
项目简介
本项目目标是重现 DeepSeek R1 训练方案,特别是针对文本到图的信息提取。
该项目基于 Hugging Face Open-R1 和 trl 构建并受到启发
结构
该项目目前包括以下组件:
-
src包含使用 GRPO 或监督学习训练模型以及数据生成脚本的脚本。 -
grpo.py– 使用 GRPO 训练模型,提供与文本到图相关的奖励函数; -
train_supervised.py– 在监督模式下训练用于文本到图提取的模型 -
generate.py– 生成思考链,提供输入文本和提取的 JSON
流程
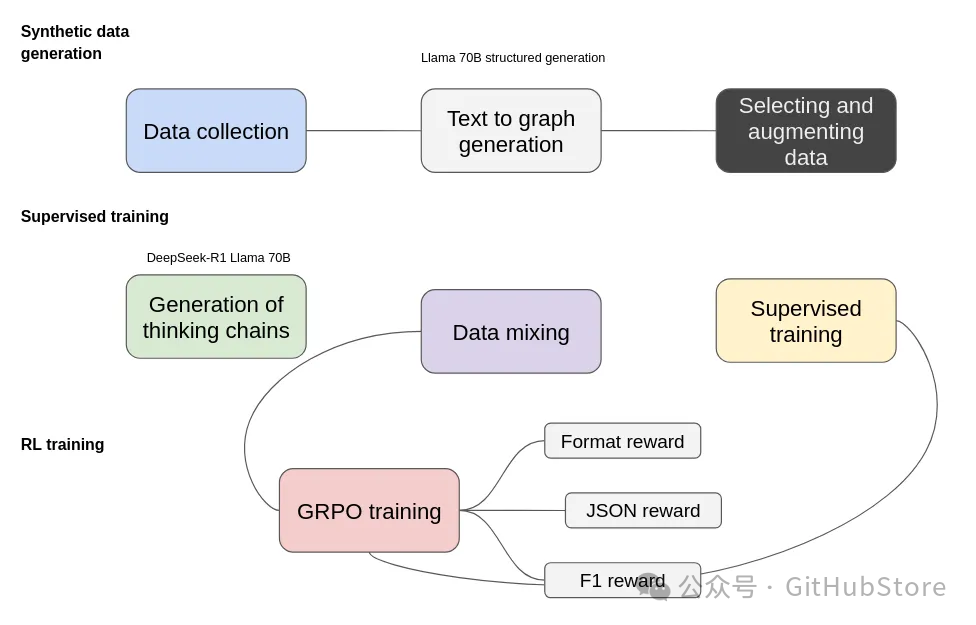
训练过程包括三个主要阶段:合成数据生成、监督训练和强化学习(RL)训练。这些阶段中的每一个都在提高模型进行结构化信息提取的能力方面发挥着关键作用。
-
合成数据生成
为了启动这个过程,我们首先从数据收集开始,收集与我们的目标领域相关的各种文本来源。由 Llama 70B 结构化生成驱动的文本到图生成步骤,将非结构化文本转换为基于图的表示。然而,这一步骤并不完美,因此选择和增强数据变得至关重要,以过滤掉低质量的提取,并丰富数据集以包含更多样化的结构。
此外,我们使用结构化预测 JSON 数据生成输入,并将这些输入和文本输入到 DeepSeek-R1 Llama 70B 中,以生成可以解释提取过程的思维链。
我们尝试了启用和禁用思维模式的两种模式,并发现小型模型难以发现一些有趣且重要的思维策略。
-
监督训练
在开始强化学习并考虑到我们使用小型模型的情况下,需要额外的监督训练来推动模型返回数据以正确的格式,我们为此只使用了 1k 个示例。
-
强化学习与 GRPO
监督训练本身并不能完全解决问题,尤其是在对预定义实体和关系类型进行条件化模型输出时。为了解决这个问题,我们采用组相对策略优化(GRPO)进行强化学习。
-
格式奖励确保输出遵循结构化格式,其中思维被封装在相应的标签中(在思维模式下)。
-
JSON 奖励特别验证了良好的、机器可读的 JSON 表示形式,并且其结构符合期望的格式。
-
F1 奖励通过将提取的实体和关系与真实图进行比较来评估它们的准确性。
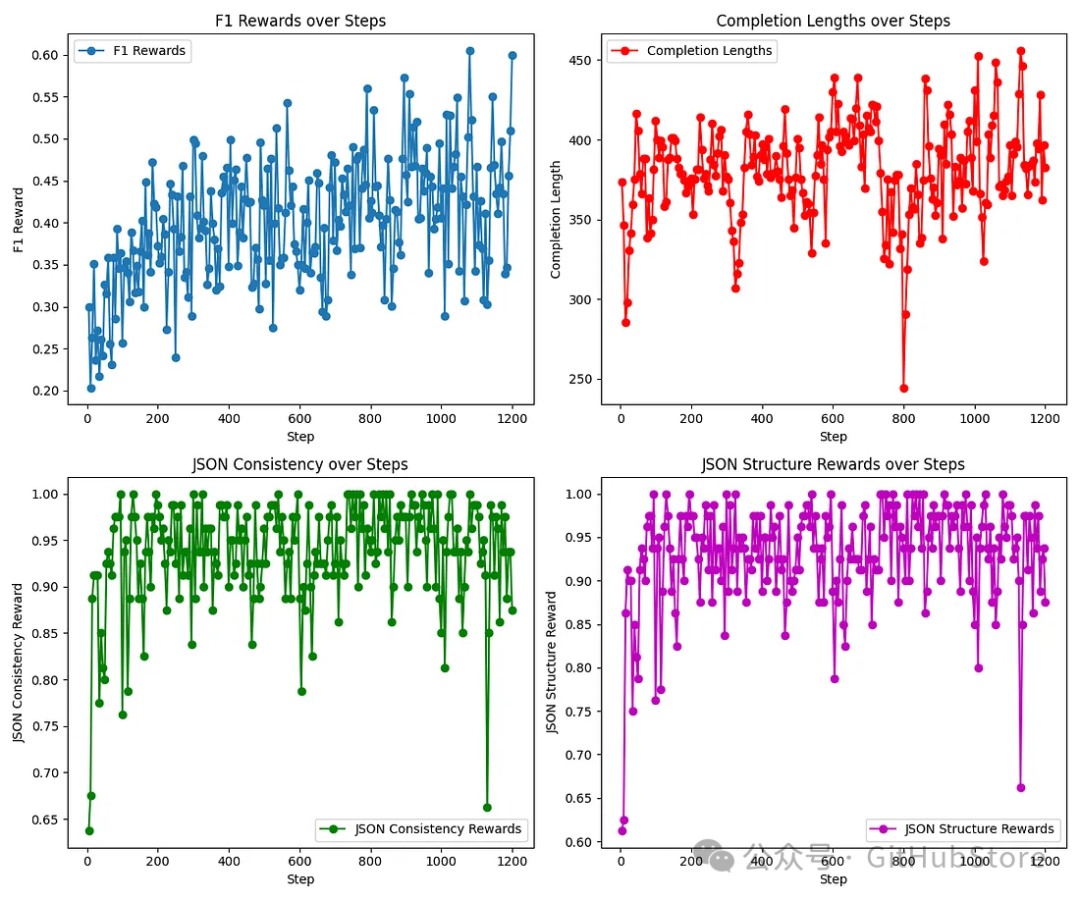
以下您可以看到,在我们的实验中,不同的奖励如何随着训练步骤的变化而变化。
尝试模型
您可以尝试使用此框架中的一个微调模型。
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "Ihor/Text2Graph-R1-Qwen2.5-0.5b"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto")tokenizer = AutoTokenizer.from_pretrained(model_name)text = """Your text here..."""prompt = "Analyze this text, identify the entities, and extract meaningful relationships as per given instructions:{}"messages = [{"role": "system", "content": ("You are an assistant trained to process any text and extract named entities and relations from it. ""Your task is to analyze user-provided text, identify all unique and contextually relevant entities, and infer meaningful relationships between them""Output the annotated data in JSON format, structured as follows:\n\n""""{"entities": [{"type": entity_type_0", "text": "entity_0", "id": 0}, "type": entity_type_1", "text": "entity_1", "id": 0}], "relations": [{"head": "entity_0", "tail": "entity_1", "type": "re_type_0"}]}""")},{"role": "user", "content": prompt.format(text)}]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
项目链接
https://github.com/Ingvarstep/open-r1-text2graph
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)