

-
• DeepSeek 开源周发布 5 个生产验证仓库和 V3/R1 推理系统,展示高效 AI 基础设施。 -
• V3/R1 推理系统通过跨节点 EP、计算通信重叠和负载均衡,实现 73.7k/14.8k token/s 吞吐量。 -
• 成本利润率 545%,FP8 和 3FS 等创新突破硬件限制,推动社区 AGI 进步。 -
用 H800 GPU 跑出 1350 TFLOPS,一个小团队如何用开源代码掀起 AI 革命?2025 年 2 月,DeepSeek 用一场“开源周”给出了答案:5 天 5 个生产级项目,外加 V3/R1 推理系统的完整揭秘。从 6.6 TiB/s 的文件系统到 545% 的成本利润率,他们不仅挑战了硬件至上的行业信条,还将全部成果无私分享给社区。这背后,是算法优化的极致追求,也是对开源力量的坚定信仰。让我们走进这场技术狂欢,看 DeepSeek 如何用“受限硬件”撬动 AI 未来。
开源周:从代码到社区的技术狂欢
2025 年 2 月 24 日,DeepSeek 启动了一场别开生面的开源周:5 天内每天发布一个生产验证的代码仓库,第 6 天献上 V3/R1 推理系统全貌。这不是营销噱头,而是带着“garage-energy”精神的代码盛宴。每个项目都经过在线服务实战打磨,以透明姿态推动社区 AGI 探索。正如 DeepSeek 所言:“每行共享的代码,都是集体前行的动能。”这场活动,是技术与协作的完美碰撞。
开源项目的硬核实力
FlashMLA:H800 上 3000 GB/s 的高效解码
FlashMLA 是开源周的首发明星,一个针对 H800 GPU 优化的 MLA 解码内核。支持 BF16 和分页 KV 缓存(块大小 64),它实现 3000 GB/s 内存带宽和 580 TFLOPS 计算能力,轻松应对变长序列,已在生产环境中大放异彩。
DeepEP:MoE 通信的革命性优化
DeepEP 是全球首款支持 MoE 专家并行的通信库,利用 NVLink 和 RDMA 优化节点内和节点间通信。支持 FP8 的高吞吐量训练内核和低延迟推理内核,加上灵活的计算通信重叠,让它成为 V3/R1 的通信基石。
DeepGEMM:FP8 计算的极致效率
DeepGEMM 用 300 行核心代码,撑起 FP8 GEMM 库的惊人性能:在 H800 上达 1350+ TFLOPS,覆盖稠密和 MoE 计算。JIT 编译适配各种矩阵规模,干净得像教学代码,却碾压专家调优内核。
并行策略:DualPipe 和 EPLB 的训练突破
DualPipe 通过双向流水并行实现计算通信重叠,EPLB 则用专家并行负载均衡优化资源分配。这对组合拳大幅提升了 V3/R1 训练效率,让大规模 MoE 模型更易驾驭。
3FS:6.6 TiB/s 的数据加速器
3FS(Fire-Flyer 文件系统)是数据处理的核武器:180 节点集群达 6.6 TiB/s 聚合读吞吐量,25 节点 GraySort 基准测试 3.66 TiB/min,单客户端峰值超 40 GiB/s。解耦架构和强一致性,支持训练预处理到推理 KV 缓存的全流程。
V3/R1 推理系统:效率与性能的巅峰
设计原则:高吞吐量与低延迟的双赢
V3/R1 推理系统追求极致效率,核心在于跨节点专家并行(EP)。EP 放大批量提升 GPU 计算效率,同时分散专家降低内存需求,为高稀疏性 MoE 模型量身定制。
跨节点 EP:大批量下的稀疏优化
V3/R1 每层 256 个专家,仅激活 8 个,DeepSeek 用预填充 EP32/DP32(4 节点)和解码 EP144/DP144(18 节点)应对。每 GPU 在预填充处理 9 个路由专家和 1 个共享专家,解码减至 2 个,确保资源高效分配。
计算通信重叠:隐藏开销的艺术
跨节点 EP 的通信开销被双批次和流水线巧妙化解。预填充阶段,双微批次交替执行,通信隐藏于计算后;解码阶段,注意力层拆成两步,5 阶段流水线无缝衔接:
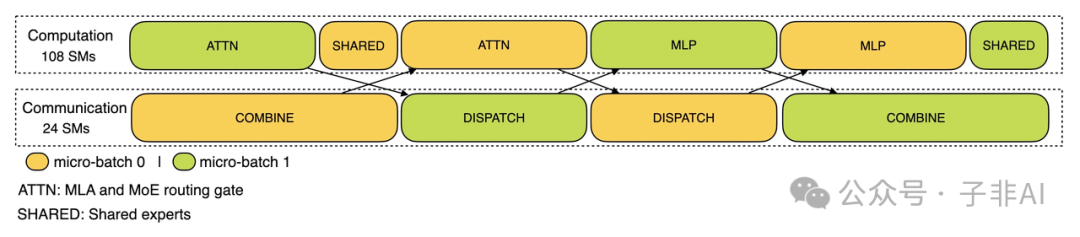
预填充阶段的双批次策略,通信成本几近无感
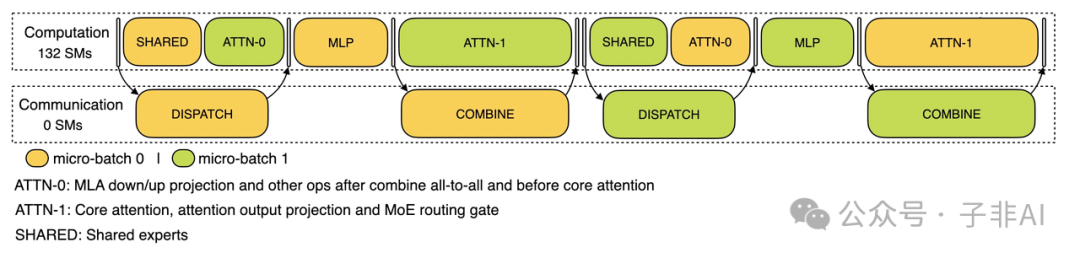
解码阶段的 5 阶段流水线,提升效率的关键
负载均衡:多节点并行的关键
三重负载均衡化解并行瓶颈:预填充平衡核心计算和输入 token,解码均衡 KV 缓存与请求数,专家均衡最小化高负载专家开销,确保系统整体高效。
系统架构图解析
下图展示 V3/R1 在线推理全流程,EP 和负载均衡的协同一览无余:
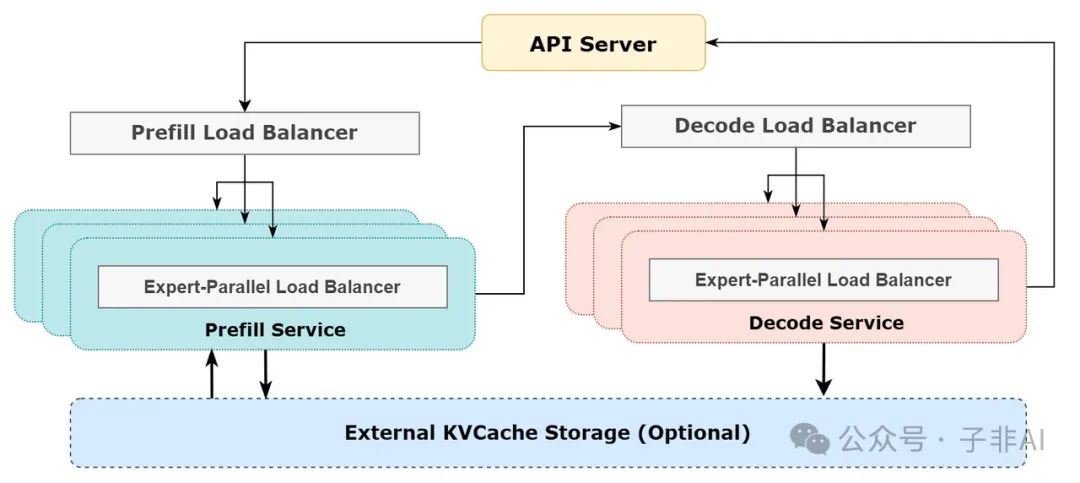
从输入到输出,EP 如何驱动高效推理
数据说话:545% 利润率背后的秘密
在线服务性能:73.7k/14.8k token/s 的惊人吞吐量
V3/R1 运行于 H800 GPU,FP8 处理矩阵乘法和分派,BF16 用于核心 MLA 计算。每节点预填充吞吐量 73.7k token/s,解码 14.8k token/s。24 小时(2025 年 2 月 27-28 日)处理输入 608B token(56.3% 命中 KV 缓存),输出 168B token,平均速度 20-22 token/s。
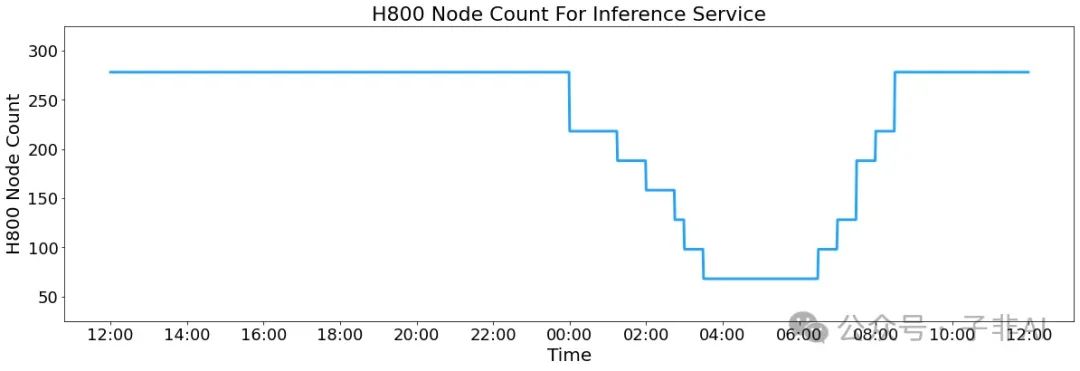
节点占用波动,反映昼夜负载优化
经济性分析:每日成本 vs 理论收入
峰值 278 个节点,平均 226.75 个,每日成本 562,027,成本利润率 545%。但因免费服务和夜间折扣,实际收入仅为理论值的约 30%-40%。
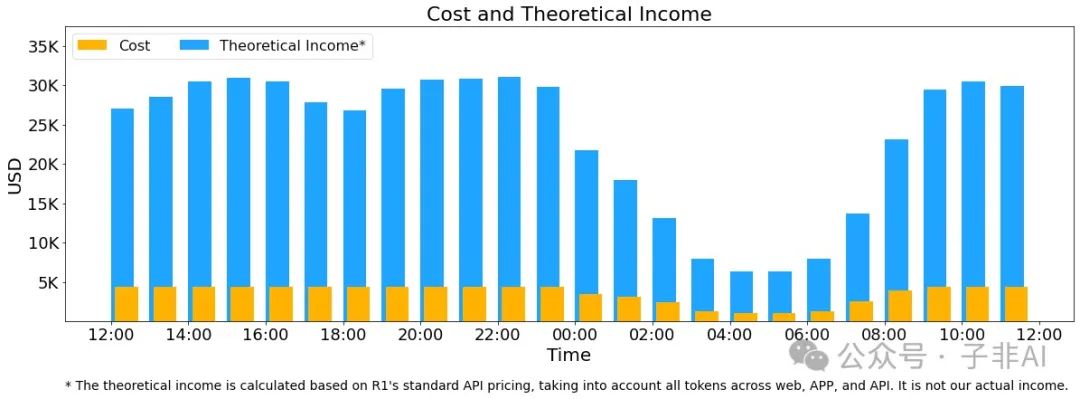
成本与收入对比,545% 利润率的惊人潜力
过渡:数字背后的反常识启示
这些数字不仅展示性能,更隐藏着颠覆认知的洞见:硬件受限为何能跑出奇迹?开源如何挑战闭源霸权?
硬件劣势如何变优势
受限硬件催生更高效率
AI 圈常认为 H100 是性能天花板,但 DeepSeek 用 H800 跑出 1350+ TFLOPS(DeepGEMM)和 6.6 TiB/s(3FS)。FP8 计算和通信优化释放潜能,证明资源约束倒逼创新,效率突破硬件限制。
开源或成 AI 未来标杆
闭源模型被视为行业标杆,但 DeepSeek 的开源项目以生产级性能(545% 利润率)和透明度挑战这一假设。3FS 和 DeepEP 的成功表明,开源不仅实用,还可能引领 AI 未来。
社区价值与未来展望
DeepSeek 的开源周是技术和社区的双赢。FlashMLA、DeepEP 等项目代码简洁高效,SC24 论文《Fire-Flyer AI-HPC》揭示软硬件协同的成本效益——如如何用 H800 实现 H100 的性能。3FS 的 6.6 TiB/s 吞吐量为数据密集任务注入新动能。这些成果不仅是工具,更是重塑 AI 基础设施的火种。随着社区参与,DeepSeek 的开源革命或将加速 AGI 到来。
推荐阅读
-
• FlashMLA GitHub 仓库:高效 MLA 解码内核源码 – https://github.com/deepseek-ai/FlashMLA -
• DeepEP GitHub 仓库:MoE 通信库详情 – https://github.com/deepseek-ai/DeepEP -
• SC24 论文:Fire-Flyer AI-HPC 成本效益分析 – https://dl.acm.org/doi/10.1109/SC41406.2024.00089 -
• 中文版推理系统概览:DeepSeek-V3/R1 技术细节 – https://zhuanlan.zhihu.com/p/27181462601
(文:子非AI)