
今天是2025年02月13日,星期四,北京,天气晴。
我们继续来看GraphRAG进展。看用于Agent的一个思路。
随着多智能体系统变得更加复杂,包含大规模工具、API或作为工具的代理,工具通常对其他工具有依赖性,无论是其效用函数、填写参数所需的必要工具,还是类操作系统工具。所以,可以使用基于知识图谱来组织Agent的一个方案,这其实使用RAG来做工具查找。
专题化,体系化,会有更多深度思考。大家一起加油。
一、用Graph来约束agent的思路Graph RAG-Tool
传统的RAG方法在表示工具之间的结构化依赖方面存在局限性,限制了工具检索的准确性。所以,这块的确可以使用图的方式来改善。
例如,在一个向量数据库的工具中,“获取股票价格”的API需要来自“获取股票代码”的API的“股票代码”参数,而这两者都依赖于操作系统级别的网络连接工具。又如,“餐厅预订”工具可能依赖于“获取当前位置”和“获取当前日期时间”工具来提供位置、日期或时间等功能参数。
所以,可以看最近的工作《Graph RAG-Tool Fusion》(https://arxiv.org/pdf/2502.07223),提出Graph RAG-Tool Fusion,一种结合向量检索和图遍历的方法,以捕获工具知识图中的所有相关工具及其嵌套依赖关系,并提出了一个新的工具选择基准数据集ToolLinkOS,这个数据包含573个虚构工具,涵盖了15个行业,每个工具平均有6.3个依赖关系,这些依赖关系可以是直接或间接的。
思路不错,我们可以看看具体实现,如下图所示,
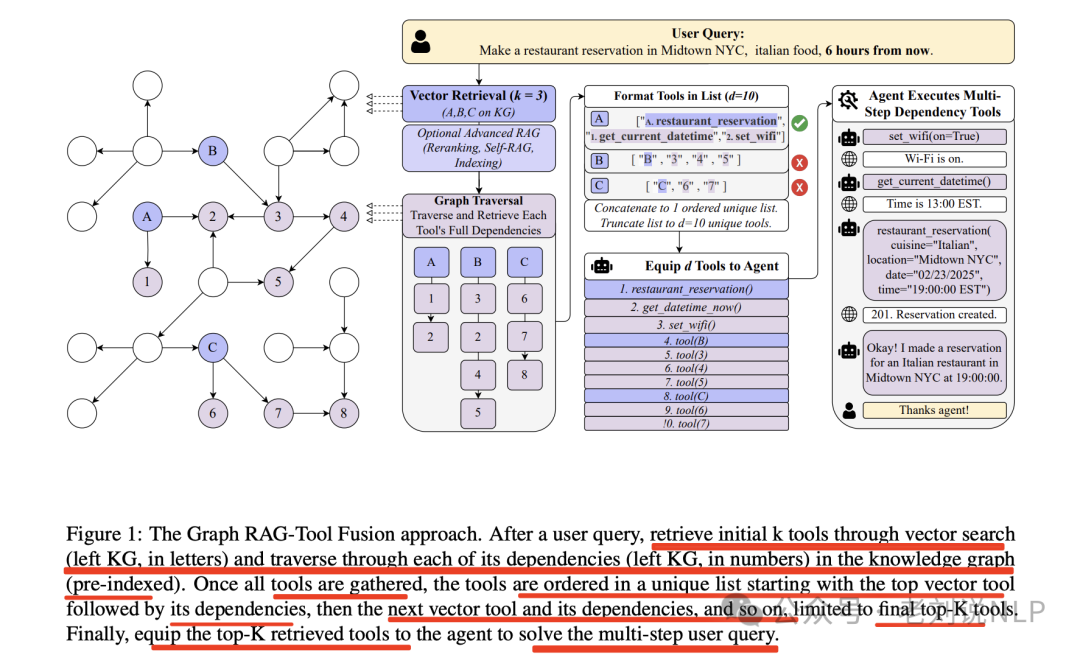
在用户查询后,通过向量搜索检索初始k个工具(左侧知识图谱,用字母表示)并遍历其在知识图谱中的每个依赖项(左侧知识图谱,用数字表示)(预索引)。一旦收集到所有工具,就将这些工具按唯一列表排序,从顶部向量工具开始,接着是其依赖项,然后是下一个向量工具及其依赖项,依此类推,最终限制为前K个顶级工具。最后,将前K个检索到的工具配备给代理,以解决多步骤用户查询。
那么具体如何来做呢?
1、工具知识图谱构建
这一步是进行工具依赖知识图谱构建。这个是检索的基础。将每个工具表示为一个节点,并将其依赖关系表示为边。
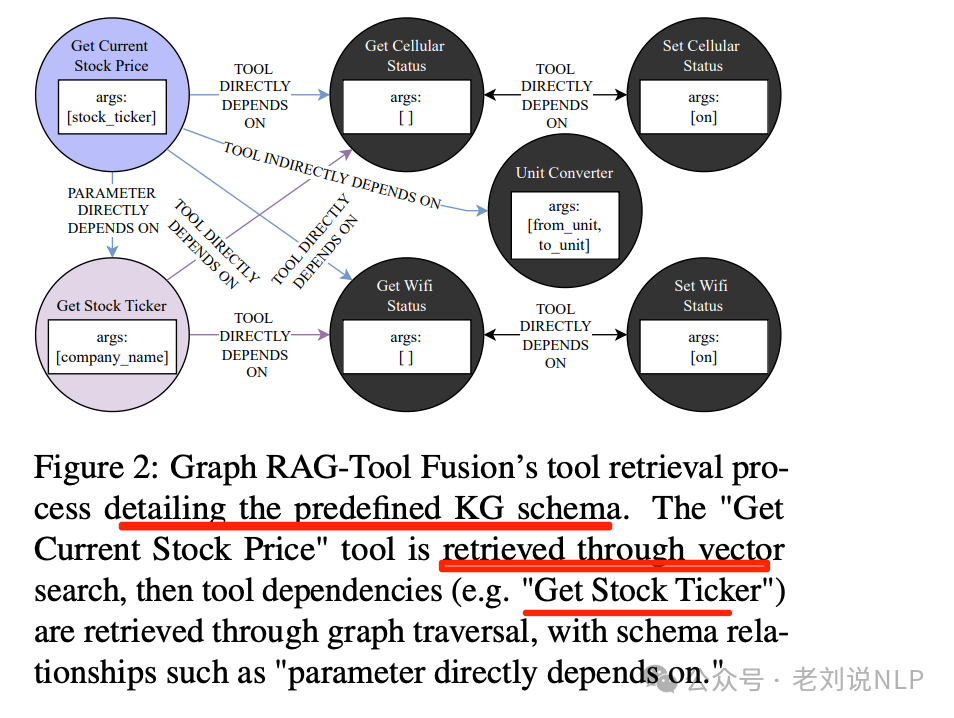
这里会涉及到知识图谱的schema,如上,RAG-Tool融合工具的检索过程详细说明了预定义的知识图谱模式。”获取当前股票价格”工具通过向量搜索被检索,然后通过图遍历检索工具依赖项(例如”获取股票代码”),并包含如”参数直接依赖于”的模式关系。
具体的,节点设计上,工具分为核心工具和常规工具。
核心工具代表一个可重用的函数,它是其他函数的典型依赖项,通常由代理在使用常规工具之前调用。例如下面这张ToolSandbox工具知识图谱。
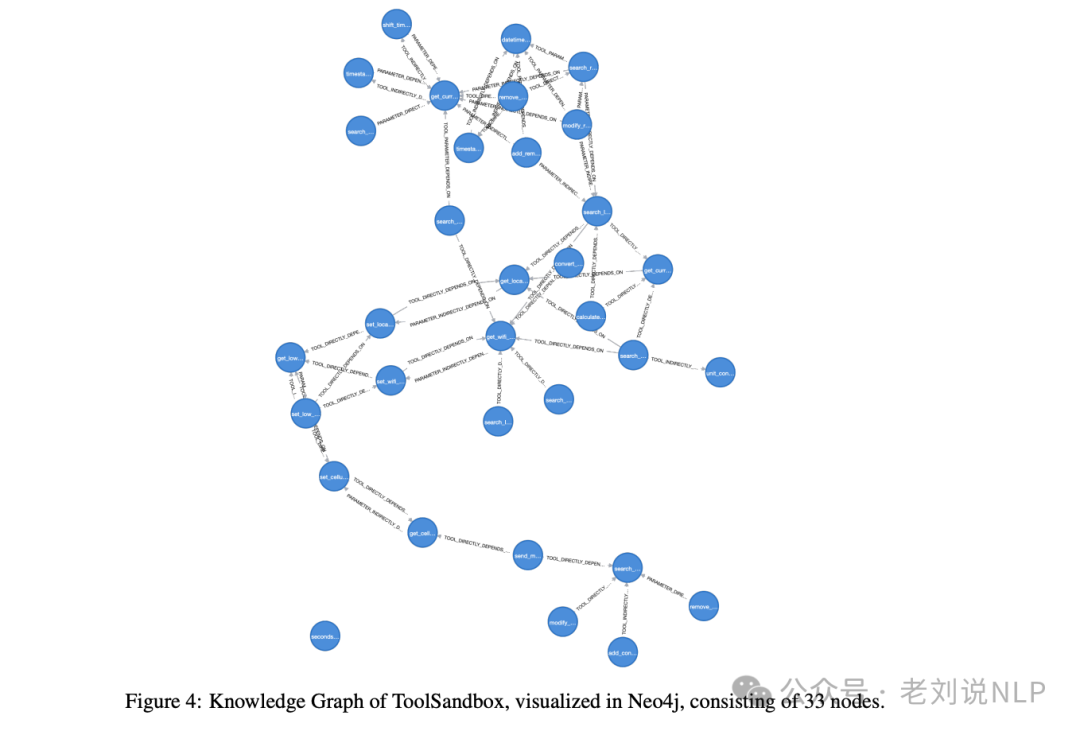
例如,返回当前日期的函数”get_current_date”可以被其他在其参数中包含日期的函数使用。核心工具也可以像常规工具一样,对核心工具或常规工具有依赖性。更多示例包括与操作系统相关的工具,如”设置WiFi状态”、”设置蜂窝数据状态”或”单位转换器”。
常规工具代表一个工具、API或作为工具的代理,它作为一个非实用工具供代理使用。这个工具通常对其他工具(核心或常规)有依赖性。例如,一个带有股票代码参数的”获取股票价格”工具依赖于知道股票代码,比如当用户询问”苹果”的当前股票价格时。
**关系上,工具节点之间的关系代表四种主要的依赖类型:工具直接依赖于、参数直接依赖于、工具间接依赖于以及参数间接依赖于。在模式格式中,关系的补充标签(reason和parameter_name)解释了两个工具之间存在依赖的原因,以及哪个参数(如果有的话)是依赖的。
工具直接依赖关系表示一个工具需要另一个工具才能运行。例如,“打开Wi-Fi”或“打开蜂窝数据”等工具对于某些工具接收有效响应是必不可少的。
工具间接依赖关系表示一个工具从另一个工具获益,但不严格需要它。例如,“餐厅预订”工具可能会从天气信息(“获取天气”)中受益,但即使没有它也能运作。
参数直接依赖关系表示一个参数必须在主要工具运行之前从另一个工具获得。例如,“产品信息”工具需要一个“产品ID”参数才能进行,而“获取产品ID”工具可以提供这个参数。
参数间接依赖关系表示一个参数可能依赖于额外的上下文,但这只有在用户输入明确要求时才会发生。例如,日期“明天”需要当前日期工具来计算相关日期,但指定2025年12月25日则不需要。
更直观的,可以看看ToolLinkOS的知识图谱展示。

二、基于工具知识图谱检索进行工具选择
在构建好知识图谱之后,就要开始用了,遵循如下的步骤,也很形象。
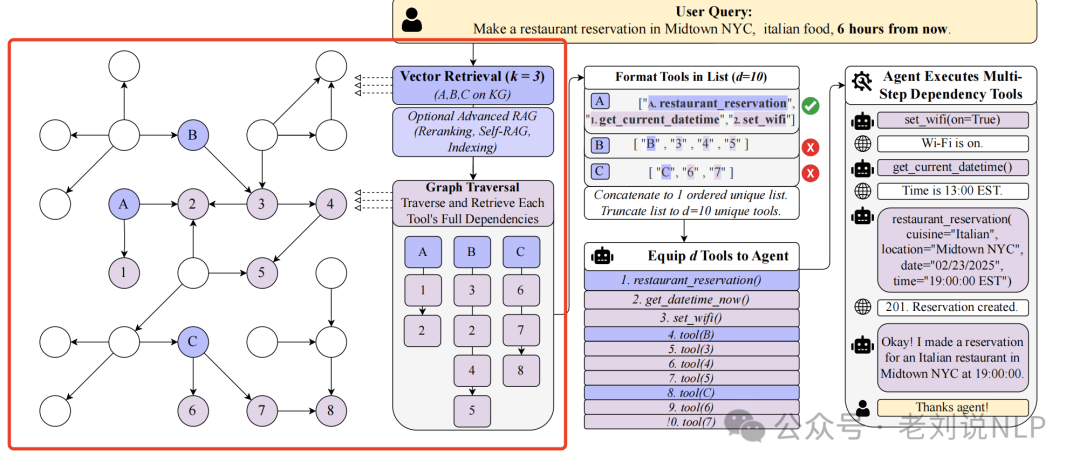
首先,通过向量搜索检索与用户查询相关的初始top-k个工具。这一步利用了向量数据库和相似度计算来快速找到最相关的工具。
然后,对初始检索到的每个工具,通过深度优先搜索(DFS)遍历其依赖关系。这些依赖关系可以是直接的(如一个工具直接依赖于另一个工具)或间接的(如一个工具通过一个中间工具依赖于另一个工具)。

最后,将所有检索到的工具按顺序排列,从向量检索工具开始,其次是其后继依赖关系,依此类推,限制为最终的top-K个工具。这样,代理就可以获得解决用户问题所需的所有工具。这块可以直接使用LLM进行rerank 重排,prompt如下:

但是,这种思路其实还很简单粗暴,这种方式能够显著提高朴素RAG的工具检索准确性,但它仍然存在一些限制。正如作者所说的,
首先,这种方式整合了向量搜索用于初步检索,因此向量搜索检索器的性能极大地影响了图RAG-工具融合的整体性能。
其次,应用的前提是为一组M个工具构建一个工具知识图谱(来自模式)。这个其实很费事,多数得人工构建,当然也可以使用大模型来辅助,例如最近的Deepseek R1。
最后,虽然工具关系模式被划分为4种类型,但是检索系统不会优先考虑某些关系。如果依赖计数和嵌套子图变得非常大,未来的工作可以优先考虑直接关系而非间接关系。并且,当关系很大的时候,其实工具的选择也是一个挑战。
总结
基于工具图谱来进行工具RAG选择确实是Graph 知识图谱的一条结合道路,但这个还是针对具体场景来说。大家可以多发散思路。
参考文献
1、https://arxiv.org/pdf/2502.07223
(文:老刘说NLP)