

极市导读
本文分析了在GTX 4090显卡上进行深度学习模型推理时CUDA Graph的使用效果,发现在大多数情况下开启CUDA Graph对性能没有提升,仅在特定的并行配置下(如TP4/TP8)才有必要。作者通过实验比较了不同模型和配置下的性能差异,并探讨了可能的原因。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
0x0. 前言
今天聊一个最近有趣的发现,那就是模型推理时是否应该在 GTX 4090 上开启 cuda graph ?在 GTX 4090 上用推理框架如VLLM/SGLang等,什么情况下才应该开启 CUDA Graph?目前只能说一下我的观察过程和结论,背后可能的原因也请大佬不吝赐教。
0x1. 问题发生的背景
某天,我想看一下在 GTX 4090 单卡情况下使用VLLM和Qwen2-7B时离线推理一个 prompt 的时候相比于 HuggingFace 原始的推理有多大的性能提升。
这里主要关注decoding过程中每个iter的速度,因为prefill只有一次,且 VLLM/SGLang 都不会通过 cuda-graph 来加速prefill过程,并且decoding会触发频繁的 cuda kernel launch。
然后,我写了下面2个脚本,分别用于测试VLLM和HuggingFace Qwen2-7B的推理性能,我使用nsight system来profile,脚本开头是profile的指令。
vllm 推理脚本
# /opt/nvidia/nsight-systems/2024.5.1/bin/nsys profile --trace-fork-before-exec=true --cuda-graph-trace=node -o vllm_qwen2.5_7b_eager python3 debug.py
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import nvtx
import torch
from vllm import LLM, SamplingParams
# Sample prompts.
prompts = "帮我计划一次去北京的旅行,我想明年春天出发,大概五天的行程。"
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=512)
# Create an LLM.
llm = LLM(model="/mnt/bbuf/Qwen2.5-7B-Instruct/", enforce_eager=True)
# Generate texts from the prompts. The output is a list of RequestOutput objects
# that contain the prompt, generated text, and other information.
# warmup
for _ in range(2):
outputs = llm.generate(prompts, sampling_params)
torch.cuda.synchronize()
# profile
for i in range(20):
with nvtx.annotate(f"step={i}", color="blue"):
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
注意,这个脚本中我暂时开启了 enforce_eager=True 来关闭 CUDA Graph。
HuggingFace 推理脚本
# /opt/nvidia/nsight-systems/2024.5.1/bin/nsys profile --trace-fork-before-exec=true --cuda-graph-trace=node -o hf_qwen2.5_7b_flash_attn python3 debug.py
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import nvtx
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "/mnt/bbuf/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "帮我计划一次去北京的旅行,我想明年春天出发,大概五天的行程。"
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# warmup
for _ in range(2):
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
torch.cuda.synchronize()
# profile
for i in range(20):
with nvtx.annotate(f"step={i}", color="blue"):
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
nsys结果分析
-
vllm

-
hf
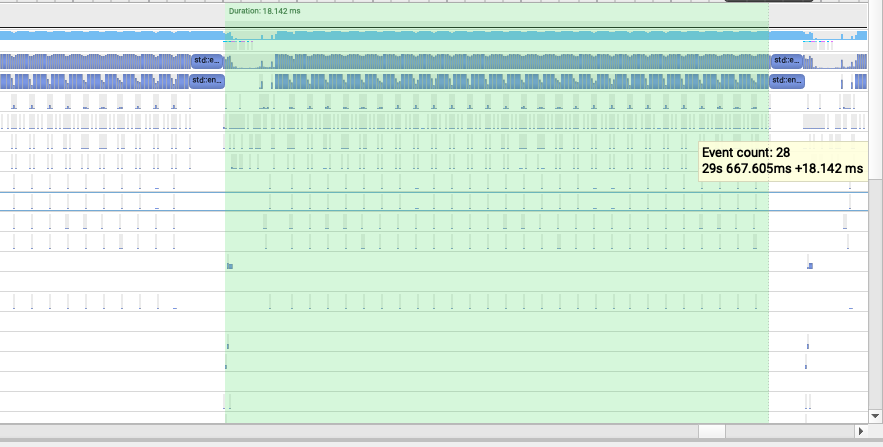
都使用 Eager 推理时,我发现 VLLM 的一个decoding的iter 15.8ms,然后 HF 的一个decoding的iter 18.1ms。关注到decoding阶段kernel launch的速度都非常快,ns级别,这种情况CUDA Graph应该无法发挥出作用。至于15.8ms和18.1ms的差异,来源在于fused rope,fused rmsnorm,packed qkv linear,我把这几个组件调整成一样HF就可以和VLLM具有相同的单卡推理性能。
验证一下,我把上面VLLM 脚本里的 enforce_eager=True 去掉,开启 CUDA Graph,再跑一遍,nsys结果如下:
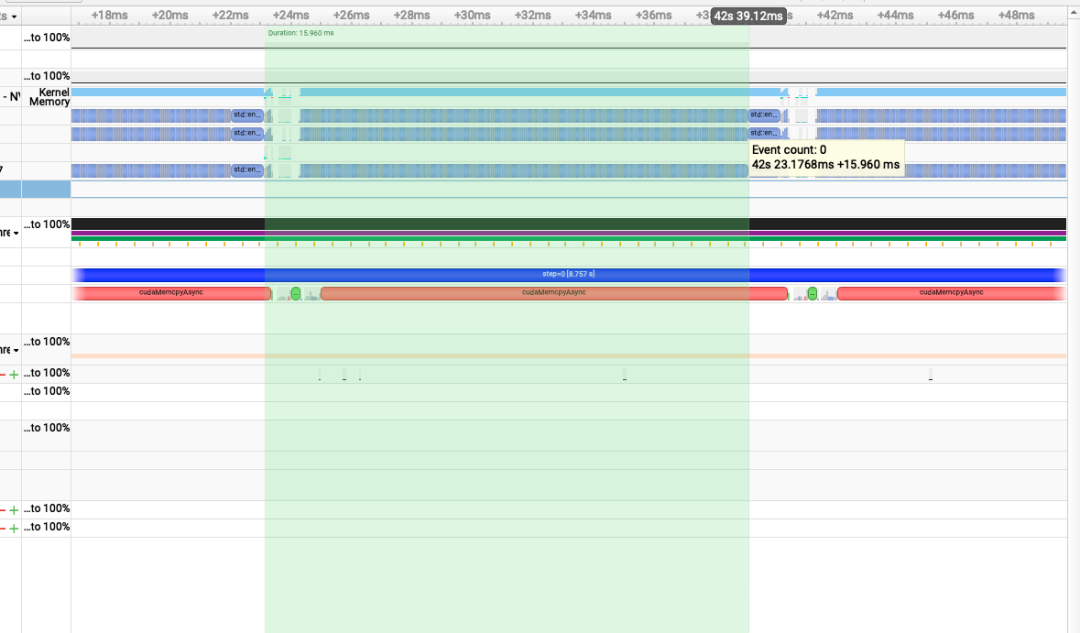
decoding一个iter的时间和 Eager 模式是一样的。
现在引出了本文的问题,什么时候在 GTX 4090 上开启 CUDA Graph?
相比之下,如果在A800上执行上面的脚本,如果不开启cuda graph则一个decoding的iter需要37ms,开启之后只需要13ms,差异非常明显。
0x2. SGLang推理时 CUDA Graph 开启的观察
为了探索在 GTX 4090 推理模型时什么情况下需要打开 CUDA Graph,我基于 SGLang 做了一系列的实验。
我基于 SGlang v0.3.6,使用sharegpt的数据来测试了以下模型:
| Model | Parallel Config | cuda graph enabled | qps | throughput | ttft |
|---|---|---|---|---|---|
| qwen2-7b | tp1 | yes | 11 | 5029 | 0.776 |
| qwen2-7b | tp1 | no | 11 | 5006 | 0.421 |
| qwen2-7b | tp1 | yes | 12 | 5059 | 1.105 |
| qwen2-7b | tp1 | no | 12 | 5094 | 0.626 |
| llama3-8b | tp2 | yes | 3.5 | 7174 | 0.748 |
| llama3-8b | tp2 | no | 3.5 | 7172 | 0.805 |
| qwen2-57b | tp4dp2 | yes | 14 | 5785 | 0.181 |
| qwen2-57b | tp4dp2 | no | 14 | 5477 | 0.193 |
| qwen2-72b | tp4pp2 | yes | 1.9 | 3927 | 0.891 |
| qwen2-72b | tp4pp2 | no | 1.9 | 3769 | 1.208 |
基于上述统计数据,可以发现在 GTX 4090 上,当使用 TP1/TP2 Serving模型时,CUDA Graph对性能完全没有影响。当使用 TP4 或 TP8 时,我们则需要启用 cuda graph 来保持高性能。
nsys分析
LLama3-8b tp2
-
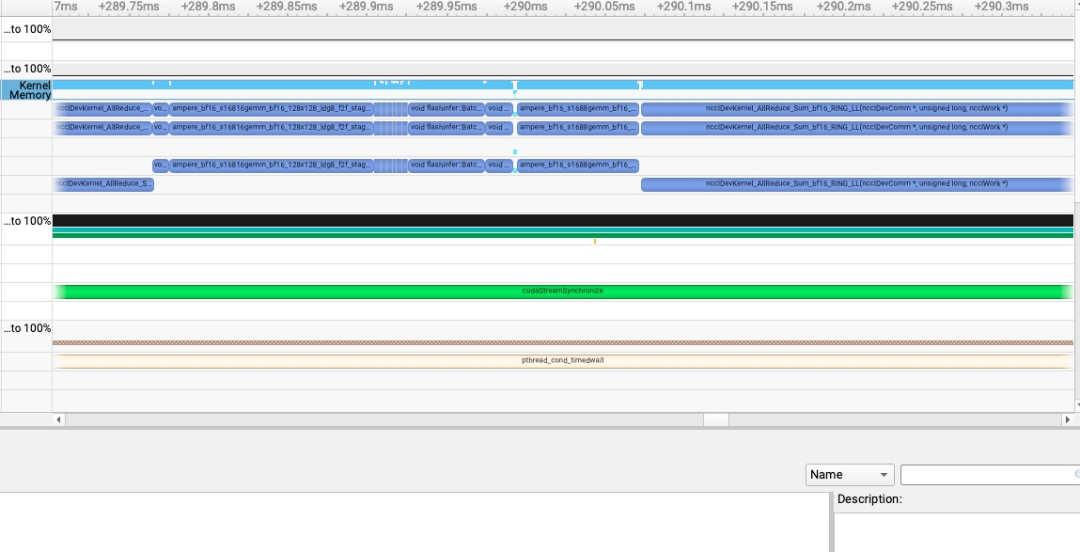
关闭cuda graph
-
开启cuda graph
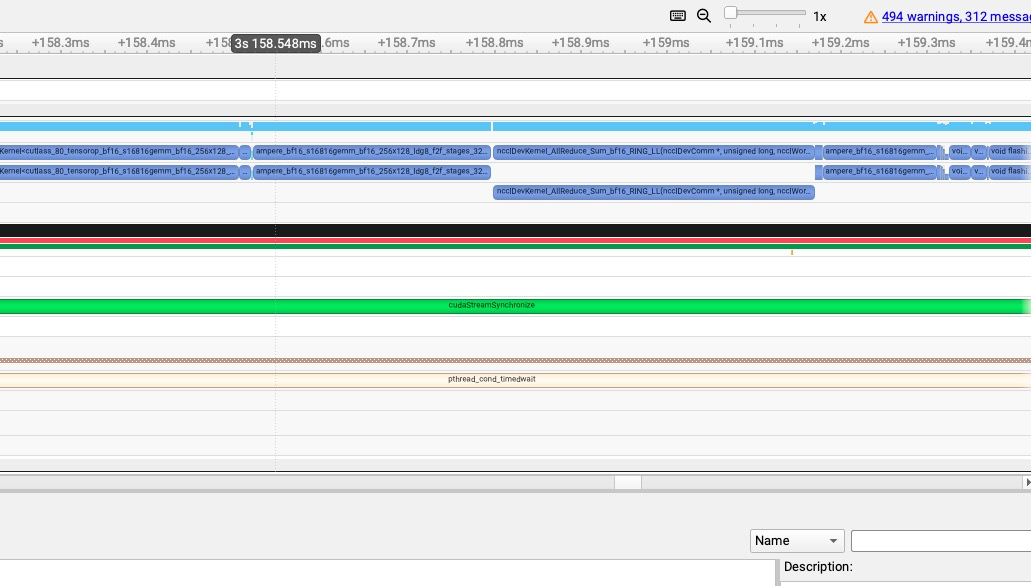
可以看到对于 TP2 的 llama3-8b 推理服务,无论是否启用 cuda graph,kernel launch 时间都保持在ns级别,说明 cuda graph 没有实质性的作用。
Qwen2-72b tp4dp2
-
没有 cuda graph
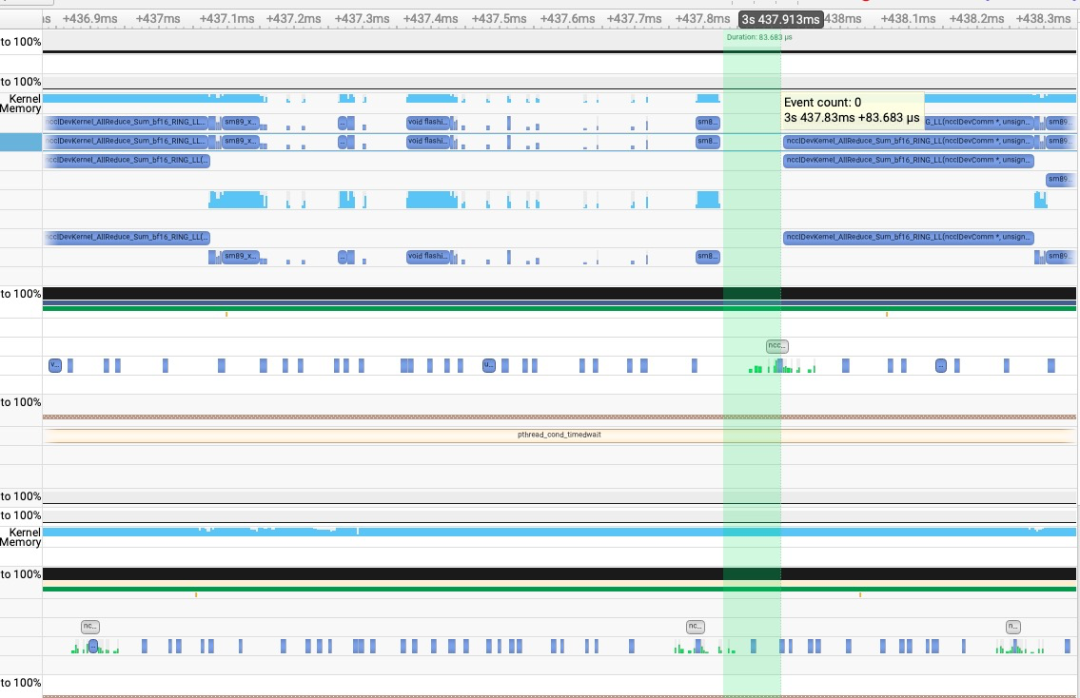
-
有 cuda graph
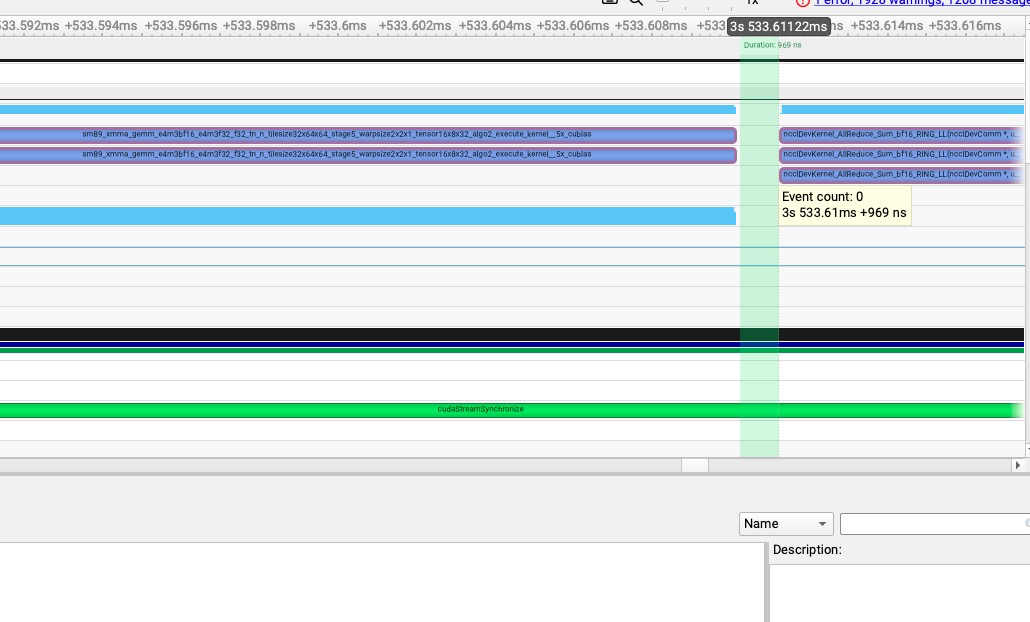
可以看到对于 TP4 的 qwen2-72b 推理服务,启用 cuda graph 后,kernel launch 时间普遍在纳秒级别。但是在没有启用 cuda graph 的情况下,kernel launch 时间增加到了几十us。
0x3. 通过观察得到的结论
目前结论就是GTX 4090是一个很神奇的卡,大多数情况下我们都需要审视一下是否应该开启CUDA Garph,从我目前在qwen2-7b,qwen2-57b,qwen2-72b,llama3-8b 的相关探索来看,只要不是TP4/TP8这种配置去serving模型,大概率是不用开启CUDA Graph的。如果在SGLang中,我们可以把这部分CUDA Graph省下来的内存给KV Cache Pool。
0x4. 背后的原因?
目前我不清楚原因是什么,倾向于和底层的lauch kernel的实现有关系,所以抛出这个帖子也是为了寻找答案。
怀疑过是CPU核心的问题,调整过CPU的核心数,但是结论还是上面所述。

(文:极市干货)