
DeepMind大佬Vlad Feinberg最近回到普林斯顿做了一场超棒的演讲,演讲的主要内容包括:
-
Scaling Law的历史讨论 -
面对推理限制时,如何调整扩展策略
这次演讲出现了哪些亮点?一起看看看这份PPT的总结:
一、从经典模型开始
-
当前LLM训练面临的挑战在于,每次新实验必须依赖历史实验的外推。
早在2020年,Kaplan等人发现:
-
用小模型的训练数据就能预测大模型表现 -
计算预算增加10倍时,模型参数应该增加5.37倍,数据只要1.86倍 简单说就是:应该更多地投资于扩大模型规模而不是数据规模。
Chinchilla模型对Kaplan的假设提出了挑战:
-
指出通过适当的优化可以实现更好的性能。 -
模型和数据量应以相同速率扩展 -
当计算预算增加10倍时,模型参数和数据量都应该增加大约7倍 这就意味着:给定计算预算下,模型应该更小,训练时间应该更长。
单纯依靠模型规模的改进是否已到达瓶颈?GPT-4.5以及Llama 4 Maverick都曾让人有点慌。实际上,突破点在:更好的神经网络设计以及新数据源的引入。
二、小模型客户
Google很多产品(如Gemini App、AIO、AIM等)需要高吞吐量和实时服务,模型需要在很短的时间内完成推理,这通常意味着需要使用较小的模型。Chinchilla模型扩展法则的一个关键局限性在于,它没有考虑到模型在实际部署时的推理成本。
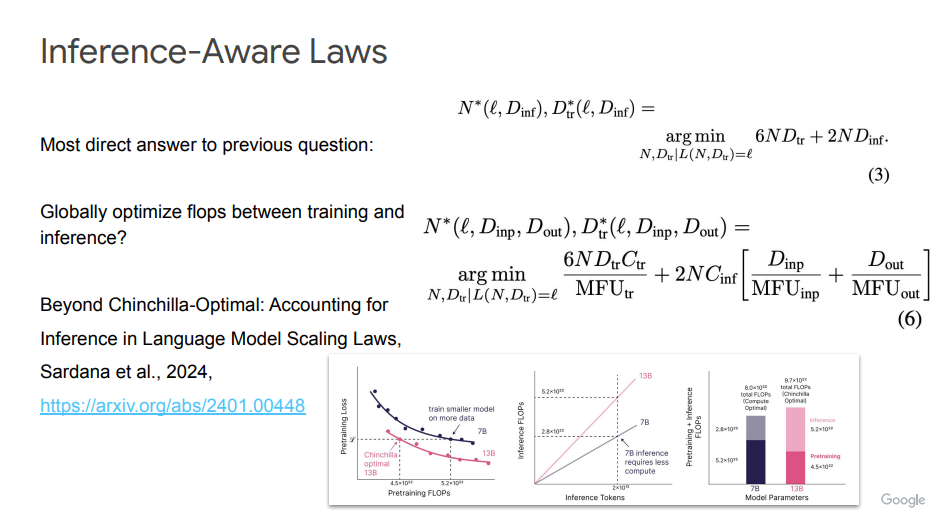
三、推理感知扩展法则(Inference-Aware Scaling Laws)
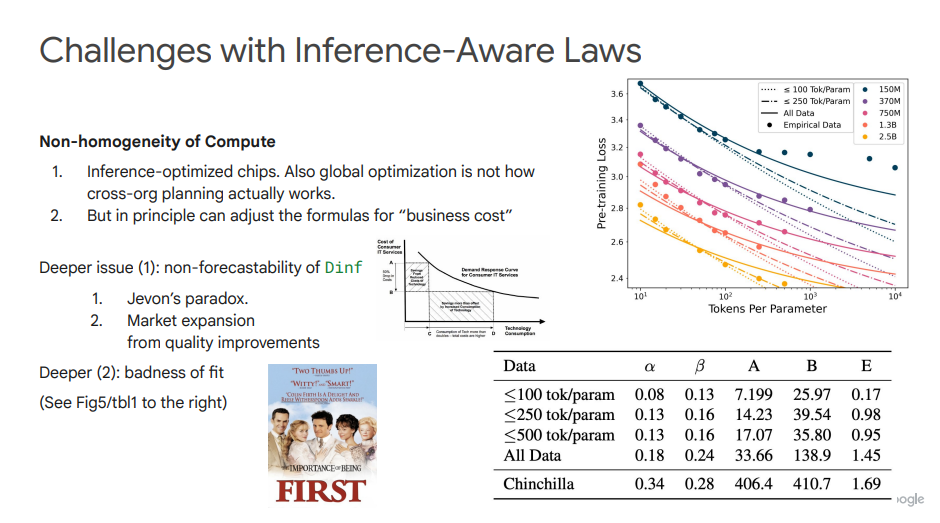
在此基础之上,Sardana等人提出的Inference-Aware Scaling特别关注在模型训练和推理阶段之间平衡计算资源,以实现更高效的模型部署和运行。不过,它也同样面临一些挑战,包括:计算资源的非均匀性、Dinf难以预测、杰文斯悖论、拟合不良等。
在最后,Vlad Feinberg给出了一些未来研究方向的建议:
-
开发硬件专用的内核,或者提出下一代Flash Attention -
量化技术正从向量量化迈向新阶段 -
用Funsearch思路平衡搜索中LLM的推理速度和质量 -
扩展法则是脆弱的,依赖于数据集

参考文献:
[1] https://vladfeinberg.com/2025/04/24/gemini-flash-pretraining.html
[2] https://vladfeinberg.com/assets/2025-04-24-princeton-talk.pdf
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)