

随着人工智能技术的飞速发展,大语言模型已成为推动智能化应用的关键力量。DeepSeek-R1-Distill-Qwen-7B 作为一款高性能的蒸馏模型,不仅继承了大模型的强大推理能力,还通过优化大幅降低了部署成本。本文将手把手教你如何基于该模型搭建一个支持 128K 上下文、可视化思考过程的 Streamlit 聊天机器人,为用户提供智能且交互性强的体验。无论你是 AI 初学者还是技术爱好者,都能通过本文的详细指导轻松上手!
一、环境准备
1、服务器配置
为实现DeepSeek-R1-Distill-Qwen 模型的高效部署,推荐采用 Ubuntu 22.04 LTS 操作系统,搭配 Python 3.12 环境、CUDA 12.1 以及 PyTorch 2.3.0。同时,配备至少 24GB 显存的 NVIDIA GPU 是必不可少的,这将确保模型在推理过程中能够保持高性能与稳定性,犹如为模型的运行提供了强劲的动力引擎。
2、安装依赖包
# 升级pip并配置清华源python -m pip install --upgrade pippip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple# 安装核心依赖pip install transformers==4.48.2pip install accelerate==1.3.0pip install modelscope==1.22.3pip install streamlit==1.41.1
先把pip 升级到最新版,这样能用上 pip 的新功能,安装东西更稳定。然后把 pip 下载源改成清华大学的镜像源,下载速度能快很多。接着就可以安装这几个重要的库:transformers用来加载和使用模型;accelerate能让模型训练和运行更快;modelscope帮你下载和管理模型;streamlit用来做和用户互动的界面。
三、下载模型文件
这里我们使用python代码下载模型文件:
from modelscope import snapshot_download# 注意修改为您的实际存储路径model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B',cache_dir='/root/autodl-tmp', # 自定义路径revision='master')
这段代码用modelscope库的snapshot_download函数下载模型。deepseek-ai/DeepSeek-R1-Distill-Qwen-7B是模型在平台上的名字,cache_dir是你要把模型存到哪里,你可以自己改,revision=’master’表示下最新版本。
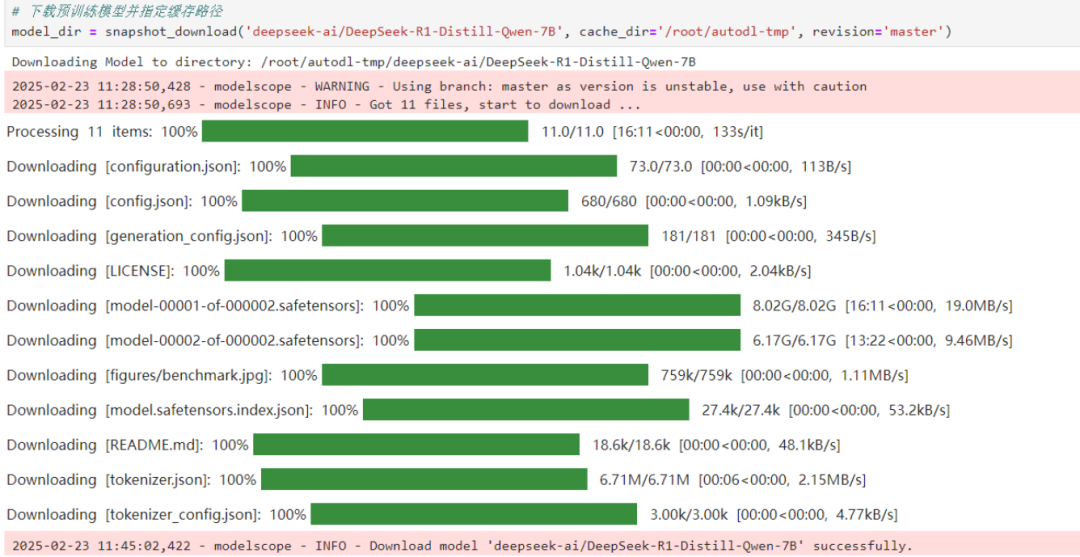
下载的时候,网络要稳定,存储路径别写错,不然就下不了。代码写好后,直接执行,模型就开始下载了,下载时间要看网速。
注意:也可以直接将上面代码封装到python文件中(例如:download.py)直接执行python download.py即可。
三、聊天机器人核心代码
核心代码实现示例,新建chat_test.py文件,该文件包含以下功能模块:
步骤1:导入必要的库
from transformers import AutoTokenizer, AutoModelForCausalLMimport torchimport streamlit as stimport re
步骤2:配置 Streamlit 界面
with st.sidebar:st.markdown("## DeepSeek-R1-Distill-Qwen-7B LLM")# 创建一个滑块,用于选择最大长度,范围在 0 到 8192 之间,默认值为 8192(DeepSeek-R1-Distill-Qwen-7B 支持 128K 上下文,并能生成最多 8K tokens,我们推荐设为 8192,因为思考需要输出更多的Token数)max_length = st.slider("max_length", 0, 8192, 8192, step=1)# 创建一个标题st.title("DeepSeek R1 聊天机器人")
步骤3:定义模型路径和文本分割函数
# 定义模型路径mode_name_or_path = '/root/autodl-tmp/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B'# 文本分割函数def split_text(text):pattern = re.compile(r'<think>(.*?)</think>(.*)', re.DOTALL) # 定义正则表达式模式match = pattern.search(text) # 匹配 <think>思考过程</think>回答if match: # 如果匹配到思考过程think_content = match.group(1).strip() # 获取思考过程answer_content = match.group(2).strip() # 获取回答else:think_content = "" # 如果没有匹配到思考过程,则设置为空字符串answer_content = text.strip() # 直接返回回答return think_content, answer_content
步骤4:加载模型和 tokenizer
@st.cache_resourcedef get_model():# 从预训练的模型中获取 tokenizertokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_token# 从预训练的模型中获取模型,并设置模型参数model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16, device_map="auto")return tokenizer, model# 加载 Qwen2.5 的 model 和 tokenizertokenizer, model = get_model()
步骤5:初始化对话历史并显示历史消息
# 如果 session_state 中没有 "messages",则创建一个包含默认消息的列表if "messages" not in st.session_state:st.session_state["messages"] = [{"role": "assistant", "content": "有什么可以帮您的?"}]# 遍历 session_state 中的所有消息,并显示在聊天界面上for msg in st.session_state.messages:st.chat_message(msg["role"]).write(msg["content"])
步骤6:处理用户输入并生成响应
# 如果用户在聊天输入框中输入了内容,则执行以下操作if prompt := st.chat_input():# 在聊天界面上显示用户的输入st.chat_message("user").write(prompt)# 将用户输入添加到 session_state 中的 messages 列表中st.session_state.messages.append({"role": "user", "content": prompt})# 将对话输入模型,获得返回input_ids = tokenizer.apply_chat_template(st.session_state.messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=max_length)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]think_content, answer_content = split_text(response) # 调用split_text函数,分割思考过程和回答# 将模型的输出添加到 session_state 中的 messages 列表中st.session_state.messages.append({"role": "assistant", "content": response})# 在聊天界面上显示模型的输出with st.expander("模型思考过程"):st.write(think_content) # 展示模型思考过程st.chat_message("assistant").write(answer_content) # 输出模型回答# print(st.session_state) # 打印 session_state 调试
四、服务部署启动
streamlit run chat_test.py --server.address 127.0.0.1 --server.port 6006–server.address 127.0.0.1指定服务的地址为本地回环地址,
–server.port 6006指定服务的端口为 6006。

访问http://localhost:6006/即可体验:
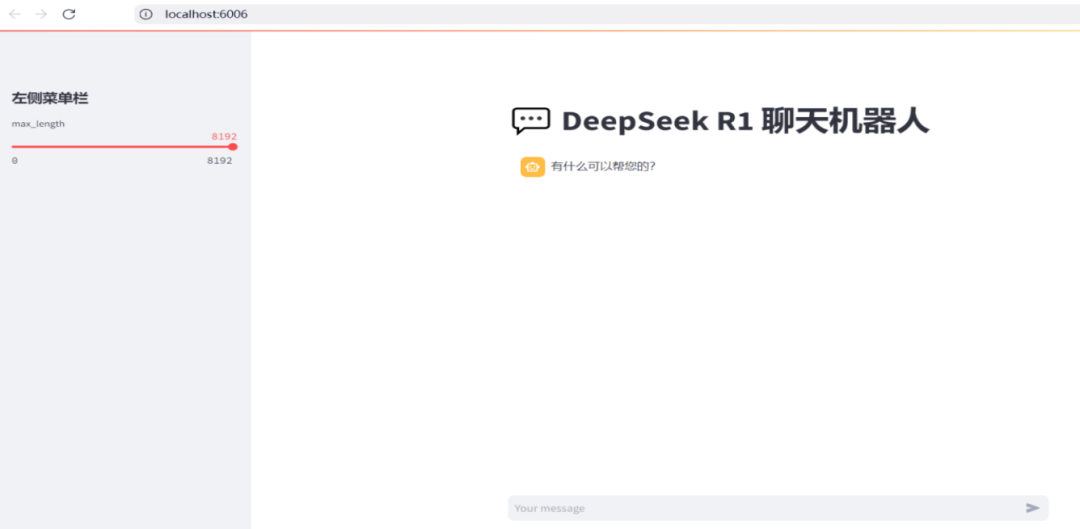
五、对话聊天测试
在浏览器中访问http://localhost:6006/,即可打开聊天机器人的界面,与机器人进行交互。界面中展示了对话的输入框和输出区域,用户可以在输入框中输入问题,聊天机器人将在输出区域返回回答。
1、第一轮对话测试
提示词:你是谁?
模型回复:
“`
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。</think>
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
“`
2、第二轮对话测试
提示词:一个篮子里有5个苹果,你拿走了3个,篮子里还剩几个苹果?
模型回复:
“`
好,我现在要解决的问题是:一个篮子里有5个苹果,你拿走了3个,篮子里还剩几个苹果?
首先,我需要理解问题。问题描述了一个篮子中有5个苹果,然后拿走了3个,问剩下的苹果数量。
接下来,我应该进行计算。总共有5个苹果,拿走了3个,那么剩下的苹果数应该是5减去3,也就是2个。
为了确保计算的正确性,我可以使用减法的基本原理来验证。减法是数学中的基本运算,表示从一个数量中减去另一个数量。在这个问题中,5个苹果减去3个苹果,结果应该是2个苹果。
另外,我也可以通过实际操作来验证。如果我有一个装有5个苹果的篮子,我拿出3个苹果,剩下的苹果数就是5减去3,等于2个。
因此,经过计算和验证,篮子里还剩下2个苹果。</think>
一个篮子里有5个苹果,你拿走了3个,篮子里还剩2个苹果。
“`
五、功能亮点
1、支持8192 tokens 超长上下文:能够理解和处理用户输入的长文本内容,为用户提供更加准确和全面的回答,适用于各种复杂的对话场景。
2、可视化模型思考过程:通过split_text函数对模型输出进行解析,将模型的思考过程直观地展示给用户,增强了用户对模型推理的理解和信任。
3、响应内容实时流式输出:在聊天机器人处理用户请求时,响应内容将实时流式输出,让用户能够更快地看到回答的部分内容,提高交互体验。
六、注意事项
1、确保显存容量≥16GB:DeepSeek-R1-Distill-Qwen-7B 模型在运行过程中需要占用一定的显存,为了保证模型能够正常运行,避免出现显存不足的错误,建议确保显存容量≥16GB。
2、首次运行需下载约15GB 模型文件:由于模型文件较大,首次运行时需要下载约 15GB 的模型文件,这可能需要一定的时间,具体时间取决于网络速度。请确保在下载过程中有稳定的网络连接。
总结
通过以上步骤,你已经成功搭建了基于DeepSeek-R1-Distill-Qwen-7B 大模型的 Streamlit 聊天机器人。在实际使用过程中,你可以根据自己的需求对代码进行进一步优化和扩展,例如添加更多的功能模块、优化界面设计等。如果你在部署过程中遇到任何问题,可参考本文的步骤和注意事项,也可以查阅相关文档或寻求社区的帮助。希望你能在这个项目中充分发挥自己的创造力,探索大语言模型在聊天机器人领域的更多应用可能。
(文:小兵的AI视界)