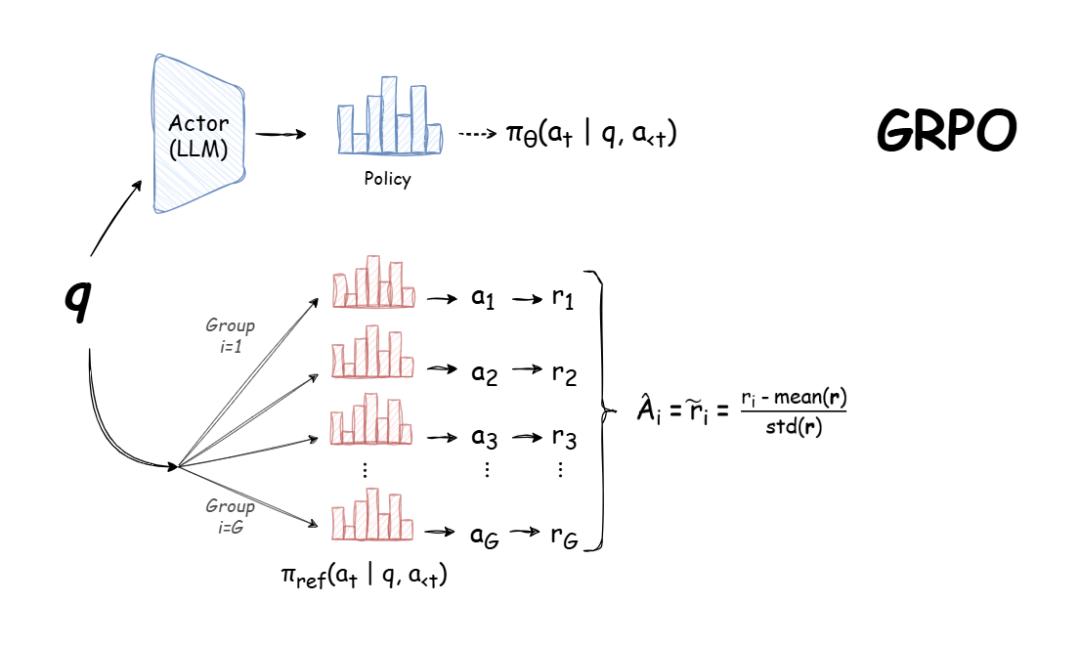
DeepSeek用的GRPO占用大量内存?有人给出了些破解方法 2025年2月7日16时 作者 机器之心 选自oxen.ai 作者:Greg Schoeninger 编译:陈陈、泽南 RTX 3080 移动版能训练哪种大模型?本文为那些 GPU 资源有限时使用 GRPO 训练的开发者提供了宝贵的指导。 自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。 GRPO 是一种在线学习算法(online learning algorithm),它通过使用训练过程中由训练模型自身生成的数据来进行迭代改进。GRPO 的目标是最大化生成补全(completions)的优势函数(advantage),同时确保模型保持在参考策略(reference policy)附近。 本文的目的是帮你节省一些时间,让你根据硬件预算选择合适的模型大小。在开始微调时,你必须做出的重要决定是选择模型大小,以及你是执行完全微调还是参数高效微调(PEFT)。 文章作者来自 AI 公司 Oxen.ai 的 CEO Greg Schoeninger。 (文:机器之心)