

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
在嘈杂的环境中,人类能够专注于特定的语音信号,这种现象被称为「鸡尾酒会效应」。对于机器来说,如何从混合的音频信号中准确分离出不同的声源是一个重要的挑战。
语音分离(Speech Separation)能够有效提高语音识别的准确性,通常作为识别的前置步骤。因此,语音分离模型不仅需要在真实音频上输出分离良好的结果,同时还要满足低延迟的需求。
近年来,深度学习在语音分离任务中的应用受到了广泛关注。尽管许多高性能的语音分离方法被提出,但仍有两个关键问题未能得到充分解决:一是许多模型计算复杂度太高,未充分考虑实际应用场景的需求;二是常用的语音分离数据集与真实场景存在较大差距,导致模型在真实数据上的泛化能力不足。
为了解决这些问题,清华大学的研究团队设计了一种名为 TIGER(Time-frequency Interleaved Gain Extraction and Reconstruction network)的轻量级语音分离模型,并提出了一个新的数据集 EchoSet,旨在更真实地模拟复杂声学环境中的语音分离任务。
实验结果表明,TIGER 在压缩 94.3% 参数量和 95.3% 计算量的同时,性能与当前最先进的模型 TF-GridNet [1] 相当。

-
论文标题:TIGER: Time-frequency Interleaved Gain Extraction and Reconstruction for Efficient Speech Separation -
论文链接:https://arxiv.org/pdf/2410.01469 -
项目主页:https://cslikai.cn/TIGER -
GitHub 链接:https://github.com/JusperLee/TIGER -
数据链接:https://huggingface.co/datasets/JusperLee/EchoSet
方法
语音分离任务的核心是从混合的音频信号中恢复出每个说话者的清晰语音。传统的语音分离模型通常直接在时域或频域进行处理,但往往忽略了时间和频率维度之间的交互信息。为了更高效地提取语音特征,TIGER 模型采用了时频交叉建模的策略,结合频带切分和多尺度注意力机制,显著提升了分离效果。
TIGER 模型的整体流程可以分为五个主要部分:编码器、频带切分模块、分离器、频带恢复模块和解码器。首先,通过短时傅里叶变换(STFT)将混合音频信号转换为时频表示。接着,将整个频带划分为多个子带,每个子带通过一维卷积转换为统一的特征维度。分离器由多个时频交叉建模模块(FFI)组成,用于提取每个说话者的声学特征。最后,频带恢复模块将子带恢复到全频带范围,并通过逆短时傅里叶变换(iSTFT)生成每个说话者的清晰语音信号。

TIGER 整体流程
频带切分
语音信号的能量分布在不同频带上并不均匀,中低频带通常包含更多的语音信息,而高频带则包含更多的噪声和细节信息。为了减少计算量并提升模型对关键频带的关注,TIGER 采用了频带切分策略,根据重要性将频带划分为不同宽度的子带。这种策略不仅减少了计算量,还能让模型更专注于重要的频带,从而提升分离效果。
分离器
语音信号的时间和频率维度之间存在复杂的交互关系。为了更高效地建模这种交互关系,TIGER 引入了时频交叉建模模块(FFI)。为了减少参数,分离器由多个共享参数的 FFI 模块构成。每个 FFI 模块包含两个路径:频率路径和帧路径。
每个路径都包含两个关键子模块:多尺度选择性注意力模块(MSA)和全频 / 帧注意力模块(F³A)。通过交替处理时间和频率信息,FFI 模块能够有效地整合时频特征,提升语音分离的效果。
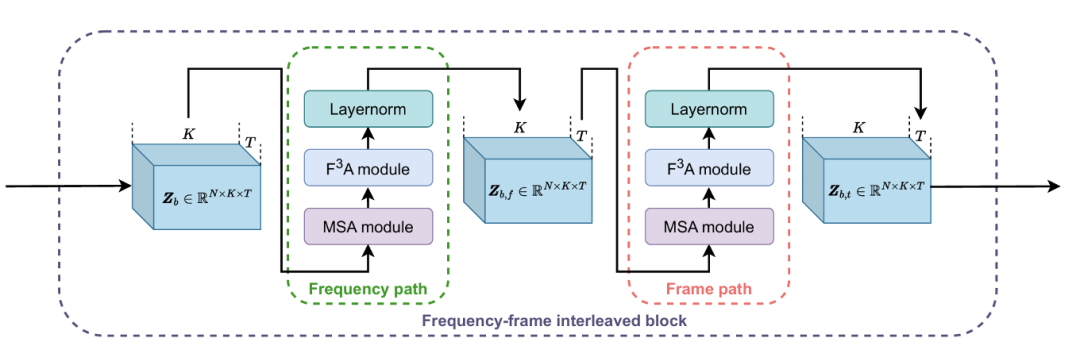
FFI 模块内部细节
多尺度选择性注意力模块(MSA)
为了增强模型对多尺度特征的提取能力,TIGER 引入了 MSA,通过多尺度卷积层和选择性注意力机制,融合局部和全局信息。MSA 模块分为三个阶段:编码、融合和解码。
以频率路径为例,在编码阶段,通过多个一维卷积层逐步下采样频率维度,提取多尺度的声学特征。在融合阶段,使用选择性注意力机制将局部特征和全局特征进行融合,生成包含多尺度信息的特征。在解码阶段,通过上采样和卷积操作逐步恢复频率维度,最终输出增强后的频率特征。

MSA 模块内部细节(以频率路径为例)
全频 / 帧注意力模块(F³A)
为了捕捉长距离依赖关系,TIGER 采用了全 / 频帧注意力模块(F³A)。同样以频率路径为例,首先采用二维卷积将输入特征转换为查询(Query)、键(Key)和值(Value),然后将特征维度和时间维度合并,得到每个频带对应的全帧信息。
通过自注意机制计算频率维度上的注意力权重,用于加强频带间关系的捕捉,提升语音分离的效果。

F³A 模块内部细节(以频率路径为例)
EchoSet:更接近真实声学场景
的语音分离数据集
现有的语音分离数据集往往与真实世界的声学环境存在较大差距,导致模型在实际应用中的泛化能力不足。为了更真实地模拟复杂声学环境中的语音分离任务,研究团队提出了 EchoSet 数据集,该数据集不仅包含噪声,还模拟了真实的混响效果(如考虑物体遮挡和材料特性),并且说话人之间语音重叠比例是随机的。

不同数据集特性对比
EchoSet 数据集的构建基于 SoundSpaces 2.0 平台 [2] 和 Matterport3D 场景数据集 [3],能够模拟不同声学环境中的语音混响效果。通过随机采样语音和噪声,并考虑房间的几何形状和材料特性,EchoSet 数据集生成了包含 20,268 条训练语音、4,604 条验证语音和 2,650 条测试语音的高保真数据集。
实验表明,使用 EchoSet 训练的模型在真实世界数据上的泛化能力显著优于其他数据集训练的模型,验证了 EchoSet 的实用价值。
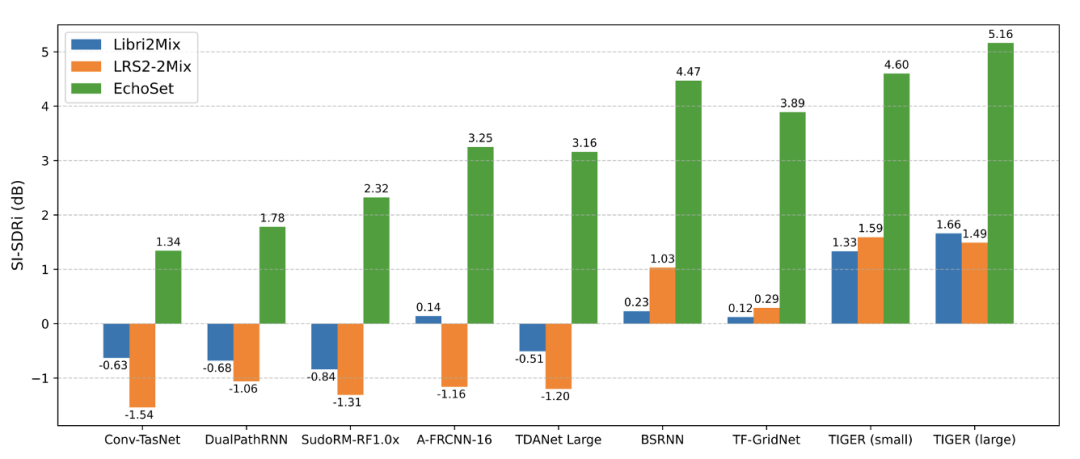
常见语音分离模型在不同数据集上训练后,在真实世界采集数据上的泛化性能比较
实验
研究团队在多个数据集上对 TIGER 进行了全面评估,包括 Libri2Mix、LRS2-2Mix 和 EchoSet。实验结果显示,随着数据集的复杂性增加,TIGER 的性能优势越加显著。在 EchoSet 数据集上,TIGER 的性能比 TF-GridNet 提升了约 5%,同时参数量和计算量分别减少了 94.3% 和 95.3%。在真实世界采集的数据上(见上图),TIGER 同样表现出了最佳的分离性能。
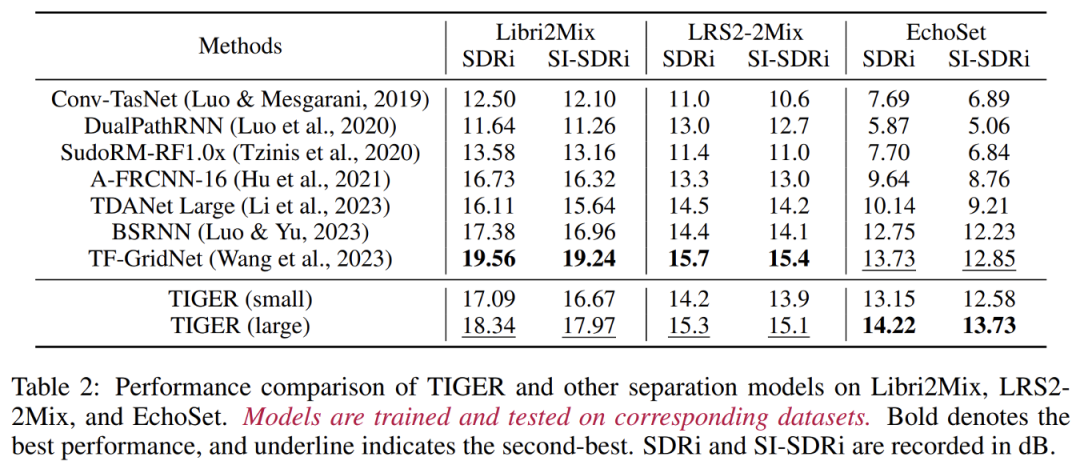
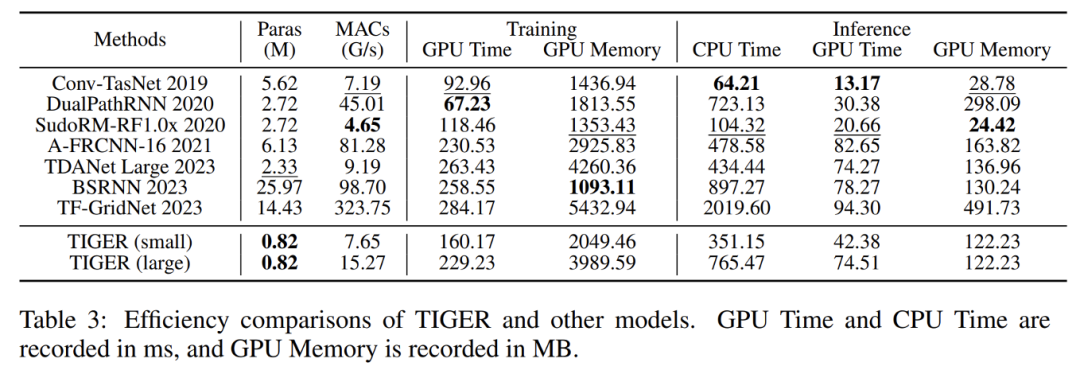
常见语音分离模型性能和效率比较
研究团队通过进一步压缩参数,探索了 TIGER 的轻量化潜力。在 100K 的参数规模下,TIGER(tiny)在 Echoset 上的性能显著优于基 GC3 方法 [4] 压缩的 SudoRM-RF 模型 [5],表明 TIGER 在参数量和计算成本较低的情况下,仍能提供卓越的语音分离性能。

SudoRM-RF + GC3 与 TIGER (tiny) 的性能和效率比较
此外,TIGER 在电影音频分离任务中也表现出了强大的泛化能力。实验结果显示,TIGER 在分离电影音频中的语音、音乐和音效时,在保持轻量的情况下,性能显著优于其他模型,进一步验证了其在复杂声学环境中的适用性。

TIGER 在电影音频分离任务上的性能和效率
《流浪地球 2》宣传片原片
用 TIGER 分离出《流浪地球 2》宣传片中人声的效果
用 TIGER 分离《流浪地球 2》宣传片中音效的效果
用 TIGER 分离《流浪地球 2》宣传片中背景音乐的效果
结论
TIGER 模型的提出为语音分离任务提供了一种新的解决方案,通过频带切分和基于多尺度注意力机制的时频交替建模模块,在保持高性能的同时,显著降低了参数量和计算成本。EchoSet 数据集的引入也为语音分离模型的训练和评估提供了更接近真实世界的数据支持。实验结果表明,TIGER 在复杂声学环境中的表现优于现有模型,并且在计算资源受限的场景下具有广泛的应用前景。
参考文献
[1] Zhong-Qiu Wang, Samuele Cornell, Shukjae Choi, Younglo Lee, Byeong-Yeol Kim, and Shinji Watanabe. Tf-gridnet: Making time-frequency domain models great again for monaural speaker separation. In International Conference on Acoustics, Speech and Signal Processing, pp. 1–5. IEEE, 2023.
[2] Changan Chen, Carl Schissler, Sanchit Garg, Philip Kobernik, Alexander Clegg, Paul Calamia, Dhruv Batra, Philip Robinson, and Kristen Grauman. Soundspaces 2.0: A simulation platform for visual-acoustic learning. In Advances in Neural Information Processing Systems, volume 35, pp. 8896–8911, 2022.
[3] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niebner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. In International Conference on 3D Vision, pp. 667–676. IEEE, 2017.
[4] Yi Luo, Cong Han, and Nima Mesgarani. Group communication with context codec for lightweight source separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29: 1752–1761, 2021.
[5] Efthymios Tzinis, Zhepei Wang, and Paris Smaragdis. Sudo rm-rf: Efficient networks for universal audio source separation. In IEEE 30th International Workshop on Machine Learning for Signal Processing, pp. 1–6. IEEE, 2020.
©
(文:机器之心)