
HeadInfer 是一个内存高效的推理框架,专为大型语言模型(LLMs)设计,通过采用逐头卸载策略显著减少 GPU 内存消耗。与传统的逐层 KV 缓存卸载不同,HeadInfer 动态管理注意力头,仅在 GPU 上保留一部分 KV 缓存,同时将剩余部分卸载到 CPU 内存中。
使用 HeadInfer,一个 8B 模型可以在单张消费级 GPU(例如,24GB VRAM 的 RTX 4090)上处理多达 400 万个 token,将 GPU KV 缓存内存从 128GB 减少到仅 1GB,且无需近似计算。
主要特性,如下所示:
-
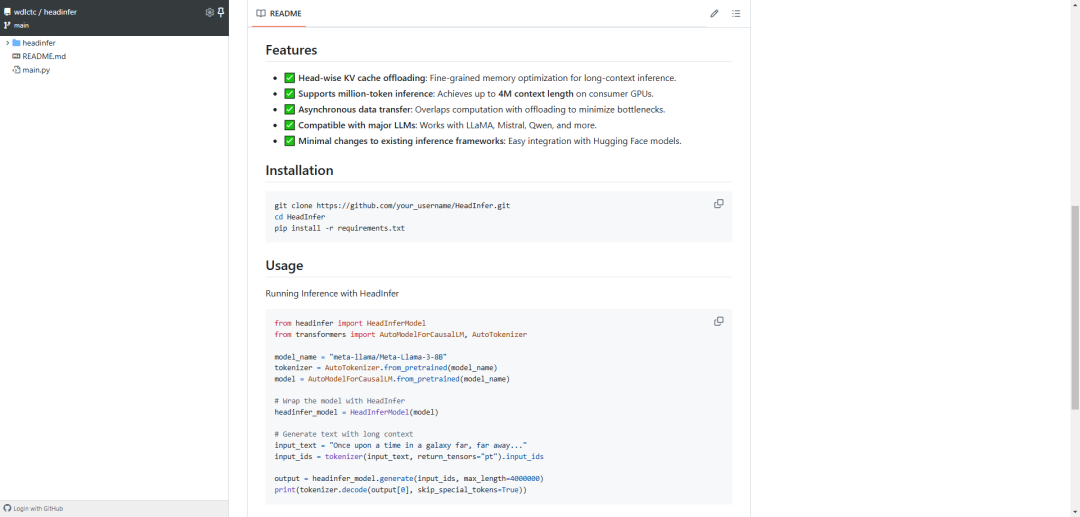
逐头 KV 缓存卸载:为长上下文推理提供细粒度的内存优化。 -
支持百万级 token 推理:在消费级 GPU 上实现高达 400 万上下文长度。 -
异步数据传输:通过重叠计算与卸载,最小化瓶颈。 -
兼容主流 LLMs:支持 LLaMA、Mistral、Qwen 等模型。 -
对现有推理框架改动最小:轻松集成 Hugging Face 模型。
参考文献:
[1] https://github.com/wdlctc/headinfer
(文:NLP工程化)