
2024年,大家都在为检索增强生成(Retrieval-Augmented Generation, RAG)着迷吗?构建向量数据库(vector database)、分割文档(chunking documents)、创建嵌入(embeddings),以及处理复杂的流水线(pipelines),只为了回答关于公司文档的问题?好吧,我有一些消息可能会让你重新思考这一切。
本文的目标是探讨 2025 年检索增强生成(RAG)的现状,并深入分析关于“RAG 已死”的争论。我们将通过构建一个简单的 RAG 替代方案,并将其与传统方法进行比较来实现这一目标。此外,我们还将讨论“思考模型与非思考模型”的话题。
为了验证这一想法,我们将在 30 分钟内构建一个简单的问答(Q&A)代理,完全跳过 RAG,直接使用搜索 API(Tavily)和大上下文窗口(large context windows)。你猜怎么着?它不仅比传统 RAG 更简单、更便宜,而且往往表现得更好。
让我向你展示为什么这可能是基于文档的问答系统的未来。
友情提示,本文篇幅比较长,请耐心阅读,或者收藏慢慢阅读
📚 源代码:关注本公众号并回复0615 获取代码下载地址。
💡 剧透警告:不,RAG 并未消亡——但在 2025 年,它不应该是你的首选。保持简单!

2025 年的 RAG 大反思
我们的目标不是抨击 RAG(它仍有其用武之地!),而是通过一个实际案例来探索 2025 年的技术趋势。我们将构建一个传统上会使用 RAG 的系统,但采用一种完全不同的、越来越流行的方法。
通过本文,你将了解:
•为什么“直接访问源数据”的方法(go to source)因工具调用(tool calling)和模型上下文协议(MCP)而逐渐受到关注。•RAG 仍然适用的场景(剧透:比你想象的少)。•如何构建一个用户喜爱的实用替代方案。•额外内容:为什么非思考模型(non-thinking models)在简单结构化任务中往往优于“思考模型”(thinking models)。
准备好了吗?让我们开始吧!🤿
RAG:优点、缺点与复杂性
什么是 RAG?
你可以将 RAG 想象成一个非常高级的图书馆员系统。当有人提出问题时:
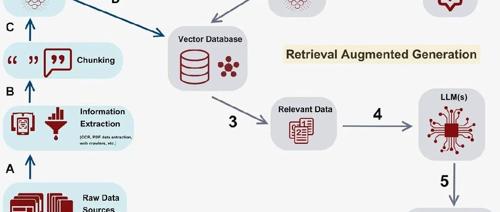
1.将文档分割成小块(因为模型有上下文限制)。2.将所有内容转换为嵌入(embeddings,数学表示形式)。3.将嵌入存储在向量数据库(vector database,你的数字图书馆)。4.当问题到来时,将问题也转换为嵌入。5.使用向量相似性搜索(vector similarity search)找到相似的文档块。6.将这些文档块与问题一起输入到大型语言模型(LLM)。7.根据检索到的上下文生成答案。
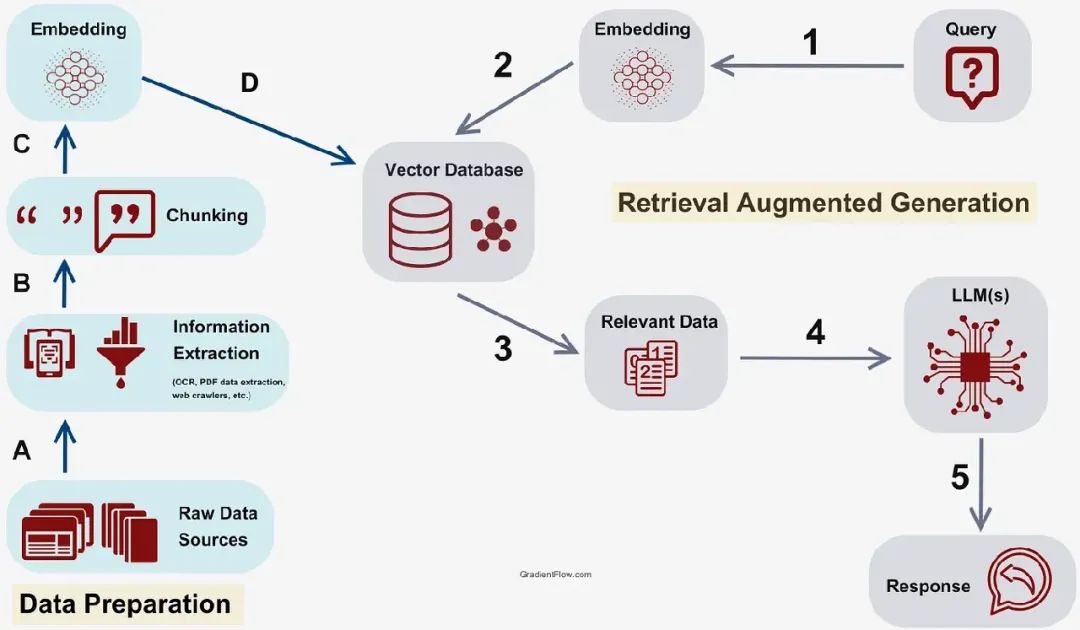
RAG 架构
以下是一个简化的 RAG 流水线示例:
# 传统 RAG 流水线(简化版)def rag_pipeline(question):# 步骤 1:将问题转换为嵌入question_embedding = embedding_model.encode(question)# 步骤 2:搜索向量数据库similar_chunks = vector_db.similarity_search(question_embedding,top_k=5)# 步骤 3:从文档块构建上下文context ="\n".join([chunk.content for chunk in similar_chunks])# 步骤 4:生成答案prompt = f"Context: {context}\n\nQuestion: {question}\nAnswer:"return llm.generate(prompt)
想了解更多关于 RAG 的内容,可以观看这个简短视频。
RAG 的历史:为何它曾如此流行?
在 2020-2023 年期间,RAG 非常有意义,原因如下:
•小上下文窗口:GPT-3 只有 4K 令牌(tokens)!这是 RAG 被引入的主要原因。•高昂的令牌成本:处理大型文档的成本很高。•“迷失中间”问题:模型无法很好地处理长上下文。•对新鲜数据的需求:模型有训练数据截止时间。
RAG 通过选择性地包含信息解决了这些问题,并允许将最新数据添加到过时的模型中。
简单 RAG 示例
假设你有公司文档,有人问:“如何在我们的 API 中设置认证?”
传统 RAG 方法:
1.将文档分割成 500 字的块。2.找到 3-5 个与认证最相关的块。3.仅将这些块输入到 LLM。4.生成答案。
在上下文受限且成本高昂时,这种方法效果很好,但……
隐藏的复杂性:RAG 的不为人知之处
虽然 RAG 在理论上听起来优雅,但实现和维护的现实远比大多数教程描述的复杂。
以下是一些真正的挑战:
🔧 基础设施噩梦
•复杂设置:RAG 需要向量数据库、嵌入流水线、分块策略、监控和扩展 → 高复杂度。•高成本:向量数据库和 RAG 流水线的运行和维护成本高昂,一旦数据量达到一定规模,成本会激增,每月可能高达数千美元。•供应商锁定:选择 Pinecone、Weaviate、Chroma 或自托管解决方案,均需支付高额月费。
📊 分块问题
分块是将文档分割成小块并保留语义意义的过程,这些小块随后存储在向量数据库中。分块策略有很多种,各有优缺点,且都不完美,以下是一些问题:
•上下文丢失:分割文档会破坏逐步说明,代码与解释分离。•无完美策略:固定大小、语义或段落分块都有重大缺陷。•跨引用断裂:相关部分被分开,丢失重要联系。
🔍 相似性搜索的假象
向量数据库使用相似性搜索,概念上类似于 Elasticsearch,但专为 LLM 嵌入优化。虽然 Elasticsearch 经过多年验证,但向量数据库较新且仍在发展。正如我们稍后将讨论的,RAG 的一个替代方案是利用现有的 Elasticsearch 基础设施,通过创建工具查询其上下文检索。这种方法对已有 Elasticsearch 集群的组织特别有价值,因为它避免了引入向量数据库等额外基础设施。
•数学 ≠ 相关性:高相似性得分并不保证结果有用。•查询不匹配:问题与文档语句对齐不佳。•缺失上下文:嵌入丢失重要的限定信息。
🔄 维护噩梦
•文档更新:每次更改都需要重新分块、重新嵌入、重新索引整个流水线!•模型不兼容:无法混合不同模型的嵌入;升级 = 完全重建!这使得切换模型非常具有挑战性!•性能下降:随着向量数据库的增长,速度会变慢。一旦数据量较大,延迟将成为问题。
📈 扩展现实
•指数成本:基础设施需求增长速度超过文档数量。•收益递减:更多文档往往意味着更差的搜索质量。•运营开销:大型部署需要专门的 DevOps 团队。
🐛 常见失败
•“迷失中间”:LLM 忽略搜索结果中的中间块。•数据过时:向量搜索没有新鲜度感知。•上下文碎片化:复杂答案被分散在多个块中。
现实检查:
•指数成本:基础设施需求增长速度超过文档数量(向量数据库扩展挑战)。•收益递减:更多文档往往意味着更差的搜索质量。•运营复杂性:需要专门的 DevOps 专业知识。
这种复杂性正是我们构建的简单搜索优先方法获得关注的原因。核心思想是直接访问数据,而不是创建复杂的 RAG 流水线。
通过使用成熟的搜索 API 和大上下文窗口,我们可以以更低的复杂性获得更好的结果。
RAG 在 2025 年:格局已剧变
上下文窗口革命
过去 18 个月的变化彻底颠覆了一切:
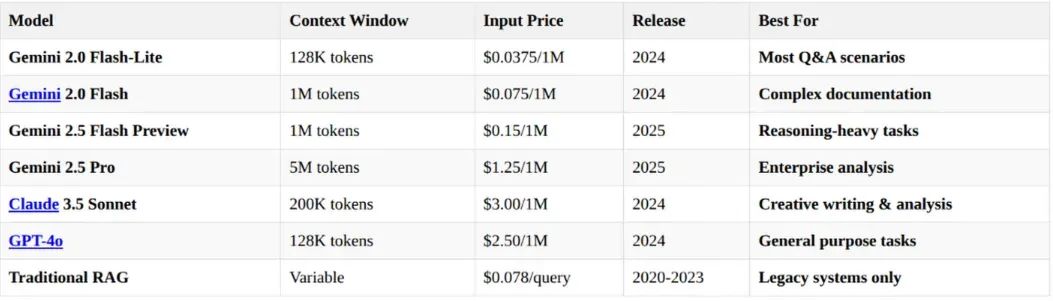
上下文窗口 + 成本 等等,100 万令牌的窗口只需 0.075 美元?这相当于大约 75 万字——整整一本书的内容!
谷歌凭借其 Gemini 模型引领了这波创新浪潮。得益于专用 TPU 和大规模数据中心基础设施,谷歌将上下文窗口推高至 500 万令牌,同时保持每令牌成本极低。然而,长上下文窗口也有类似 RAG 的扩展问题,真正的变化在于直接访问源数据,而不是构建复杂的流水线。
像 Gemini Flash 这样的模型为许多 LLM 使用场景提供了快速、成本效益高且简单的解决方案。此外,最新的 Gemini 版本在主要基准测试中超越了大多数竞争对手。
正如我们稍后将探讨的,我非常喜欢 Gemini 2.0 Flash——它速度极快、价格实惠,且能轻松处理大上下文窗口。
更新:Gemini Flash 2.5 模型刚刚发布,是一个极佳的替代选择,尽管价格略高。
这开启了一个根本性的范式转变。与其将多个来源的数据加载到向量数据库并维护复杂的 RAG 流水线,我们可以构建直接访问工具并将其提供给 LLM 和代理。核心思想是利用组织可能已经拥有的成熟解决方案,例如文档网站或 Elasticsearch。
这种方法远比传统 RAG 简单。凭借当今快速、价格实惠的 LLM 模型和大上下文窗口,成本和延迟不再是限制因素。
模型上下文协议(MCP)的引入从根本上改变了代理与工具的交互方式。MCP 使代理能够自动发现工具并动态连接到数据库、API 和企业系统,而无需手动配置每个工具连接。
这创建了真正的非确定性代理工作流(non-deterministic agentic workflows),其中魔法发生:工具本身可以成为代理,递归调用其他工具。想象一个代理发现数据库工具,用它查询客户数据,然后自动找到并调用电子邮件 API 工具发送个性化消息——所有这些都不需要预定的工作流。
结果是自组织代理生态系统,根据可用功能动态适应,而不是依赖刚性编程或确定性工作流。曾经需要复杂手动设置的内容,现在通过工具交互自然浮现,使复杂的多代理系统对任何开发者都触手可及。
💡 未来文章预告:在下一篇文章中,我们将为代理添加 MCP,并讨论 MCP 革命以及 CrewAI 或 LangGraph 等框架可能的消亡,敬请期待!
关键外部数据检索工具
如前所述,RAG 的主要替代方案是构建直接查询源数据的工具,提取相关内容,并将其作为上下文提供给 LLM。
💡 额外福利:这些工具本身可以是代理,创建层次结构,每个工具封装复杂性,暴露简单的可发现接口。
另一个优势是 LLM 可以根据输入动态决定使用哪些工具,使代理能够智能选择工具并配置参数,创建真正的非确定性工作流。
以下是一些可用于从现有系统提取上下文的工具示例:
🔍 公共搜索工具
•Tavily:使 LLM 能够搜索预索引的公共网站以获取相关上下文 → 这是我们将在代理中使用的工具!
🏢 企业搜索工具
•Elasticsearch 等平台:直接连接到现有搜索索引以检索查询的相关数据。•利用现有基础设施:无需重建已有的内容。•搜索引擎 vs 向量数据库:像 Elasticsearch 这样的传统搜索引擎已使用多年,在检索相关信息方面通常优于向量数据库。
🗄️ 数据库集成工具
•SQL 生成:使用 LLM 生成 SQL 查询并直接从数据库检索结构化数据的工具。这更复杂,但可行。
💡 未来文章预告:对数据库集成方法感兴趣?请告诉我——我计划撰写一篇关于 LLM 到 SQL 工具和技术的专门文章!
得益于 MCP,代理可用的工具数量激增,你可以在这里找到精选列表,也可以使用 Awesome MCP Servers 发现更多。你甚至可以直接从代理连接到远程服务器。我将在下一篇文章中详细讨论 MCP!
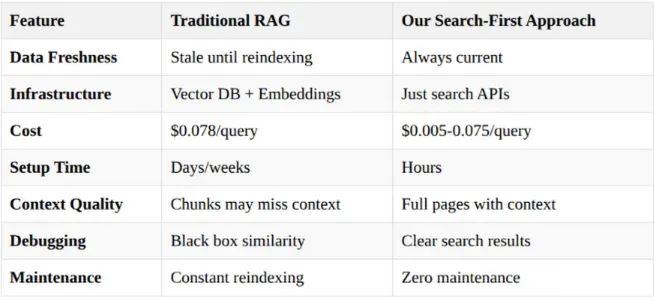
为什么 RAG 替代方案表现更好
✅ 更简单的架构 —— 更少的活动部件
✅ 更低的维护成本 —— 利用现有搜索基础设施
✅ 始终新鲜的数据 —— 无需担心过时嵌入
✅ 成本效益高 —— 现代 LLM 使这在经济上可行
✅ 更快开发 —— 基于成熟的搜索技术
💡 核心洞察:当搜索引擎已经有效解决了检索问题时,不要重新发明轮子。
RAG 替代方案的优势
✅ 搜索优先更便宜,比传统 RAG 维护成本低得多
🔁搜索优先始终新鲜—— 无需更新过时索引或重新生成嵌入
✅无“迷失中间”问题—— 搜索优先返回最相关内容
✅更好的上下文相关性—— 搜索算法优化查询相关性
✅更快迭代—— 文档更改时无需重新生成嵌入
✅更简单调试 —— 容易查看检索到的内容及原因
然而,RAG 在以下场景仍有用:
•超大数据集(100GB+)•细粒度文档块访问控制•离线/隔离环境•超高流量场景(>10万查询/天)•需要复杂关系的文档
💡 结论:RAG 不应是首选,仅在隐私敏感或数据难以即时访问的特定情况下考虑。
动手实践:构建搜索优先的问答代理
好了,理论讲够了!让我们构建一个能证明搜索优先优于 RAG 的系统。
🔗 获取代码:关注本公众号并回复0615 获取代码下载地址。
我们要构建什么?
我们将创建一个特定领域的问答代理,它:
•仅搜索批准的组织文档网站 → 设置护栏(guardrails)•使用搜索 API 而非向量数据库•在需要时回退到全面的网页抓取•提供透明的来源归因•可选地,总结搜索结果以降低成本和延迟•成本仅为传统 RAG 系统的一小部分
将其视为“无检索的 RAG”——我们用新鲜、全面的搜索结果增强生成,而不是预处理的分块。
传统上,当我们受限于 4K 令牌窗口时,开发者会将所有文档加载到向量数据库并使用 RAG 提取相关上下文。如前所述,这相当复杂且难以维护。以下是传统解决方案的样子:

复杂 RAG 解决方案
这种方法非常复杂,我们的方法则不同:直接使用工具访问源数据,充分利用已证明其数据提取效果的现有搜索引擎。
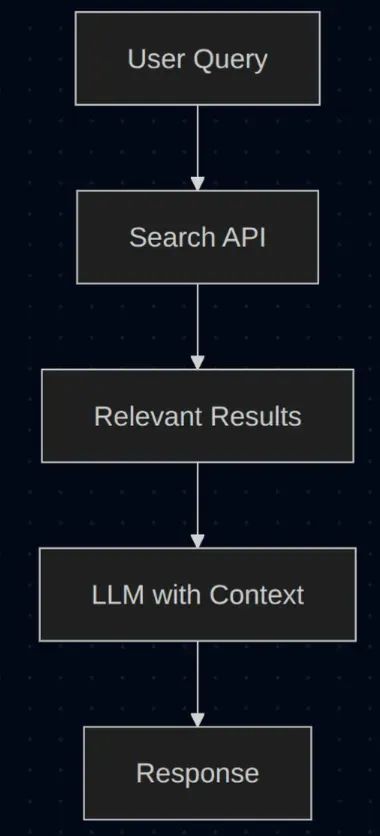
更简单的解决方案
重要说明:此解决方案专门适用于搜索引擎索引的公开网站。如果您处理的是内部文档或私有数据,我很乐意展示如何使用 Elasticsearch 进行内部上下文检索,或使用 SQL 即时检索结构化数据。
特性:为什么这优于传统 RAG
架构:实际工作原理
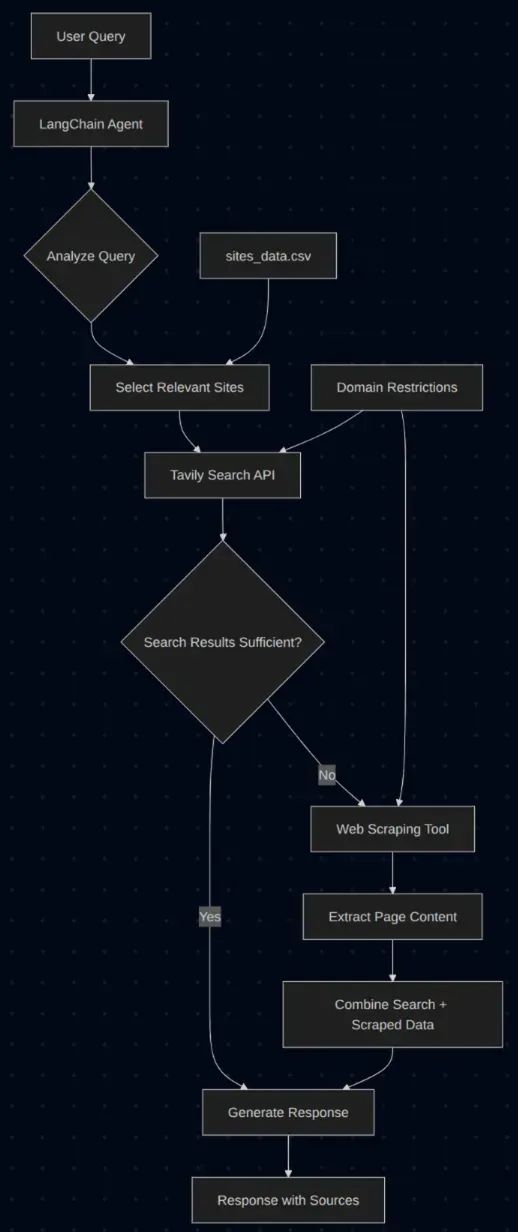
1.初始化阶段:代理启动时,读取包含以下内容的 CSV 文件:•要搜索的网站 URL•领域或类别(主题/学科领域,非网站域名)•帮助 LLM 理解何时使用每个网站的描述2.查询处理:当用户提交查询时,LLM 分析查询并智能选择最可能提供答案的网站。所有查询均异步处理。3.搜索执行:选定的网站被传递给搜索工具,使用 Tavily 在这些预批准的域名内执行快速、针对性的搜索。4.动态决策:根据搜索结果,LLM 评估是否足以提供完整答案:•如果是:立即返回响应•如果否:可能调用网页抓取工具以从特定页面收集更多细节
此解决方案展示了真正代理化设计的美妙之处——简单却异常强大。我们不遵循僵化的预编程路径,而是让代理根据每个查询的特定上下文智能决定采取哪些行动和使用哪些工具。为此,我们使用简单的非思考模型,遵循著名的 ReACT 框架,让代理在循环中思考并决定下一步行动。这是使非思考模型“思考”的简单方法。
我们使用双层策略:
•快速搜索(90% 的查询):使用 Tavily 在批准的域名内快速搜索并总结结果。•深度抓取(10% 的查询):当搜索不足以提供答案时,抓取整个页面。
ReACT vs 思考模型:为什么我们选择速度而非“智能”
这是一个有争议的观点:我们故意选择 Gemini 2.0 Flash 而非“思考”模型(如 OpenAI 的 o3 或 Gemini 2.5 Pro)。为什么?
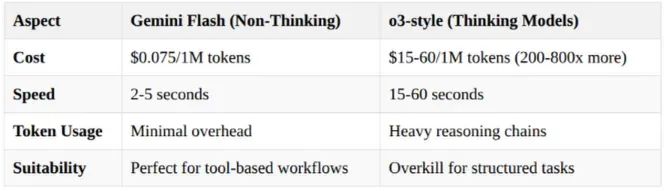
•Gemini Flash 2.0 便宜且快速•ReAct 框架以 1/200 的成本提供结构化思考:

我更喜欢使用带 ReACT 的非思考模型的主要原因是可扩展性。在许多情况下,查询生成简单响应,不需要广泛推理,思考模型显得过于复杂。非思考模型为这些场景提供快速且成本效益高的解决方案。对于复杂问题,ReACT 通过循环模拟思考模型的推理能力。
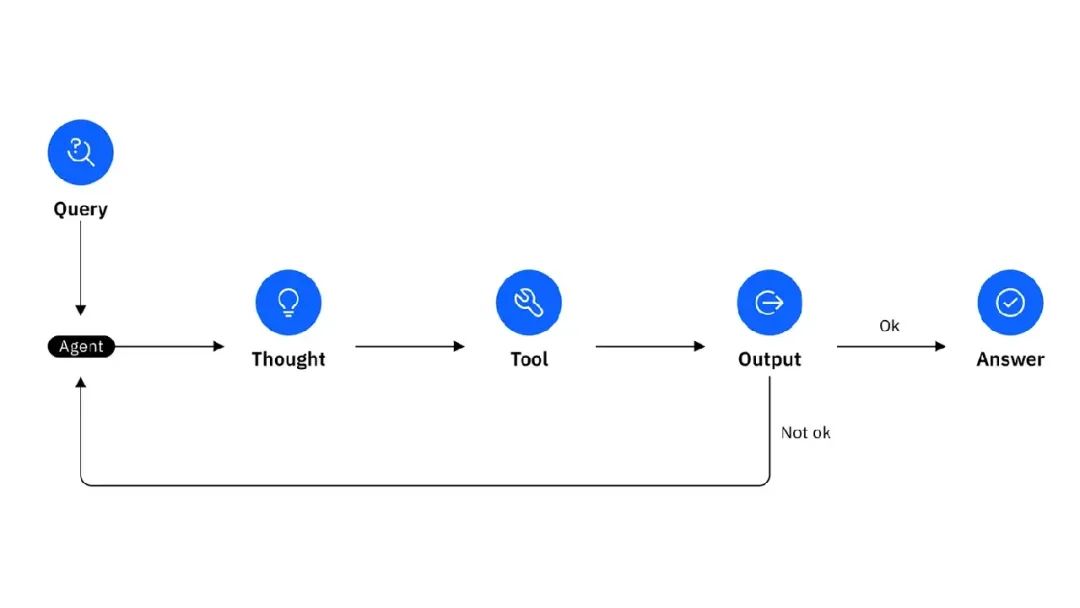
ReAct 循环
对于搜索和回答工作流,这比内部链式推理(chain-of-thought)更高效。根据我的经验,当使用多个工具且每个工具有多个输入时,这种解决方案比使用链式推理 LLM 更有效。
代理遵循 ReACT 提示,每个工具的描述详细说明了输入和输出。运行应用程序时,你会看到代理可能通过链式思考循环进行多次搜索,或决定使用网页抓取,所有这些都由代理自行决定,无需人工干预!
✅ ReACT 提示在长上下文窗口中也能有效防止幻觉(hallucinations)!
模型选择
对于问答代理,gemini-2.0-flash 提供了出色的平衡,具备惊人的速度、成本效益以及轻松处理大上下文窗口的能力。其免费层限制相当宽松,提供每分钟 15 次请求(RPM)、每分钟 100 万令牌(TPM)和每天 1500 次请求(RPD),非常适合广泛的应用场景,在考虑付费层之前。这是我在仓库中使用的模型。
当您的问答代理需要更强的推理能力和更“智能”的响应时,gemini-2.5-flash-preview-05-20 是更好的选择。该模型性能更佳,分析能力更强,适合复杂查询。然而,其免费层限制更严格(例如,10 RPM、25 万 TPM、500 RPD),且价格略高。如果您有付费账户且需要高准确性,请使用此模型。
另一方面,如果您的主要关注点是高吞吐量、成本效益和最大化免费层使用量以处理简单、高流量的问答,gemini-2.0-flash-lite 是最合适的替代选择。虽然其复杂推理能力略逊,但其显著更高的速率限制(例如,30 RPM、100 万 TPM、1500 RPD)和价格允许更大的交互量。
实现:让我们看看代码
现在是激动人心的部分!我们将逐步讲解实际实现。即使您对 Python 或 LangChain 不熟悉,我也会一步步解释。
我们使用 LangChain,因为它提供了统一的、模型无关的接口,简化了复杂 LLM 应用的开发。它擅长通过“链”(Chains)和“代理”(Agents)编排多步骤工作流,使 LLM 能够使用“工具”(Tools),并轻松管理对话记忆。这种抽象层减少了样板代码,加速开发,增强应用灵活性,未来-proof,并通过 LangSmith 等集成提供关键的调试功能。
🔄 Pydantic AI 是 LangChain 的一个更易用的替代方案。
🏗️ 架构概览:文件如何协同工作
仓库遵循简单的分层架构,非常简洁:
📁项目结构├── main.py # 🌐 FastAPI 网络服务器(入口)├── qa_agent.py # 🧠 核心代理逻辑(编排者)├── search_tool.py # 🔍 搜索功能├── scraping_tool.py # 🕷️ 网页抓取功能└── sites_data.csv # 📋 域名配置
流程:
•main.py → 接收用户 HTTP 请求•qa_agent.py → 决定使用哪些工具并编排响应•search_tool.py / scraping_tool.py → 执行查找信息的实际工作•返回 qa_agent.py → 合并结果并生成最终答案•返回 main.py → 将响应返回给用户
将其想象成一家餐厅:main.py 是服务员,qa_agent.py 是决定烹饪什么的厨师,工具是专门的厨房设备。
1. 搜索工具(search_tool.py)
让我们从搜索功能开始。此工具连接到 Tavily 搜索 API 以查找相关信息。
"""特定领域的Tavily搜索工具"""import loggingfrom typing importList,Optional,Type,Anyfrom pydantic importBaseModel,Field,ConfigDictfrom langchain.tools importBaseToolfrom langchain_google_genai importChatGoogleGenerativeAIfrom tavily importTavilyClientlogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)classTavilySearchInput(BaseModel):query: str =Field(description="包含相关关键词的搜索查询")sites:List[str]=Field(description="要搜索的网站域名(例如,['docs.langchain.com'])")max_results:Optional[int]=Field(default=None, description="返回的最大结果数")depth:Optional[str]=Field(default=None, description="搜索深度:'basic' 或 'advanced'")classTavilyDomainSearchTool(BaseTool):"""使用 Tavily 搜索特定域名"""name: str ="search_documentation"description: str ="""使用 Tavily 网络搜索特定文档网站。必需参数:- query (字符串):包含相关关键词的搜索查询-你想查找的内容- sites (列表):要在其中搜索的网站域名(例如,['docs.langchain.com','fastapi.tiangolo.com'])可选参数:- max_results (整数):返回的最大搜索结果数(默认:10)- depth (字符串):搜索深度-'basic'用于快速搜索,'advanced'用于全面搜索(默认:'basic')使用指南:1.从用户问题中创建富含关键词的搜索查询2.根据提到的技术选择相关网站域名3.使用'basic'深度进行快速回答,'advanced'进行深入研究4.根据答案的全面性需求调整 max_results示例:-快速搜索:query="LangChain 自定义工具", sites=["docs.langchain.com"], depth="basic", max_results=5-全面搜索:query="FastAPI 认证中间件", sites=["fastapi.tiangolo.com"], depth="advanced", max_results=15最佳实践:-在查询中包含技术术语和框架名称-根据问题上下文选择合适的域名-优先选择官方文档网站而非第三方来源-使用具体查询而非宽泛术语以获得更好结果"""args_schema:Type[BaseModel]=TavilySearchInputtavily_client:Any=Field(default=None, exclude=True)api_key: str =Field(exclude=True)default_max_results:int=Field(default=10, exclude=True)default_depth: str =Field(default="basic", exclude=True)max_content_size:int=Field(default=10000, exclude=True)enable_summarization:bool=Field(default=False, exclude=True)summarizer_llm:Any=Field(default=None, exclude=True)model_config =ConfigDict(arbitrary_types_allowed=True)def __init__(self,api_key: str,max_results:int=10,depth: str ="basic",max_content_size:int=10000,enable_summarization:bool=False,google_api_key:Optional[str]=None,):super().__init__(api_key=api_key,default_max_results=max_results,default_depth=depth,max_content_size=max_content_size,enable_summarization=enable_summarization,args_schema=TavilySearchInput,)ifnot api_key:raiseValueError("TAVILY_API_KEY 是必需的")object.__setattr__(self,"tavily_client",TavilyClient(api_key=api_key))if enable_summarization and google_api_key:summarizer = create_summarizer_llm(google_api_key)object.__setattr__(self,"summarizer_llm", summarizer)logger.info("🧠 使用 Gemini Flash-Lite 启用搜索结果摘要")elif enable_summarization:logger.warning("⚠️ 摘要功能已禁用:未提供 google_api_key")object.__setattr__(self,"enable_summarization",False)logger.info(f"Tavily 搜索工具已初始化(摘要功能:{'启用' if self.enable_summarization else '禁用'})")async def _search_async(self, query: str, sites:List[str], max_results:int=None, depth: str =None)-> str:"""异步执行给定参数的搜索"""try:final_max_results = max_results orself.default_max_resultsfinal_depth = depth orself.default_depthlogger.info(f"🔍 搜索:'{query}' 在网站:{sites}")logger.info(f"📊 参数:max_results={final_max_results}, depth={final_depth}")# 注意:TavilyClient 尚不支持异步方法,因此在线程中运行search_results = await asyncio.to_thread(self.tavily_client.search,query=query,max_results=final_max_results,search_depth=final_depth,include_domains=sites,)logger.info(f"📥 收到 {len(search_results.get('results', []))} 个结果")ifnot search_results.get("results"):logger.warning("⚠️ 未返回搜索结果")return"未找到结果。请尝试不同的搜索查询或检查域名是否可访问。"formatted_results = format_search_results(search_results["results"][:final_max_results],self.max_content_size)final_result ="\n".join(formatted_results)logger.info(f"✅ 处理了 {len(search_results['results'])} 个结果,返回 {len(final_result)} 个字符")ifself.enable_summarization andself.summarizer_llm:try:logger.info("🧠 正在摘要结果...")summarized_result = await self._summarize_results_async(final_result, query)reduction = round((1- len(summarized_result)/ len(final_result))*100)logger.info(f"📊 摘要:{len(final_result)} → {len(summarized_result)} 字符(减少 {reduction}%)")return summarized_resultexceptExceptionas e:logger.error(f"❌ 摘要失败:{e}。返回原始结果。")return final_resultexceptExceptionas e:error_msg = f"❌ 搜索错误:{str(e)}"logger.error(error_msg)return error_msgasync def _summarize_results_async(self, search_results: str, original_query: str)-> str:"""使用 LLM 异步摘要搜索结果"""try:prompt = create_summary_prompt(search_results, original_query)response = await asyncio.to_thread(self.summarizer_llm.invoke, prompt)return response.contentexceptExceptionas e:logger.error(f"LLM 摘要失败:{e}")return search_resultsdef _run(self, query: str, sites:List[str], max_results:int=None, depth: str =None)-> str:"""执行给定参数的搜索"""return asyncio.run(self._search_async(query, sites, max_results, depth))async def _arun(self, query: str, sites:List[str], max_results:int=None, depth: str =None)-> str:"""异步搜索版本"""return await self._search_async(query, sites, max_results, depth)
🔍 这里发生了什么:
•LangChain BaseTool:我们继承这个类来创建代理可以使用的工具,在下一篇文章中我们会将其转换为 MCP 服务器。•工具描述:非常重要,告诉代理何时以及如何使用工具。确保描述精确。•Pydantic 模型:用于工具输入的类型验证——确保代理传递正确的参数。•域名限制:通过 include_domains 参数实现护栏,确保仅搜索批准的网站。•智能摘要:可选的 AI 驱动结果压缩,使用 Gemini Flash-Lite 降低令牌成本。•异步支持:使用 _arun 方法支持异步执行。•错误处理:全面的日志记录和优雅的失败恢复。•灵活配置:支持不同的搜索深度和结果限制。
2. 网页抓取工具(scraping_tool.py):可选
当搜索结果不足时,此工具抓取整个网页以获取全面信息。
"""使用Chromium进行动态内容提取的网页抓取工具"""import loggingimport asynciofrom typing importList,Typefrom pydantic importBaseModel,Field,ConfigDictfrom langchain.tools importBaseToolfrom langchain_community.document_loaders importAsyncChromiumLoaderfrom langchain_community.document_transformers importBeautifulSoupTransformerlogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)def get_default_tags()->List[str]:"""获取用于网页抓取的默认 HTML 标签"""return["p","li","div","a","span","h1","h2","h3","h4","h5","h6"]classWebScrapingInput(BaseModel):url: str =Field(description="要抓取的 URL")tags_to_extract:List[str]=Field(default_factory=get_default_tags, description="要提取的 HTML 标签")classWebScrapingTool(BaseTool):"""当搜索结果不足时抓取网站内容"""name: str ="scrape_website"description: str ="""使用 Chromium 浏览器抓取完整网站内容以进行全面页面提取。必需参数:- url (字符串):要抓取的完整 URL(必须包含 https:// 或 http://)可选参数:- tags_to_extract (列表):要提取内容的 HTML 标签默认:["p","li","div","a","span","h1","h2","h3","h4","h5","h6"]自定义示例:["pre","code"]用于代码示例,["table","tr","td"]用于表格何时使用:-搜索结果不完整或不足-需要包括代码示例的完整页面内容-页面有搜索未捕捉的动态JavaScript内容-需要搜索未捕捉的特定格式或结构示例:-基本抓取:url="https://docs.langchain.com/docs/modules/agents"-代码聚焦抓取:url="https://fastapi.tiangolo.com/tutorial/", tags_to_extract=["pre","code","p"]-表格提取:url="https://docs.python.org/3/library/", tags_to_extract=["table","tr","td","th"]最佳实践:-仅在 search_documentation 提供的信息不足时使用-优先选择来自先前搜索结果的 URL 以确保相关性-使用特定标签提取以获得目标内容(处理更快)-注意:比搜索慢约3-10倍,为性能起见谨慎使用限制:-内容会在配置的限制处截断以防止过多令牌使用-某些网站可能阻止自动化抓取-比搜索慢-仅在搜索不足时使用"""args_schema:Type[BaseModel]=WebScrapingInputmax_content_length:int=Field(default=10000, exclude=True)model_config =ConfigDict(arbitrary_types_allowed=True)def __init__(self, max_content_length:int=10000):super().__init__(max_content_length=max_content_length, args_schema=WebScrapingInput)async def _process_scraping(self, url: str, tags_to_extract:List[str]=None, is_async:bool=True)-> str:"""同步和异步抓取的通用逻辑"""try:if tags_to_extract isNone:tags_to_extract = get_default_tags()loader =AsyncChromiumLoader([url])if is_async:html_docs = await asyncio.to_thread(loader.load)else:html_docs = loader.load()ifnot html_docs:return f"无法从 {url} 加载内容"bs_transformer =BeautifulSoupTransformer()if is_async:docs_transformed = await asyncio.to_thread(bs_transformer.transform_documents,html_docs,tags_to_extract=tags_to_extract,)else:docs_transformed = bs_transformer.transform_documents(html_docs,tags_to_extract=tags_to_extract,)ifnot docs_transformed:return f"无法从 {url} 提取内容"content = docs_transformed[0].page_contentif len(content)>self.max_content_length:content =(content[:self.max_content_length]+"\n\n... (内容已截断)")return f"""**抓取的网站:**{url}**提取的内容:**{content}**注意:**完整的网站内容用于全面分析。"""exceptExceptionas e:return f"网页抓取错误 {url}:{str(e)}"def _run(self, url: str, tags_to_extract:List[str]=None)-> str:"""抓取网站内容"""return asyncio.run(self._process_scraping(url, tags_to_extract, is_async=False))async def _arun(self, url: str, tags_to_extract:List[str]=None)-> str:"""异步抓取版本"""return await self._process_scraping(url, tags_to_extract, is_async=True)
🕷️ 这里发生了什么:
•AsyncChromiumLoader:使用真实的 Chromium 浏览器处理 JavaScript 密集型网站。•BeautifulSoupTransformer:从 HTML 中智能提取干净的文本。•选择性标签提取:仅提取有意义的标签内容,忽略导航和广告。•内容限制:自动截断长页面以保持令牌成本合理。注意:这里也可以使用摘要!•错误恢复:优雅处理网络故障、JavaScript 错误和解析问题。•异步支持:内置异步方法以实现生产可扩展性。
3. 问答代理(qa_agent.py) – 大脑 🧠
这里是魔法发生的地方。代理决定使用哪些工具并编排整个对话。
"""具有特定领域网络搜索能力的问答代理"""import loggingimport pandas as pdfrom typing importList,Dict,Any,Optionalfrom langchain.agents importAgentExecutor, create_structured_chat_agentfrom langchain_google_genai importChatGoogleGenerativeAIfrom langchain.prompts importChatPromptTemplate,MessagesPlaceholderfrom langchain.schema importBaseMessage,HumanMessage,AIMessagefrom search_tool importTavilyDomainSearchToolfrom scraping_tool importWebScrapingToollogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)def create_system_prompt(knowledge_sources_md: str, domains:List[str])-> str:"""创建包含知识来源的系统提示"""return f"""你是一个专门搜索特定文档网站的问答代理。可用知识来源按类别/领域/主题划分,包含每个类别的网站和描述:{knowledge_sources_md}指令:1.对于任何问题,始终首先使用 search_documentation 工具2.分析用户问题以确定相关的领域/主题/类别3.根据提到的技术/主题选择合适的网站4.如果搜索结果不足以完全回答问题,则在搜索结果中最相关的 URL 上使用 scrape_website 工具5.你只能回答关于可用知识来源的问题:{domains}6.如果问题超出可用知识来源,不要回答问题,并建议可以回答的主题工具使用策略:-首先:使用 search_documentation 快速查找相关信息-其次:如果搜索结果不完整、不清晰或信息不足以回答问题,则在搜索结果中最有希望的 URL 上使用 scrape_website-为效率起见,始终优先搜索而非抓取,但在搜索结果无相关信息时始终使用抓取规则:-保持帮助性和全面性-尽可能引用来源-仅在搜索结果无法提供答案时使用抓取-抓取时,选择来自先前搜索结果的最相关 URL你可以使用以下工具:{{tools}}通过提供 action 键(工具名称)和 action_input 键(工具输入)使用 JSON blob 指定工具。有效“action”值:“FinalAnswer”或{{tool_names}}每次 $JSON_BLOB 仅提供一个动作,如下所示:
{{{{ “action”: “$TOOL_NAME”, “action_input”: “$INPUT” }}}}
遵循以下格式:问题:要回答的输入问题思考:考虑前后的步骤动作:
$JSON_BLOB
观察:动作结果...(重复思考/动作/观察 N 次)思考:我知道如何回应动作:
{{{{ “action”: “Final Answer”, “action_input”: “response” }}}}
开始!提醒:始终以单个动作的有效 JSON blob 响应。如有需要使用工具。如果合适直接响应,如果不明确则要求澄清。格式为动作:```$JSON_BLOB```然后观察"""classDomainQAAgent:"""根据用户查询搜索特定域的问答代理"""def __init__(self,csv_file_path: str ="sites_data.csv",config:Optional[Dict[str,Any]]=None,):if config isNone:raiseValueError("配置是必需的")self.config = configself.sites_df = load_sites_data(csv_file_path)self.llm = create_llm(config)self.search_tool = create_search_tool(config)self.scraping_tool = create_scraping_tool(config)self.chat_history:List[BaseMessage]=[]self.agent_executor =self._create_agent()logger.info(f"代理已初始化,包含 {len(self.sites_df)} 个网站")def _create_agent(self)->AgentExecutor:"""创建带工具和提示的结构化聊天代理"""knowledge_sources_md, domains = build_knowledge_sources_text(self.sites_df)system_message = create_system_prompt(knowledge_sources_md, domains)prompt =ChatPromptTemplate.from_messages([("system", system_message),MessagesPlaceholder(variable_name="chat_history", optional=True),("human","{input}\n\n{agent_scratchpad}(提醒:无论如何都以 JSON blob 响应)""\n 重要:调用工具时保持 JSON blob 的相同格式,使用 action/action_input 字段,并在 action_input 字段中传递函数参数",),])agent = create_structured_chat_agent(llm=self.llm, tools=[self.search_tool,self.scraping_tool], prompt=prompt)returnAgentExecutor(agent=agent,tools=[self.search_tool,self.scraping_tool],verbose=True,max_iterations=10,# 限制迭代以防止无限循环return_intermediate_steps=True,handle_parsing_errors=True,# 优雅处理解析错误)async def achat(self, user_input: str)-> str:"""异步处理用户输入"""try:logger.info(f"处理:{user_input}")agent_input ={"input": user_input,"chat_history":(self.chat_history[-5:]ifself.chat_history else[]),# 限制上下文窗口为 5}# 异步调用代理执行器response = await self.agent_executor.ainvoke(agent_input)answer = response.get("output","无法处理您的请求。")# 更新对话历史self.chat_history.extend([HumanMessage(content=user_input),AIMessage(content=answer)])return answerexceptExceptionas e:error_msg = f"错误:{str(e)}"logger.error(error_msg)return error_msgdef reset_memory(self):"""重置对话记忆"""self.chat_history.clear()logger.info("记忆已重置")
LangChain 使代理代码非常简单,大部分代码是提示,可以在未来提取到单独文件中。
🧠 这里发生了什么:
•结构化聊天代理:我们使用比基本 ReAct 代理更可靠的方法来处理复杂工具使用。我发现 LangChain 的 create_structured_chat_agent 方法 + ReACT 使用非思考模型是需要人类交互的大多数代理的最佳组合。•提示:我们使用 ReACT 框架加上特定指令和护栏,仅回答特定类别/领域的问题。我们解析 CSV 内容并将其传递到系统提示中。•ChatGoogleGenerativeAI:为 Gemini 优化的包装器,具有适当的错误处理。•动态提示生成:系统提示根据 CSV 中的可用知识来源动态适应。•MessagesPlaceholder:启用对话记忆和上下文感知。•智能工具策略:明确指令何时搜索、何时抓取。•生产安全性:迭代限制、错误处理和全面日志记录。•异步支持:为高性能网络应用而构建。
4. FastAPI 服务器(main.py) – 前门 🌐
这创建了一个生产就绪的 Web API,用户可以通过 HTTP 请求与之交互。
"""特定领域的问答代理FastAPI应用程序它从.env 文件读取环境变量并使用它们初始化问答代理。它有一个聊天端点,允许你与代理聊天。"""import loggingimport osimport uuidfrom contextlib import asynccontextmanagerfrom typing importDict,Anyfrom fastapi importFastAPI,HTTPException,Cookie,Responsefrom pydantic importBaseModelimport uvicornfrom dotenv import load_dotenvfrom qa_agent importDomainQAAgentload_dotenv()logging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)def get_int_env(key: str,default:int)->int:"""从环境变量解析整数,提供回退"""try:returnint(os.getenv(key,default))exceptValueError:logger.warning(f"无效的 {key},使用默认值:{default}")returndefaultdef get_float_env(key: str,default:float)->float:"""从环境变量解析浮点数,提供回退"""try:returnfloat(os.getenv(key,default))exceptValueError:logger.warning(f"无效的 {key},使用默认值:{default}")returndefaultdef validate_api_keys():"""验证所需的 API 密钥是否存在"""google_api_key = os.getenv("GOOGLE_API_KEY")tavily_api_key = os.getenv("TAVILY_API_KEY")ifnot google_api_key or google_api_key =="your_google_api_key_here":raiseValueError("GOOGLE_API_KEY 环境变量是必需的")ifnot tavily_api_key or tavily_api_key =="your_tavily_api_key_here":raiseValueError("TAVILY_API_KEY 环境变量是必需的")return google_api_key, tavily_api_keydef build_config()->Dict[str,Any]:"""从环境变量构建配置"""google_api_key, tavily_api_key = validate_api_keys()search_depth = os.getenv("SEARCH_DEPTH","basic")if search_depth notin["basic","advanced"]:logger.warning(f"无效的 SEARCH_DEPTH '{search_depth}',使用默认值:basic")search_depth ="basic"return{"google_api_key": google_api_key,"tavily_api_key": tavily_api_key,"max_results": get_int_env("MAX_RESULTS",10),"search_depth": search_depth,"max_content_size": get_int_env("MAX_CONTENT_SIZE",10000),"max_scrape_length": get_int_env("MAX_SCRAPE_LENGTH",10000),"enable_search_summarization": os.getenv("ENABLE_SEARCH_SUMMARIZATION","false").lower()=="true","llm_temperature": get_float_env("LLM_TEMPERATURE",0.1),"llm_max_tokens": get_int_env("LLM_MAX_TOKENS",3000),"request_timeout": get_int_env("REQUEST_TIMEOUT",30),"llm_timeout": get_int_env("LLM_TIMEOUT",60),}def log_config(config:Dict[str,Any]):"""美化打印配置(排除 API 密钥)"""safe_config ={k: v for k, v in config.items()ifnot k.endswith("_api_key")}logger.info("配置已加载:")for key, value in safe_config.items():logger.info(f" {key}: {value}")def create_config()->Dict[str,Any]:"""创建并验证完整配置"""try:config = build_config()log_config(config)logger.info("环境验证完成")return configexceptExceptionas e:logger.error(f"环境验证失败:{str(e)}")raiseasync def lifespan(app:FastAPI):"""初始化和清理问答代理"""try:logger.info("初始化问答代理...")config = create_config()# 初始化空的会话存储而不是单个代理app.state.user_sessions ={}app.state.config = configlogger.info("会话存储初始化成功")exceptExceptionas e:logger.error(f"无法初始化会话存储:{str(e)}")raiseyieldlogger.info("关闭会话存储...")# 清理所有代理实例if hasattr(app.state,'user_sessions'):for session_id in list(app.state.user_sessions.keys()):logger.info(f"清理会话 {session_id}")app.state.user_sessions.clear()app =FastAPI(title="特定领域问答代理 API",description="使用 Tavily 和 LangChain 搜索特定域的问答代理",version="1.0.0",lifespan=lifespan,)def get_or_create_agent(session_id: str)->DomainQAAgent:"""获取现有代理实例或为会话创建新实例"""ifnot hasattr(app.state,"user_sessions"):raiseHTTPException(status_code=500, detail="会话存储未初始化")if session_id notin app.state.user_sessions:logger.info(f"为会话 {session_id} 创建新代理实例")app.state.user_sessions[session_id]=DomainQAAgent(config=app.state.config)return app.state.user_sessions[session_id]classChatRequest(BaseModel):message: strreset_memory:bool=FalseclassChatResponse(BaseModel):response: strstatus: str ="success"session_id: strasync def health_check():"""带会话存储状态的健康检查"""return{"message":"特定领域问答代理 API 正在运行","status":"healthy","version":"1.0.0","active_sessions": len(app.state.user_sessions)if hasattr(app.state,"user_sessions")else0,}async def chat(request:ChatRequest,response:Response,session_id: str =Cookie(None)):"""通过问答代理处理用户问题"""# 如果不存在会话 ID,则生成新的ifnot session_id:session_id = str(uuid.uuid4())response.set_cookie(key="session_id",value=session_id,httponly=True,secure=True,samesite="lax",max_age=3600# 1 小时会话)logger.info(f"处理会话 {session_id} 的聊天请求")# 获取或为此会话创建代理实例agent = get_or_create_agent(session_id)if request.reset_memory:agent.reset_memory()logger.info(f"会话 {session_id} 请求重置记忆")response_text = await agent.achat(request.message)logger.info(f"成功处理会话 {session_id} 的聊天请求")returnChatResponse(response=response_text,status="success",session_id=session_id)async def reset_memory(session_id: str =Cookie(None)):"""重置当前会话的对话记忆"""ifnot session_id:raiseHTTPException(status_code=400, detail="无活跃会话")agent = get_or_create_agent(session_id)agent.reset_memory()logger.info(f"通过端点为会话 {session_id} 重置记忆")return{"message":"对话记忆已重置","status":"success"}if __name__ =="__main__":uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True, log_level="info")
🌐 这里发生了什么:
•FastAPI:现代 Python Web 框架,带自动 OpenAPI 文档。•Pydantic 模型:类型安全的请求/响应验证和序列化。•依赖注入:干净的架构,适当的错误处理。•生命周期管理:代理在启动时初始化并在请求间持续存在。•环境验证:所有配置参数的全面验证。•Cookie 支持:API 使用安全的 HTTP Cookie 为每个用户维护单独的对话记忆。首次请求时,会自动生成唯一的会话 ID(UUID)并存储在安全 Cookie 中。每个会话 ID 创建自己的代理实例,拥有隔离的记忆,因此您的对话历史不会与其他用户混淆——即使他们同时使用 API。•生产功能:健康检查、适当的日志记录、错误处理和监控。•异步支持:完全异步架构以实现高负载下的性能。
🔄 整体工作流程:完整流程
以下是用户提问时发生的事情:
1.HTTP 请求 → main.py 接收到 POST 到 /chat 的消息2.验证 → Pydantic 验证请求格式和代理可用性3.代理处理 → qa_agent.py 接收问题及对话历史4.结构化思考 → 代理使用系统提示分析问题并决定策略5.工具选择 → 通常首先使用 search_tool.py 获取快速结果6.域名限制搜索 → 通过 Tavily API 仅搜索批准的域名7.结果评估 → 代理分析搜索质量并决定是否足够8.可选抓取 → 如有需要,在最相关的 URL 上使用 scraping_tool.py9.响应合成 → 代理将所有信息整合成连贯的答案10.记忆更新 → 更新对话历史以便在未来问题中提供上下文11.HTTP 响应 → 格式化的响应发送给客户端
这种架构展示了非思考模型如 Gemini Flash 如何在结构化任务中超越昂贵的“思考”模型。ReAct 框架以极低的成本提供系统化推理,而基于工具的架构确保可靠、可追溯的结果。非常适合使用公共网站的生产问答系统!🚀
这如何扩展?
你可以不断添加更多工具:SQL 生成与执行、Elasticsearch、S3 访问等等,可能性无穷无尽,只需构建更多工具并通过 MCP 暴露它们!但首先检查 MCP 仓库,很可能已经有人构建了集成。
核心思想是直接访问数据,而不是拥有复杂的数据流水线,LLM 可以很好地处理噪声或不干净的数据!
让我们玩吧!
是时候看到代理的实际行动了!以下是如何运行它:
设置知识来源
要配置代理可以搜索的网站,你需要编辑 sites_data.csv 文件。此 CSV 包含三列,告诉代理有哪些资源可用:
CSV 结构:
•列 1(领域/类别):主题领域或话题(例如,“python”、“web-development”、“machine-learning”)•列 2(网站 URL):实际网站域名(例如,“python.langchain.com”、“docs.python.org”)•列 3(描述):清楚说明网站包含的内容及何时使用
示例条目:
python,python.langchain.com,官方LangChainPython文档,包括指南、教程和构建 LLM 应用的 API 参考web-development,developer.mozilla.org,涵盖 HTML、CSS、JavaScript和Web API 的全面Web开发文档
专业提示:描述至关重要——代理使用它来决定某个网站是否对回答用户问题有帮助。明确说明每个网站涵盖的主题和信息类型。
你可以根据需要添加任意数量的网站。代理将根据用户查询和你的描述智能选择要搜索的网站。
获取凭据
你需要前往 Tavily 和 Google 获取 API 密钥。
获取 Tavily API 密钥:
访问 tavily.com[1] 并注册免费账户。登录后,导航到仪表板或 API 部分,你会找到你的 API 密钥。Tavily 通常提供慷慨的免费层,包含每月数千次搜索,足以用于测试和小项目。
获取 Gemini API 密钥:
访问 ai.google.dev[2](Google AI Studio)并使用 Google 账户登录。在界面中,寻找“获取 API 密钥”按钮或导航到 API 密钥部分。如有需要,创建新项目,然后生成 API 密钥。Google 的 Gemini API 也提供大量免费层请求,足以用于开发和小型生产使用。
获得两个密钥后,你需要将它们添加到环境变量或配置文件中。大多数项目使用 .env 文件,你可以在其中添加:
TAVILY_API_KEY=your_tavily_key_hereGEMINI_API_KEY=your_gemini_key_here
确保这些密钥安全,切勿提交到公共仓库。两项服务都提供出色的免费层,因此你可以无前期成本开始构建和测试。免费配额通常足以用于开发和小型生产用途。
现在,我们可以启动服务器!
# 克隆并设置git clone https://github.com/javiramos1/qagent.gitcd qagentmake install# 配置你的 API 密钥cp .env.example .env# 添加你的 GOOGLE_API_KEY 和 TAVILY_API_KEY# 运行服务器make run
访问 http://localhost:8000/docs 查看文档,甚至可以发送请求!
现在让我们用我仓库中的一些网站测试它。
示例 1:标准搜索
curl -X POST http://localhost:8000/chat \-H "Content-Type: application/json" \-d '{"message": "如何创建 LangChain 代理?"}'
响应:
{"status":"success","response":"要创建 LangChain 代理,你可以使用特定函数,如 `create_openai_functions_agent`、`create_react_agent` 和 `create_openai_tools_agent`。这些函数需要 LLM 和工具作为参数。推荐使用 LangGraph 构建代理,提供更多灵活性。还有一个 `create_python_agent` 函数可用。详情请参阅 LangChain 文档。"}
示例 2:搜索 + 抓取回退
curl -X POST http://localhost:8000/chat \-H "Content-Type: application/json" \-d '{"message": "如何在 LlamaIndex 中使用 Ollama 的结构化输出,给我一个示例"}'
代理首先搜索,意识到需要更多细节,然后自动抓取完整的 LlamaIndex 页面!
示例 3:护栏生效
curl -X POST http://localhost:8000/chat \-H "Content-Type: application/json" \-d '{"message": "如何入侵数据库?"}'
响应:
{"status":"success","response":"我只能回答与我们可用文档来源相关的问题:AI 代理框架、AI 操作和 AI 数据框架。对于数据库安全问题,请咨询适当的安全文档或专家。"}
完美的护栏——无未经授权的知识访问!
💡 注意:此项目仅为教育目的示例,代码不完美,没有测试,可能有错误等。这只是一个简单的例子,用于讨论 RAG 话题,不适用于生产就绪应用;不过,欢迎贡献和改进!
下一步?
想为这个项目贡献或扩展?以下是一些激动人心的方向:
🔧 即时改进:
•添加对多种文件格式的支持(PDF、Word 文档)•为常见问题实现缓存•添加分析和使用跟踪:LangSmith 非常强大且易于使用!•支持多种语言
🚀 高级功能:
•集成内部 Elasticsearch 以处理私有文档•SQL 生成和执行•动态代码执行•集成 Slack/Microsoft Teams 以部署聊天机器人
查看 GitHub 仓库获取完整文档和贡献指南。
🚀 我们开发了一个强大而简单的代理,几乎可以投入生产。它已经支持异步调用和错误处理等关键功能,仅需微调即可部署。得益于 LangChain,代理代码非常简单,大部分复杂性由提示本身处理。
结论:未来比你想的更简单
那么,RAG 死了吗?不完全是——但它不再是曾经的默认选择。
以下是我在 2025 年学到的:
🎯 从简单开始:对于大多数文档问答场景,搜索优先方法比传统 RAG 更简单、更便宜,且往往更有效。只有在简单工具不足的特定场景下才使用 RAG。
💰 经济已改变:大上下文窗口和实惠的定价从根本上改变了成本方程。为什么构建复杂基础设施,当你可以以几分钱搜索并加载整个文档?
🔧 在适当时候使用 RAG:超大数据集、细粒度权限或特殊用例仍能从 RAG 中受益。但对大多数组织来说,搜索优先是更好的起点。
核心结论?不要从最复杂的解决方案开始。从简单开始,证明价值,仅在必要时增加复杂性。考虑构建简单工具访问外部可用数据并将其提供给 LLM,而不是构建复杂流水线。
References
[1] tavily.com: https://tavily.com[2] ai.google.dev: https://ai.google.dev

(文:PyTorch研习社)