R1 火了之后,对国内AI开发者来说,就关心两件事。
哪里能用,这个现在基本解决了,硅基流动、阿里百炼、火山方舟等几乎所有的云平台都上线了 DeepSeek 的模型。但哪家好用,哪家能用,现在也是众说纷纭。今天这篇文章,就测一下国内云平台 DeepSeek 的服务质量。
第二个问题是,怎么用 R1。平民价格的推理模型,带来的是全新的与用户交互的范式,过往的很多提示工程可能都会直接被取代。怎么用 R1 等推理模型,开发 AI 应用,是一个当下待讨论的话题。
也因此,我们建了个R1 开发者交流群,切身聊一聊,今天创业,到底怎么用 R1。
-
高浓度的 DeepSeek 模型开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传。
01
判断哪些是凑热闹的供应商
先大家做几个祛魅。不要看到那么多厂商都提供了 R1/V3 ,实际有些可能根本没办法用的。
首先,R1/V3 都只有一个规格的版本,都是 6000+亿参数的,不存在所谓满血不满血。那所谓蒸馏版 R1 是指什么呢?实际上就是用 Qwen/Llama 这些开源模型,使用从 R1 蒸馏出来的思维链数据再做一次微调得到的模型。他们本质还是 Qwen/Llama,并且因为参数规模小,数据来源又是 R1。效果和原生的 R1 差距很大。所以,上蒸馏版,不提供原版的 R1 的,一般都是凑热闹的。
再次,如果是原版 R1/V3, 那么我们接着可以看供应商提供的 Context Window (窗口大小),简单来说,很多厂商,比如某软,他提供的免费 R1 实际窗口只有 4K, 这意味着你使用R1,输入和输出不能超过 4K, 基本也就几轮的聊天。而应用对接,一般都会提供大量的上下文,基本随随便便就超了,属于只能聊天打屁用的。
第三个是 TPM 限制,比如某厂 TPM 限制是 10000, 对于AI辅助编程基本一次请求都过不了,刚请求就触发 rate limit 了,也只能适合聊天打屁。
第四个,大家也能感受到,就算都是原版模型,可能聊天或者使用效果还是略有差别的。这个我们以后再讨论。
作为用户,你区分一个供应商是不是真的良心供应商,先看模型不是是原版的(6000亿参数规模),其次再看窗口大小(64k+ 是正常),最后看 TPM(一般要10w以上)。如果都符合要求,现在,才能进入我们今天的主题,谁的速度更快。
02
速度大比拼
一个供应商提供的 R1/V3 速度指标由下面两个指标来衡量:
啥意思呢?比如贴了一万个字符的问题,和输入“你好”,这两个指标肯定都会有区别的。其次,你在一个供应商非常繁忙的时间段去测试,肯定速度很慢。时间段我这里就随机了,好不好就看各个供应商的命了,而用户体量,这个对应的各家资源也不一样,这个是供应商要自己解决的问题。
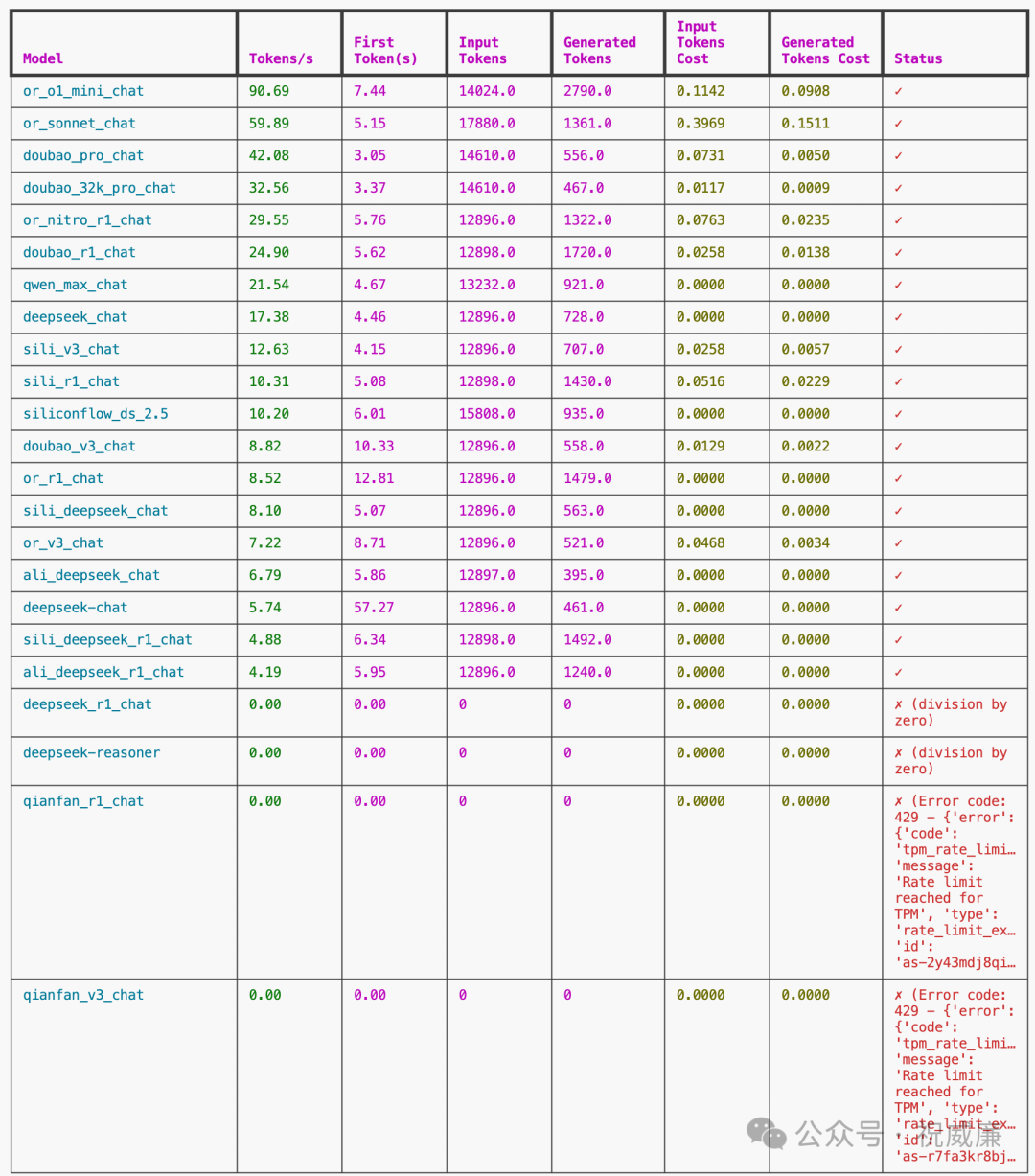
这次我们会同时对比国内外供应商,输入的问题长度,我们也会分成两个部分测试,一个输入100token以内,一个输入 14000 token左右。我们来分别看看TPS/TTFT。
与此同时,除了 R1/V3 我们也引入了一些其他模型的速度,大家可以权当参考。
1. or_o1_mini_chat 表示在openrouter 里的 o1 mini 模型。
2. doubao_pro_chat 表示在火山方舟的 doubao 1.5 pro 256k 模型
3. sili_r1_chat 表示硅基流动的 R1 模型(pro版)
4. doubao_32k_pro_chat 表示 doubao 1.5 pro 32k 模型
5. doubao_r1_chat 表示火山方舟的 R1 模型
6. QwenMax 表示阿里最新Qwen大模型
7. qianfan_r1_chat 百度千帆的 R1模型
8. qianfan_v3_chat 百度千帆的 V3模型
9. or_r1_chat openrouter 里免费 R1 模型
10 or_v3_chat openrouter 里 R1 模型
11 deepseek_chat 官方 V3 模型
12 ali_deepseek_r1_chat 阿里百炼上的 R1模型
13 doubao_v3_chat 火山方舟的 V3 模型
14 or_nitro_r1_chat openrouter 里的付费 R1 模型
15. ali_deepseek_chat 阿里百炼平台的 V3 模型
16. sili_deepseek_r1_chat 硅基流动的普通版 R1 模型
17. sili_deepseek_chat 硅基流动的普通版本 V3 模型
18. or_sonnet_chat openrouter 里的sonnet 3.5 模型
19. deepseek_r1_chat 官方 R1 模型
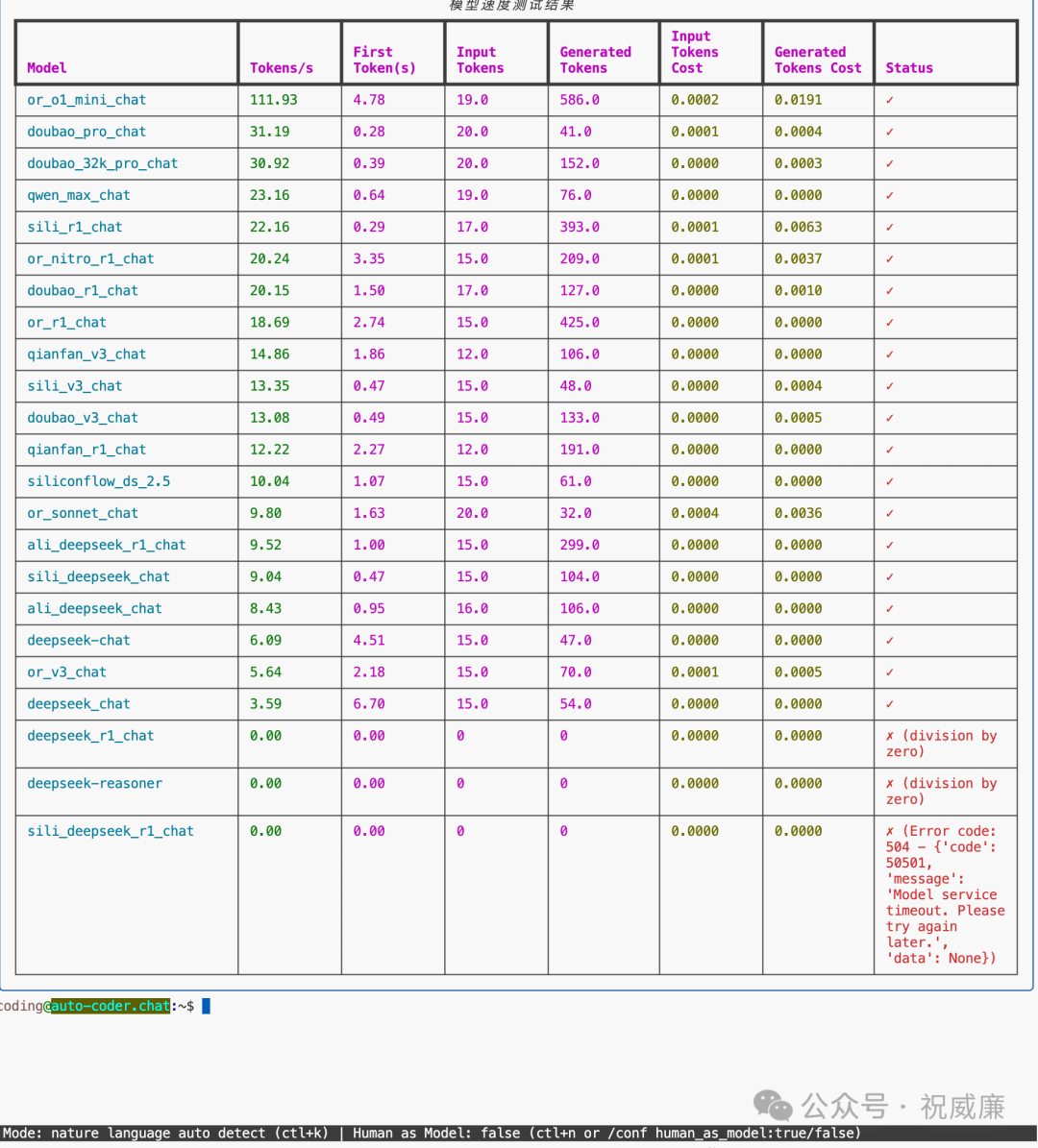
2. R1 的每秒输出速度,硅基流动以 22t/s 为冠军,openrouter, 火山方舟分别以 20.24t/s 以及 20.15t/s 居于亚军和季军。其他的基本都低于 20t/s。
3. V3 每秒输出速度,百度千帆以 14.86t/s 为冠军, 硅基流动和火山方舟分别以 13.35t/s 13.08t/s 分别居于亚军和季军。
4. R1 的首字母等待时间, 硅基流动以 0.2是为冠军,阿里百炼和火山方舟分别以 1.0 和 1.5s 为亚军和季军。
整体而言,类似你好,世界这样的场景里, 硅基流动,火山方舟两家稳居前三,openrouter和百度千帆和阿里百炼则偶有入局前三。
接下来,重磅来了![]() ,我们看看大输入下各家的表现。
1. R1 模型, openrouter TPS 以 29.55 为冠军,火山方舟和硅基流动分别以 24.90t/s, 10.31t/s 分别居于亚军和季军。
2. V3 模型, 硅基流动TPS 以 12.63t/s 为冠军, 火山方舟和openrouter 分别以 8.82t/s, 7.22t/s 居于亚军和季军。
3. 在R1模型的TTFT上,硅基流动以 5.08 的延时获得冠军, 火山方舟则以 5.62 居于亚军。两者差距不大。
最后做个总结:在大输入下(14000tokens),火山方舟,硅基流动,openrouter稳居前三, 各有优劣。其他的诸如百度千帆因为 TPM 限制,直接报错。
国内R1/V3 提供上,表现最好的是就是火山方舟和硅基流动,基本也和我之前的认知相同,他们两家技术实力强悍,行动也都很早,而且效果上也和官方有在对齐,基本值得信赖。
,我们看看大输入下各家的表现。
1. R1 模型, openrouter TPS 以 29.55 为冠军,火山方舟和硅基流动分别以 24.90t/s, 10.31t/s 分别居于亚军和季军。
2. V3 模型, 硅基流动TPS 以 12.63t/s 为冠军, 火山方舟和openrouter 分别以 8.82t/s, 7.22t/s 居于亚军和季军。
3. 在R1模型的TTFT上,硅基流动以 5.08 的延时获得冠军, 火山方舟则以 5.62 居于亚军。两者差距不大。
最后做个总结:在大输入下(14000tokens),火山方舟,硅基流动,openrouter稳居前三, 各有优劣。其他的诸如百度千帆因为 TPM 限制,直接报错。
国内R1/V3 提供上,表现最好的是就是火山方舟和硅基流动,基本也和我之前的认知相同,他们两家技术实力强悍,行动也都很早,而且效果上也和官方有在对齐,基本值得信赖。
03
如何自己测试
pip install -U auto-coder
然后按文档配置模型:https://uelng8wukz.feishu.cn/wiki/K3EmwuNrbiAN0CkHMGyc315Wn7f?fromScene=spaceOverview
/models /speed-test /long-context
/models /speed-test /long-context 3
(文:Founder Park)

 ,我们看看大输入下各家的表现。
,我们看看大输入下各家的表现。