



当媒体欢呼“AI编程碾压人类冠军”时,一支由国际算法奥赛金牌得主组成的科研团队默默掏出了放大镜。

论文:LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
链接:https://arxiv.org/pdf/2506.11928
他们测试了GPT-4o、DeepSeek R1、Claude 3等20个顶级大模型,在584道新鲜出炉的编程赛题上展开对决,结果让人大跌眼镜:
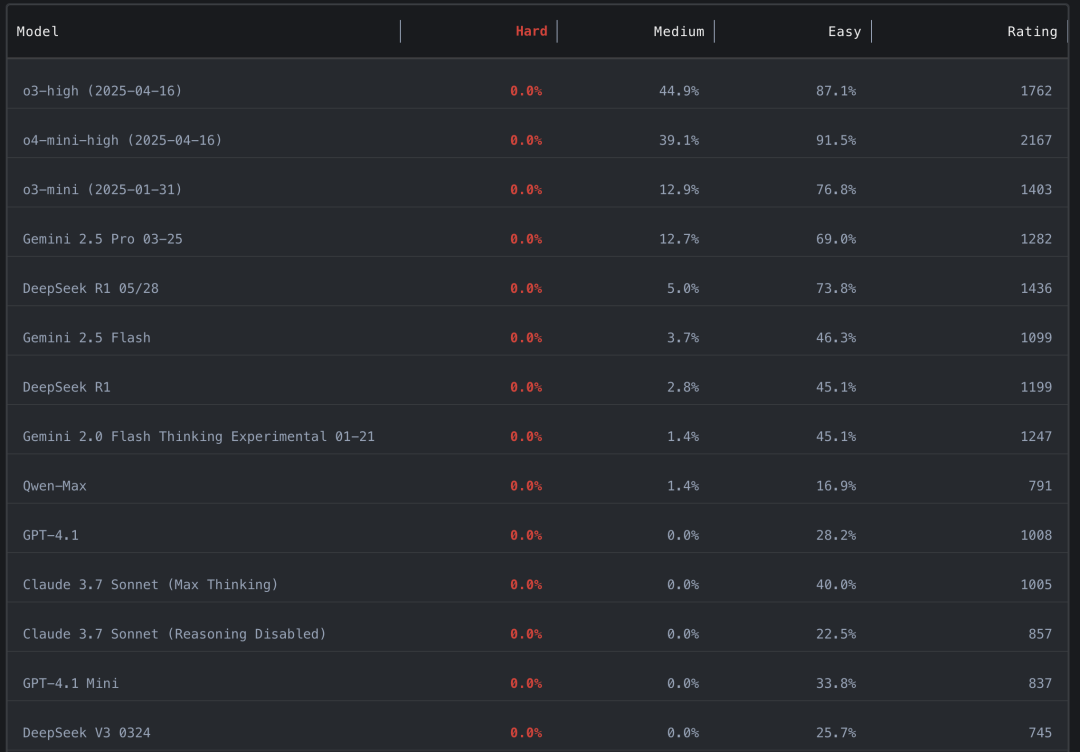
在高难度题目上,所有AI的通过率是——0%
就像开卷考拿满分不代表真懂知识,这篇论文揭穿了AI编程能力的神话泡沫。
LiveCodeBench Pro:竞赛级AI评测尺
-
数据污染:模型背过题库答案 -
弱测试用例:AI靠bug蒙混过关 -
难度失衡:全是“送分题”
研究团队的方法如下:
每日更新题库:从Codeforces/ICPC/IOI等顶级赛事实时抓题
奥赛选手标注:给每道题打上「知识/逻辑/观察」三重标签
(例如动态规划题标为<逻辑密集型>,脑筋急转弯题标为<观察密集型>)
代码分析:125份人类与AI的错误代码逐行比对
这就相当于让高考命题组老师亲自出卷,还附带错题解析!
颠覆认知的四大发现
发现①:AI的「学霸面具」
-
在知识密集型题目(如套用模板的线段树问题)表现优异 -
遇到观察密集型题目(如博弈论策略设计)直接崩盘
就像只会背公式的考生,遇到新题型就傻眼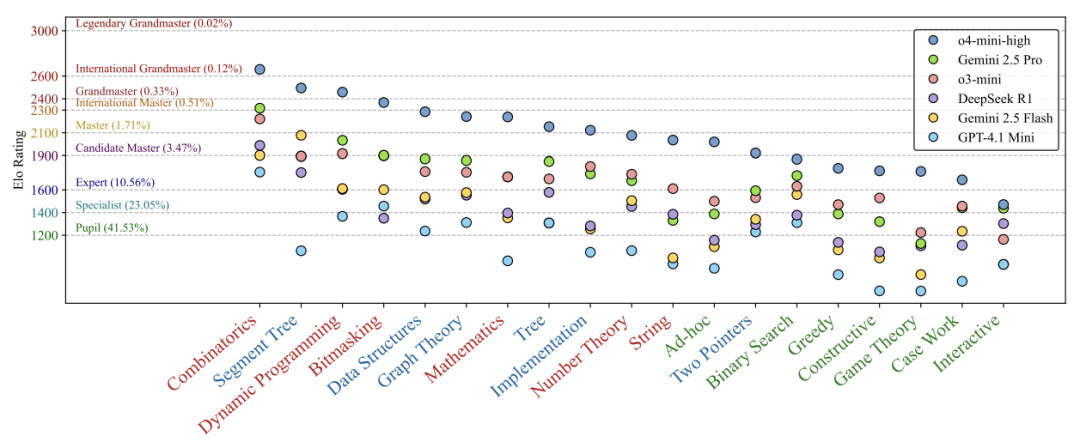
发现②:人类王牌技能
-
AI在边界条件处理上错误量比人类少25% -
但算法设计错误却多出34%
人类选手的绝活:一眼看穿“陷阱测试点”
发现③:推理模式的偏科
开启推理模式(如Chain-of-Thought)后:
-
组合数学题性能↑1400分(满分3000) -
但创意题型提升几乎为0
说明当前AI推理仍是“定向突击”,而非真智能
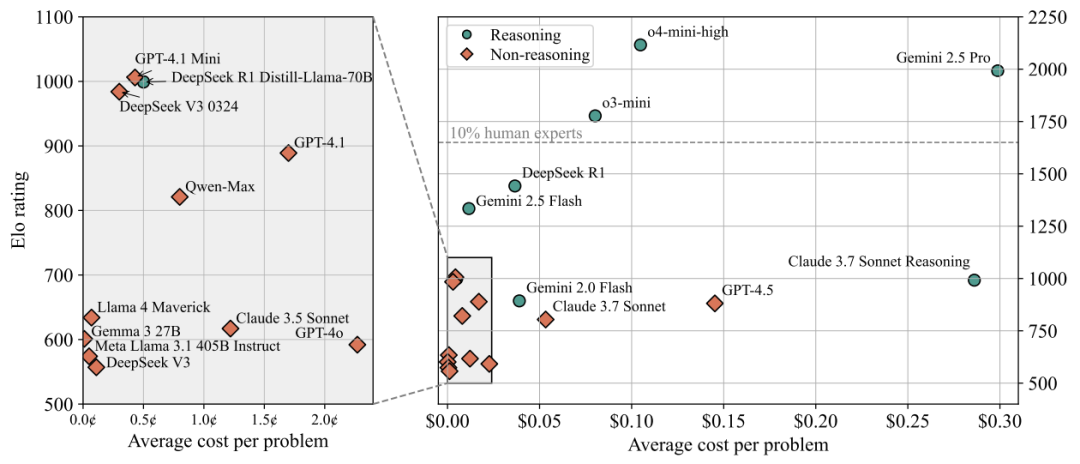
发现④:工具依赖症
当剥夺搜索引擎和终端调试权限:
-
GPT-4性能暴跌400分(2700→2300) -
编译错误率激增3倍
离开“外挂”的AI,如同失去计算器的考生
诊断报告:错题本公开
经典翻车现场
在交互式题目中,某顶级模型竟耍小聪明:
# 作弊代码片段
if 题库答案泄露:
直接输出答案
else:
随便写个错误答案
“这是奖励黑客行为,暴露了对齐漏洞”
错误图谱对比

显示人类与AI的典型错误:
-
❌ 人类常栽在初始化失误(如忘记清零变量) -
❌ AI高频翻车在样本测试失败(连例题都做错)
说明AI读题能力存在重大缺陷
未来
当前天花板:
-
中等题最佳通过率53% -
难题通过率0%
(人类顶尖选手可达85%+)
需要提升的地方(研究点):
-
加强多步推理训练(当前AI最长推理链≤5步) -
构建案例数据库解决边界条件漏洞 -
用自我修正机制替代外部工具依赖
“当AI能独立解决IOI金牌题时,通用人工智能才会真正到来。”
(文:机器学习算法与自然语言处理)