


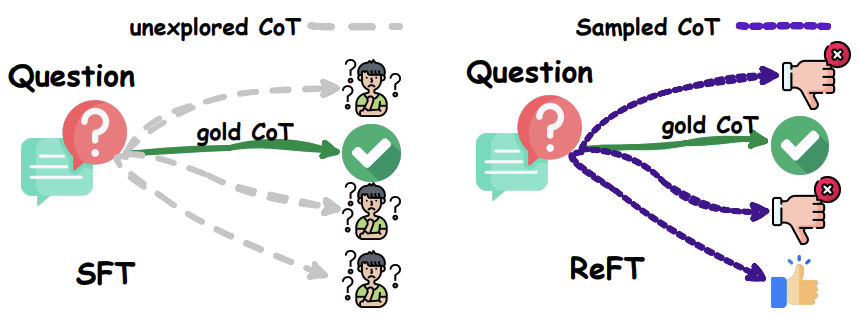
强化微调(RFT)的两个主要阶段:预热阶段和强化学习阶段。

-
预热阶段(Warm-up):
-
在这个阶段,模型使用包含“问题(question)”和“思维链(Chain-of-Thought,CoT)”元组的数据集进行微调,通常持续1-2个epoch。
-
目的是使模型具备基本的问题解决能力,能够生成适当的响应。
-
CoT生成过程被分解为一系列预测下一个词(token)的动作,直到生成结束符(<eos>)。
-
强化学习阶段(Reinforcement Learning):
-
在这个阶段,模型通过在线自我学习的方式提高性能,使用包含“问题(question)”和“答案(answer)”元组的数据集。
-
模型通过重复采样响应、评估响应的答案正确性,并在线更新其参数。
-
使用PPO(Proximal Policy Optimization)算法进行训练,其中价值模型(value model)Vϕ是基于预热阶段后的政策模型πθ的最后隐藏状态构建的。
-
奖励函数在终端状态时直接比较从状态的CoT提取的答案和真实答案y,正确则返回1,否则返回0。对于数值型答案的数据集,还可以应用部分奖励(partial reward)0.1。
-
总奖励是奖励函数得分和学习到的RL政策与初始政策之间的Kullback-Leibler(KL)散度的和。
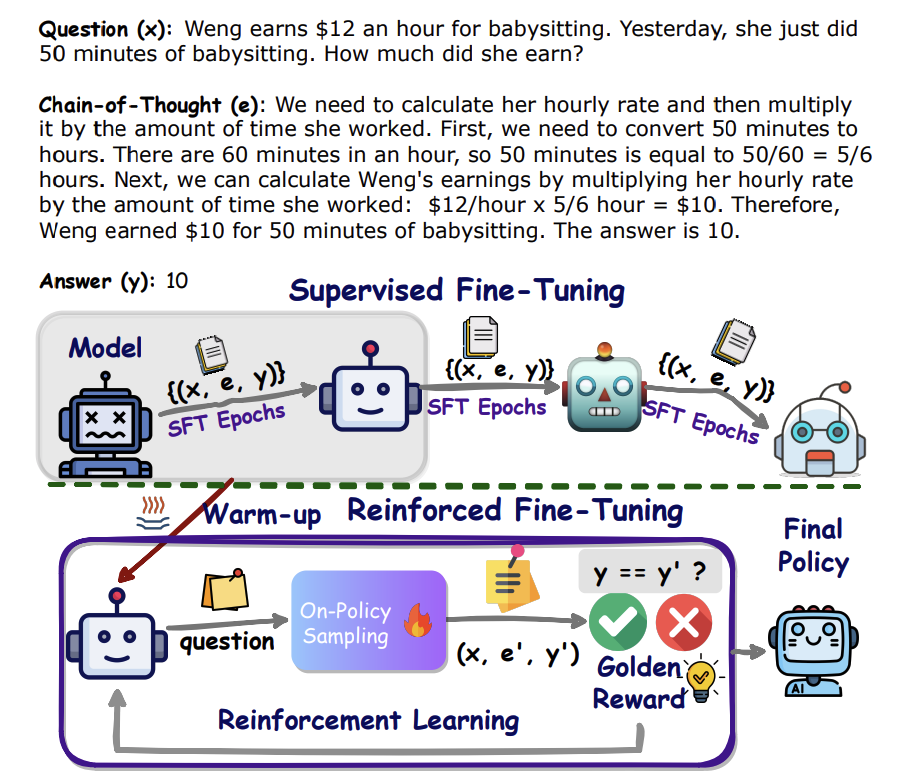
GSM8K中的一个问题(x)、思维链(CoT)(e)和答案(y)的示例。SFT过程在训练数据上迭代多个周期。提出的ReFT从SFT预热并在同一数据上执行RL训练。
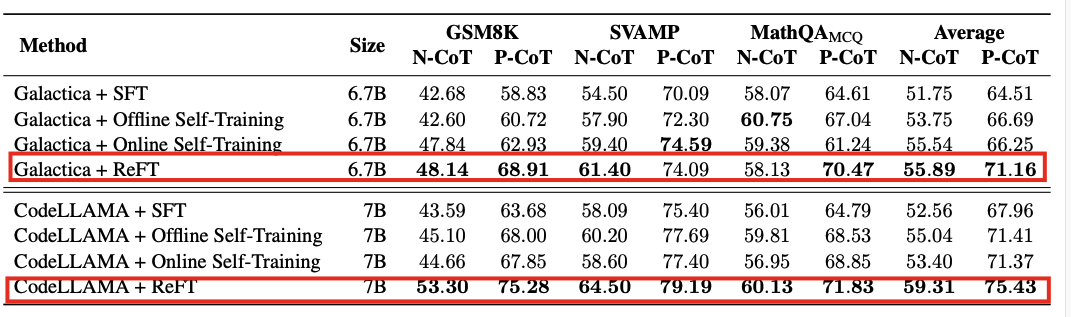
实验表明,RFT在GSM8K、MathQA和SVAMP等数据集上的性能显著优于SFT,并且可以通过多数投票和重新排名等策略进一步提升性能
ReFT和基线模型在所有数据集上微调后的价值准确度
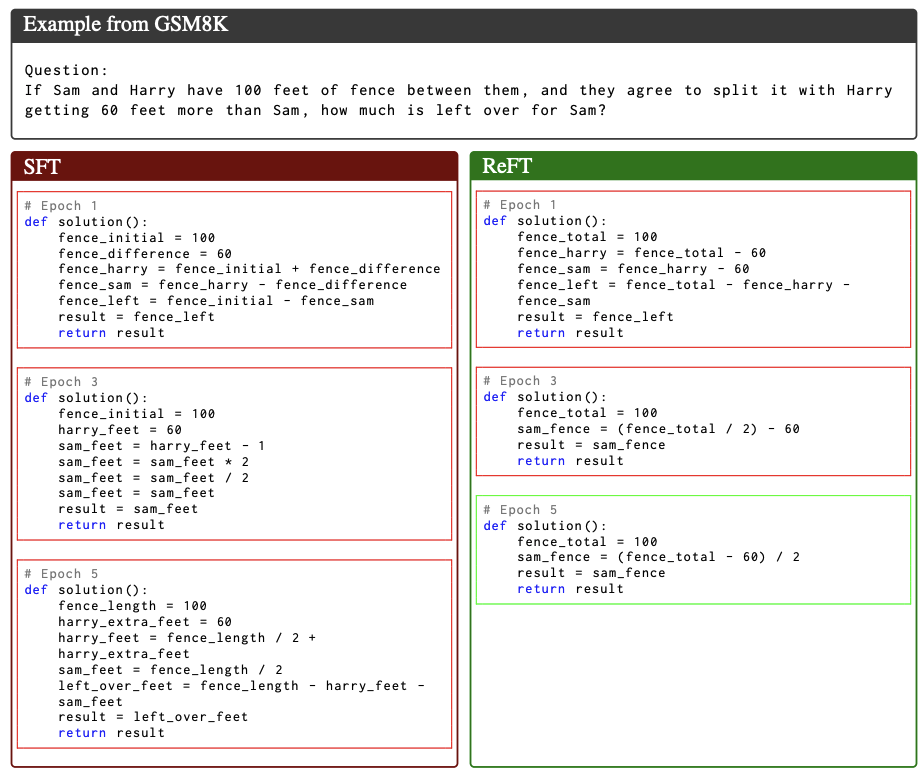
https://arxiv.org/pdf/2401.08967Code: https://github.com/lqtrung1998/mwp_ReFT
(文:PaperAgent)