型的基础上,使用特定的数据集对模型进行进一步的训练,以使其更好地适应特定的任务和数据分布。通过微调,可以显著提高模型在特定任务上的性能表现,使其生成的图像更加符合用户的需求。
4、模型权重文件下载
在进行推理之前,用户需要下载相应的权重文件。权重文件支持.pth格式,用户可以从Google Drive(https://drive.google.com/drive/folders/1LQLh9CJwN3GOkS3unrqI0K_q9nbmqwBh?usp=drive_link)或Hugging Face(https://huggingface.co/Alpha-VLLM/Lumina-Image-2.0/tree/main)进行下载。在使用Hugging Face下载时,用户只需在运行推理代码时指定`–ckpt`参数为下载目录即可,操作十分便捷。权重文件包含了模型在训练过程中学习到的参数信息,是模型进行推理和生成图像的关键。
5、Gradio界面推理
用户可以通过运行以下命令启动Gradio Demo:
python demo.py \--ckpt /path/to/your/ckpt \--res 1024 \--port 12123
其中,`–ckpt`参数指定权重文件的路径,`–res`参数指定图像的分辨率,`–port`参数指定服务的端口号。通过Gradio Demo,用户可以在浏览器中直观地与模型进行交互,输入文本描述,实时查看生成的图像,方便快捷地体验Lumina-Image 2.0的强大功能。Gradio提供了一个简单易用的图形界面,使得即使没有专业编程知识的用户也能够轻松使用模型进行图像生成。
6、批量推理
用户也可以通过运行以下命令进行直接批量推理:
bash scripts/sample.sh这种推理方式适用于需要批量生成图像的场景,用户可以将多个文本描述整理成一个批次,一次性输入到模型中,快速获得多个生成图像,大大提高了工作效率。批量推理功能在处理大规模数据时具有显著的优势,能够节省大量的时间和人力成本。
七、总结与展望
Lumina-Image 2.0作为一款新兴的文生图模型,凭借其出色的文本跟随能力、丰富多样的功能特性、先进的技术架构以及便捷的使用方式,在图像生成领域展现出了巨大的潜力和广阔的发展前景。尽管目前它在某些方面可能还存在一些不足之处,比如与一些更大型的模型相比,在生成图像的某些细节和复杂场景的处理上可能还有提升的空间,但考虑到其相对较小的参数量,已经取得了相当不错的成绩。
展望未来,随着人工智能技术的不断发展和优化,相信Lumina-Image 2.0会在图像生成质量、速度以及功能拓展等方面取得更大的突破。同时,也期待更多基于Lumina-Image 2.0的应用和创新能够不断涌现,为广告、影视、游戏、教育等众多行业带来更多的惊喜和变革,推动图像生成技术在实际应用中的广泛普及和深入发展,为人类的生产和生活带来更多的便利和价值。
八、项目地址
仓库地址:https://github.com/Alpha-VLLM/Lumina-Image-2.0
模型地址:https://huggingface.co/Alpha-VLLM/Lumina-Image-2.0/tree/main
(文:小兵的AI视界)