

用人话讲 AI,我是认真的。
最近 Anthropic 发布了一篇技术博客,讲的是他们怎么把 Claude 打造成一个真正能完成整个深度调研流程的研究员 —— 不是那种搜几个网页糊一份报告的假把式,是实打实用一套 多智能体架构,能跑通流程、拆解任务、添加引用、还能复盘的 AI 系统。

这篇博客没有什么花活,基本全是工程细节。
看下来最大的感受是:多智能体系统从概念到落地,已经“走通了”。架构清晰、调度机制合理、提示词有经验、评估成体系。
下面我把这篇文章的关键点梳理了一下,如果你也在做 AI 产品、研究智能体、Agent 工程、RAG 系统,甚至只是好奇 Claude 的上限在哪,值得一读。
01|Claude 是怎么变成一个“研究员”的?
整个 Claude Research 背后的关键词叫:多智能体系统,Multi-agent System。
简单说,就是多个 Claude 智能体配合完成复杂调研任务的能力。
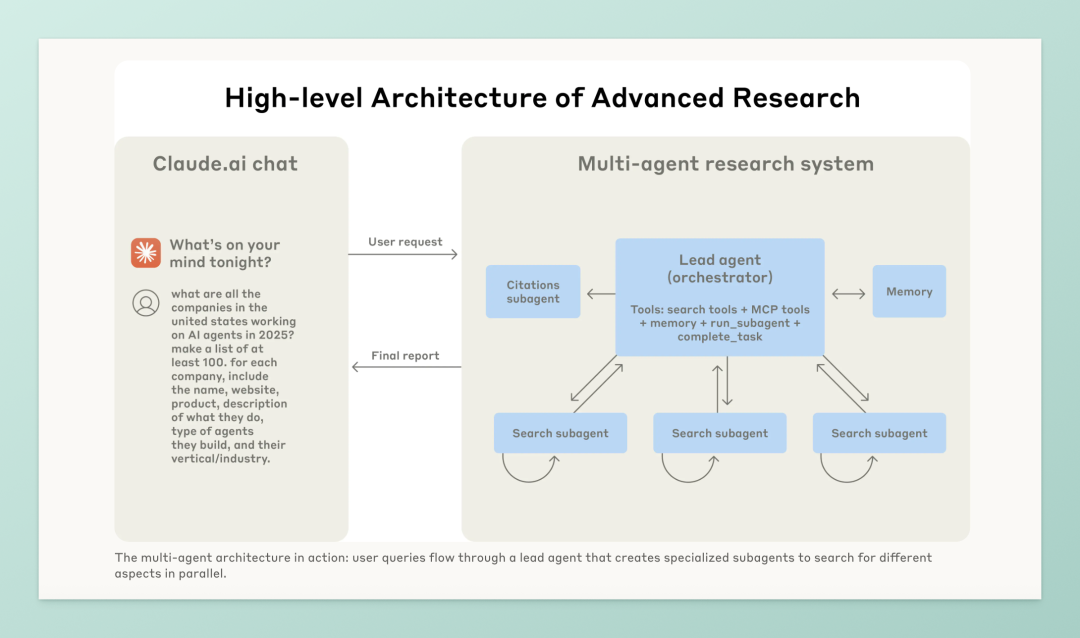
主脑是一个叫 LeadResearcher 的智能体,它负责理解你的问题、制定方案,然后再分派一堆 Subagents 去调研不同方向的信息,最后把结果拉回来做总结、引用和输出。
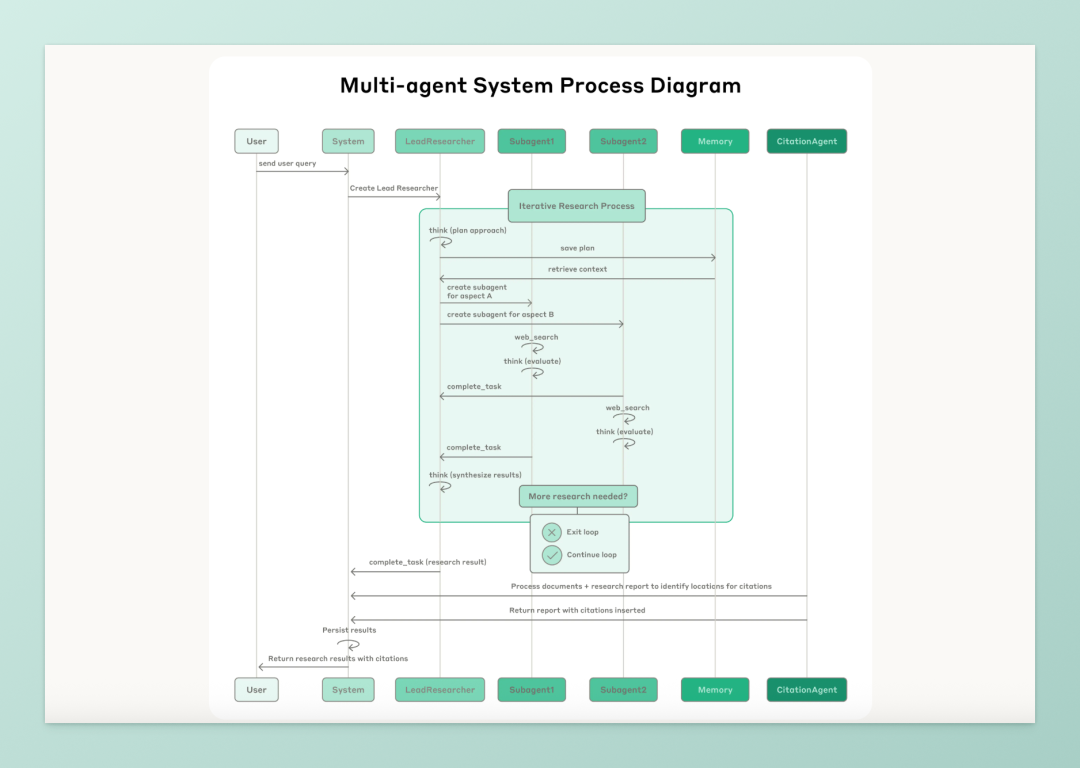
和传统 RAG 最大的不同在于:这不是“查询几个段落拼拼凑凑”,而是“像人一样调研” —— 查资料 → 思考 → 调整方向 → 查别的资料 → 综合 → 引用 → 写报告。
Claude 不光能用 Web 搜索工具搜外部资料,还能直连 Google Workspace、Slack、各种企业工具来获取内部信息作为调研任务的上下文。
这种“工具包式思维” + “团队合作式架构”,才真正把 LLM 变成了“干活的人”。
02|为什么要用多智能体?单智能体不行吗?
不行。
至少在复杂任务上,还远远不够。
Claude 团队自己也做了测试:在处理 “查出 S&P 500 里所有 IT 公司的董事会成员” 这种任务时,单 Claude Opus 4 完全搞不定,多智能体系统则直接完成了任务,成功率提升 90.2%。
根本原因在于 —— 深度调研本质是开放、不确定、路径依赖的,你没法预设步骤,也没法靠一次性操作把全网信息压缩进提示词或上下文。
人类做研究,会走弯路、分叉、兜圈子,多智能体系统就是用「多个上下文窗口 + 并行搜索 + 分工协作」来模拟这一过程。
03|架构长什么样?一句话总结:像在指挥一个远程研究团队
Claude Research 的架构,其实非常像一个线上版本的“项目经理 + 实习生团队”。
-
LeadResearcher(主脑)
-
接收问题,制定初步研究策略 -
把任务写进记忆系统,防止超过 token 限制丢上下文 -
规划子任务,分派出去 -
Subagents(子代理)
-
每个子代理拿到一个子任务(比如“调研 2021 年汽车芯片危机背景”) -
自己查资料、自我反思、评估结果质量 -
查得差不多了,就把结果上交 -
CitationAgent
-
负责给报告里的每一句话打出处 -
确保所有引用可追溯,不是“编”的
这个流程不是一拍脑袋硬编码出来的,而是跑出来、评估出来、调教出来的。
04|提示工程怎么玩?写的不是“提示”,是“分工说明书”
在这个多智能体系统里,提示词不再是“随便说点什么”的简单引导,而是 “团队协作协议” + “任务拆解说明书”。
Claude 团队踩了不少坑:
-
有时候主智能体不加控制,一次性放出了 50 个子代理,结果什么也没查出来 -
子代理重复劳动,三个人查同一件事 -
有的工具压根查不到信息(比如用 Web 搜 Slack 上的消息)
解决方法则很实在:
-
细化任务指令:每个子代理收到的提示词都是 “目标 + 工具使用建议 + 输出格式 + 任务边界”。
-
任务复杂度 = 智能体资源分配:
-
查个事实:1个 agent + 5 次工具调用; -
做个对比:2-4 个 agent + 每人 10-15 次调用; -
深度研究:10+ agent 并行起飞。 -
让 Claude 自己优化 Claude:用
Claude 4自己测试提示词、修改失败案例、改写工具描述,结果任务完成速度提升了 40%。
换句话说,Claude 已经开始“自己教自己怎么用工具”了,这是一种另类的“自我进化”。
05|Token 消耗与性能平衡:值不值
这套系统厉害归厉害,也确实“贵”。
数据如下:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
15× |
所以这个系统不是拿来随便聊天的,是用在「足够有价值」的场景 —— 比如搞企业调研、做学术研究、深度信息搜索。
Claude 团队说得很清楚:当智能体足够聪明,最好的扩展方式就不再是加 token,而是加 agent。

06|最难的不是搭出来,而是稳得住
Claude Research 这套系统从原型到上线,最难的是稳定性:
-
状态维护:Agent 会跑几十轮、上百次工具调用,不能崩也不能断 -
错误处理:一个工具调用失败了,不能整个流程回炉,要能恢复执行 -
部署节奏:Agent 随时可能在运行,不能一刀切更新,只能用“彩虹部署”慢慢切换 -
调试方法:跑一次不等于跑十次,每次行为都可能不一样,必须有高维度的追踪系统查看 agent 的决策路径、失败点
一句话总结:AI agent 系统不是写个算法就完事,而是和生产级软件系统一样复杂,甚至更不可控。
07|最后一公里,才是最远的路
Claude 团队在文末说了一句特别扎心但准确的话:
“当构建 AI 智能体时,最后一英里往往是旅程的重中之重。”
“When building AI agents, the last mile often becomes most of the journey.”
原型能跑不等于系统能上线。
能用了不等于跑得稳。
多智能体系统就像是搭建了一个小型团队,需要 写好规则、分清职责、控制代价、跟踪流程、处理错误,才能让它不发疯、不罢工、不失控。
这,就是智能体系统(Agentic System)的真正挑战。
结语
我们可能已经站在 AI 产品形态的又一个分水岭。
未来的 AI,不再是「一个聪明的聊天助手」,而是「一个独立运转的 AI 团队」—— 它能拆解任务、跑完整个流程、实时纠错、控制进度,甚至自动补上引用文献。
这种变化背后的关键,不只是模型升级,而是智能体系统设计理念的转变:从单点智能,到多智能体编排;从响应用户提问,到主动组织信息流;从“提示词试试看”,到“资源调度 + 策略规划 + 工具协同”。
Agent,不再只是一个功能组件,而开始成为产品本身。
从 Claude 的实践里,我们可以看见,下一代 AI 工程师的角色,正在从“写模型调用接口”变成“设计一个会做事的智能流程”。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)