
“工欲善其事,必先利其器。”这句话在如今的大模型时代,显得格外有分量。数据,就是驱动模型前进的燃料。谁要是能高效地获取优质训练数据,谁就能在模型微调和落地应用中抢占先机。
以前,我们微调模型的时候,总是被“数据从哪儿来”这个问题难住。真实问答不好找,人工标注又太贵,一份高质量的训练数据集,动辄要花上几周,甚至几个月。
但现在,随着生成式AI的飞速发展,“AI文生数据”成了突破瓶颈的新路子。

今天,我就带大家实测一个爆炸性的流程:用AI自动生成问答训练数据集,提取问题、检查数量、保存文件,全流程只需几分钟,真正实现了“自动生成+自动整理+自动保存”的闭环。

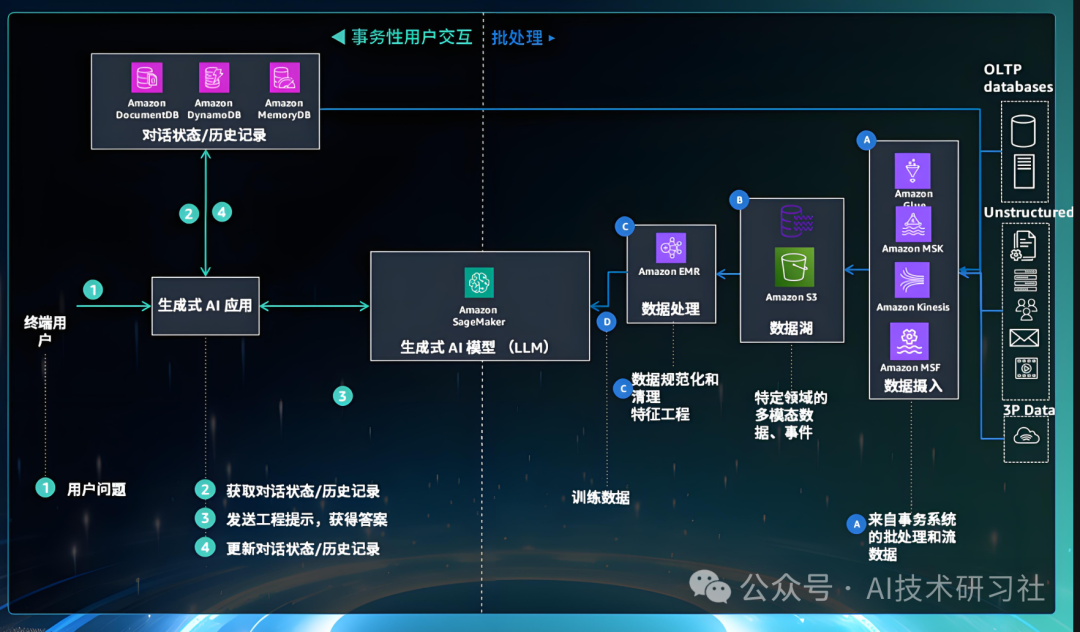
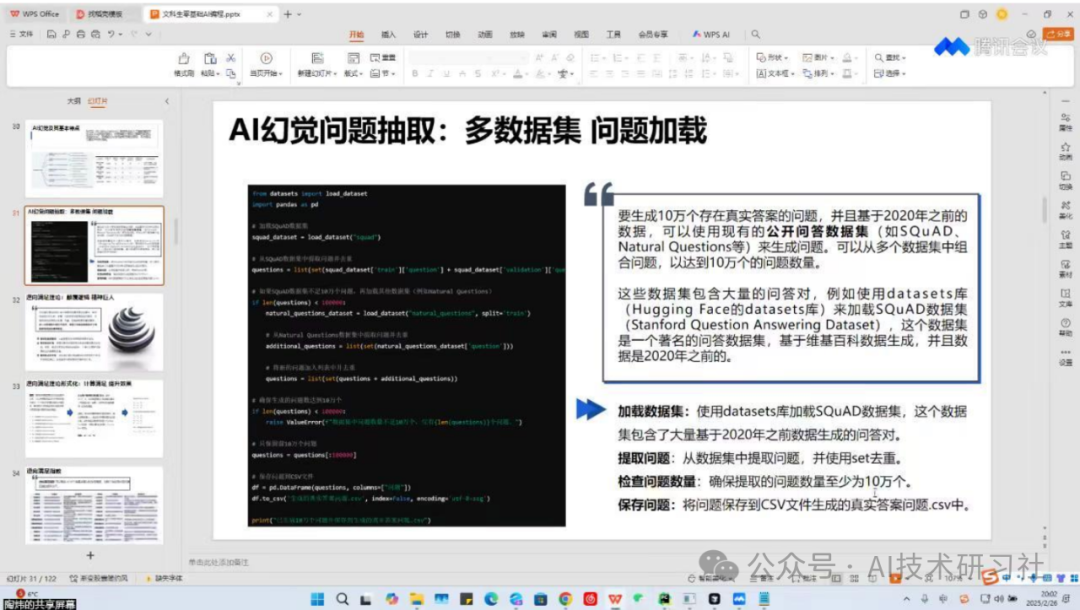
先说说AI文生数据到底能干啥。以RAG(Retrieval-Augmented Generation)系统为例,构建RAG的核心是问答匹配训练,就是要让模型学会“看文档,答问题”。


这可离不开大量的基于文档的高质量问答对。这时候,AI就能大显身手了:
-
它能自动读取文档内容,无论是PDF、TXT还是Markdown格式都不在话下。
-
能自动提出关键问题。
-
能自动检查问题数量,过滤掉重复的或者质量不高的问句。
-
最后还能自动保存成结构化的JSON或CSV文件,直接就能喂给训练pipeline。
整个流程零代码、低门槛,特别适合那些想快速构建自定义训练集的开发者和企业。
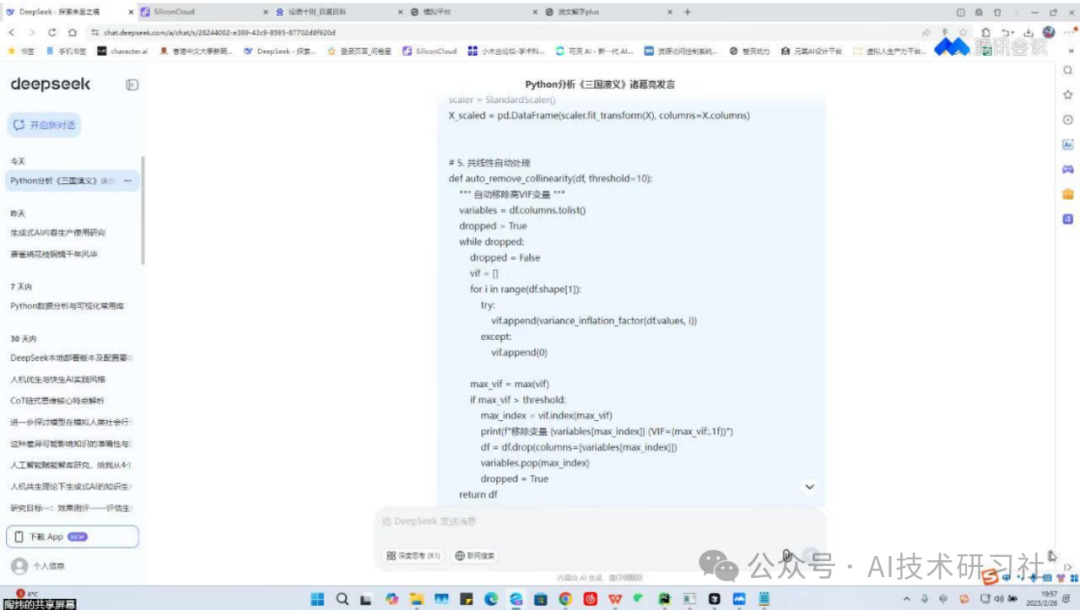
接下来,说说实测的工具。
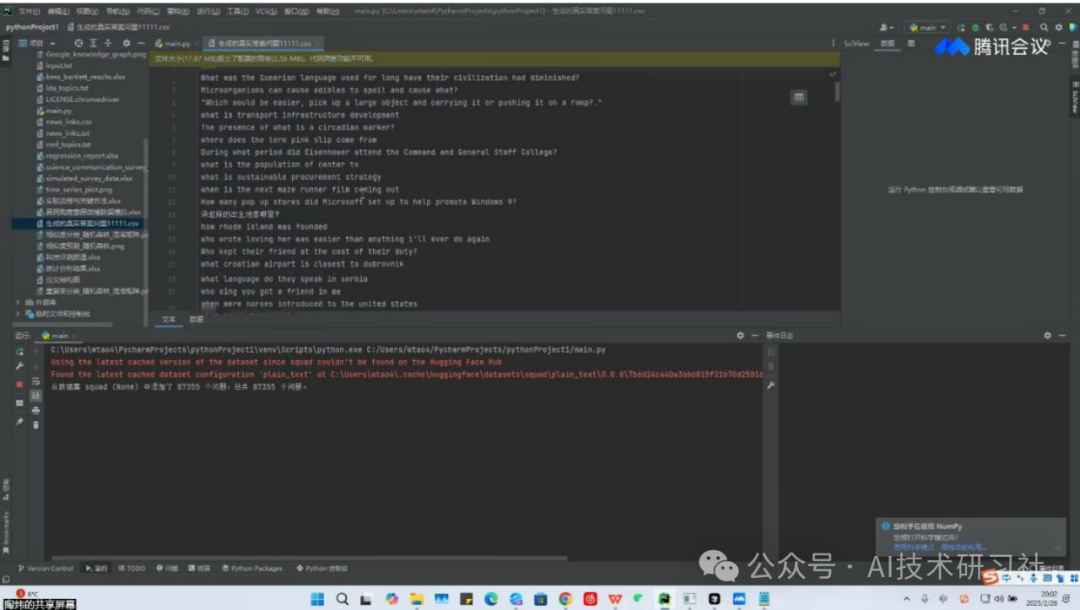
第一步是加载数据集。上传文档后,系统会自动解析内容结构,不仅能提取目录,还能识别段落和重点小节,构建文档嵌入(embedding)索引,方便后续提问。
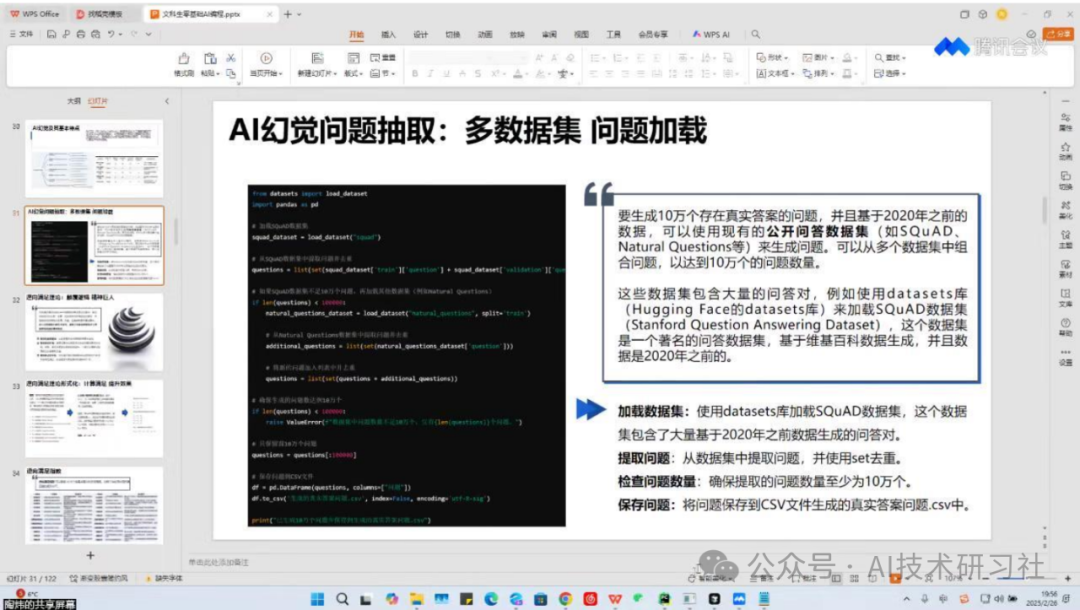
第二步是AI自动提出问题。系统会根据文档内容,生成多个层次的问题,从“标题级”问题(测试大纲理解)到“细节级”问题(测试局部内容掌握),覆盖非常全面。
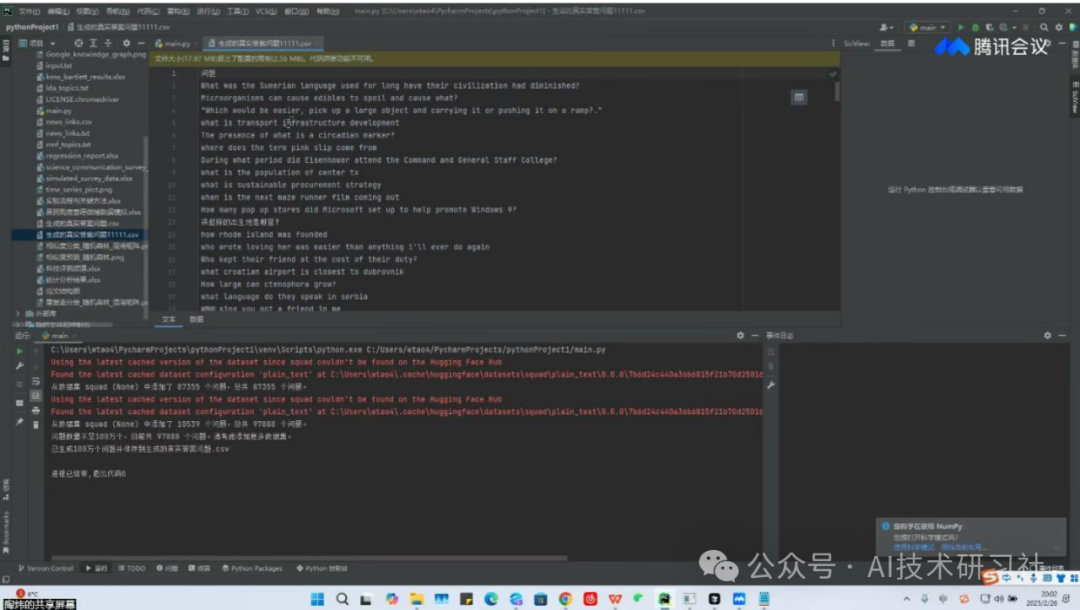
第三步是检查问题数量与质量。自动提问后,我们用内置的“问题审查器”进行批量质检,检查是否重复或过于相似,过滤掉语法错误或无关内容,还能标记不完整的问题供人工微调。
第四步就是保存问答对了。系统支持一键导出为JSON、CSV或Markdown格式,分别适用于训练LLM、数据标注工具和人工审阅优化。实测亮点是,它能自动编号、清洗内容,支持多文档标签,导出速度快且结构清晰。

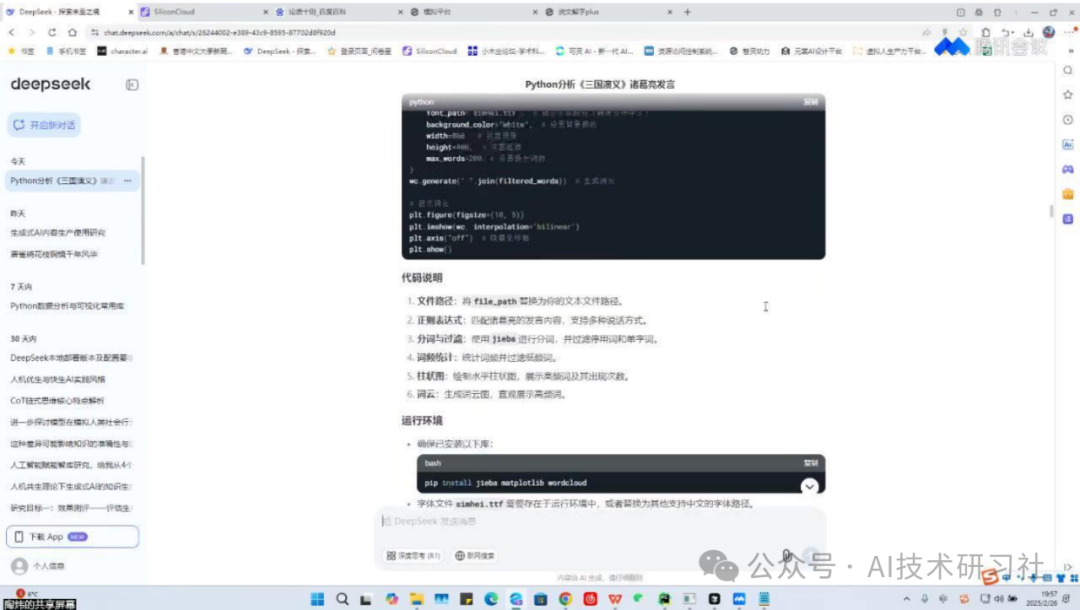
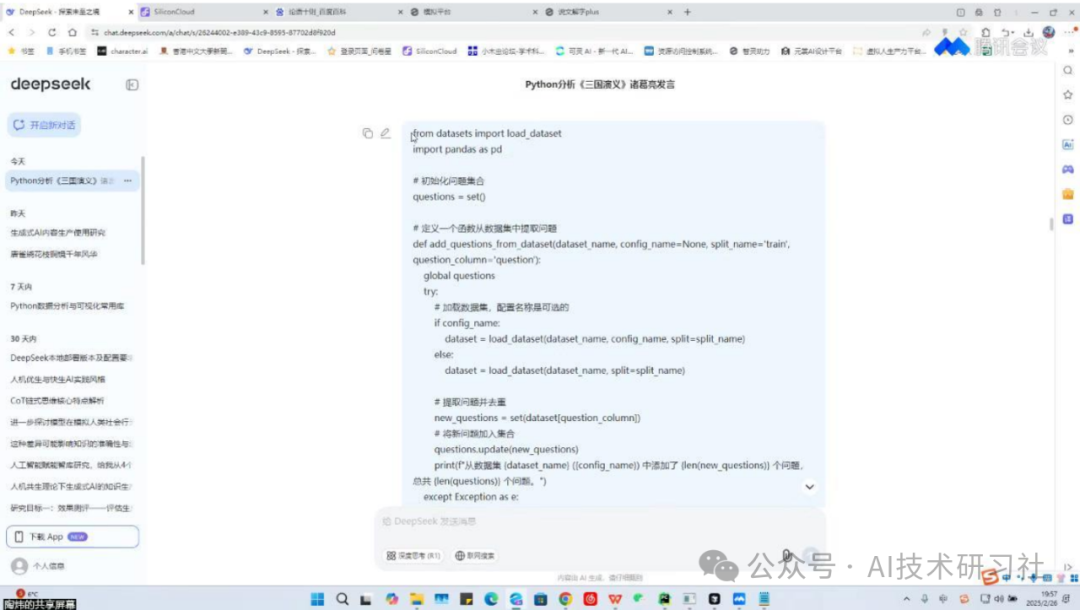
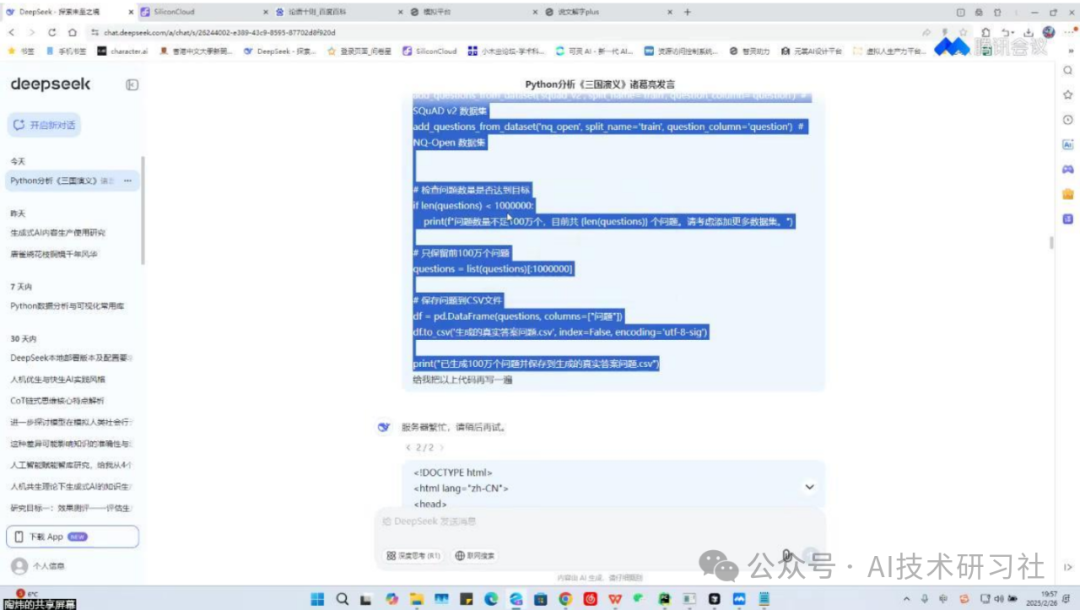
再说说应用场景。相比传统人工标注流程,我们节省了90%的时间成本,效率提升了10倍。AI不只是替代人工,更是在数据构建中重新定义了生产方式。

最后,回到文章开头那句话:“工欲善其事,必先利其器。”AI想变得更聪明,首先得喂好数据。


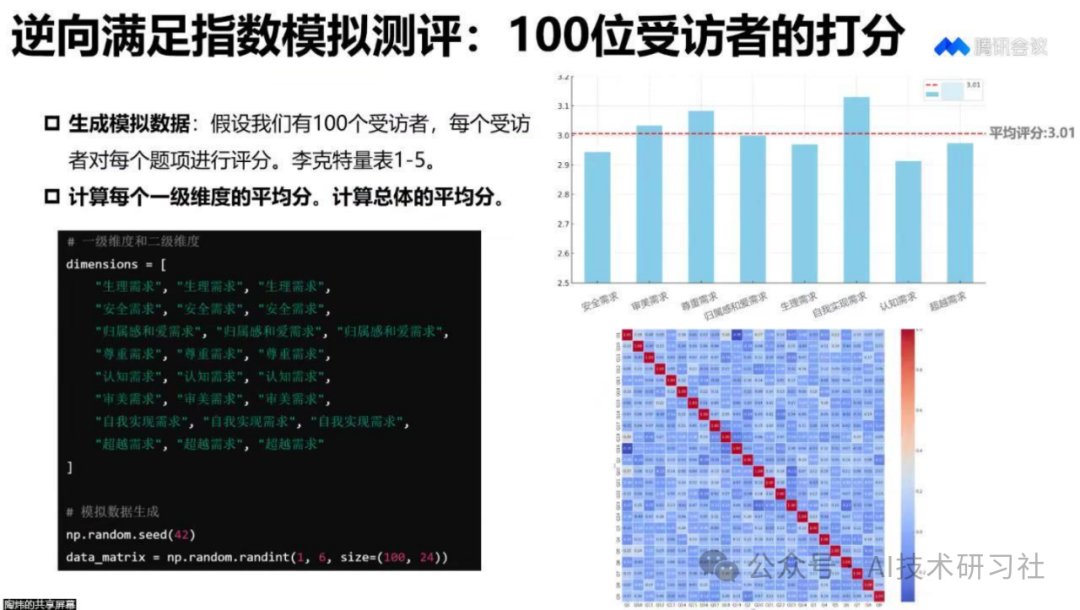
现在你不需要从头整理资料、熬夜标注问答了,只要选好工具,定义好规则,剩下的交给AI,自动生成、自动整理、自动导出,数据构建就能又快又准。
如果你正在开发一个RAG项目、训练私有大模型,或者想搭建自己的AI助手,这套流程你一定要试试!大家要是还在为训练数据发愁,欢迎在留言区聊聊你的经验与挑战。
完整资料下载:https://t.zsxq.com/jl2s8

(文:AI技术研习社)