
白交 发自 凹非寺
量子位 | 公众号 QbitAI
与OpenAI断交之后,Figure首个成果出炉:
Helix,一个端到端通用控制模型,它能让机器人像人一样感知、理解和行动。
只需自然语言提示,机器人就能拿起任何东西,哪怕是从没见过的东西,比如这个活泼的小仙人掌。

从官方放出的演示中可以看到,它在接收到人类的提示后,就会按照指令逐一拿起桌上的物品放进冰箱。

嗯,是有种“机器人站着不语,只是一味地执行指令”的感觉了 。
。

两个机器人也可以共同协作,但有意思的一点是,他们竟然共用同一组神经网络。

△加速2倍
来看看具体是怎么一回事。
像人类一样思考的AI
从技术报告上看,这个通用“视觉-语言-动作” (VLA) 模型完成了一系列的首创:
整个上身控制,Helix是首个能对整个上身(包括手腕、躯干、头部和各个手指)进行高速率(200Hz)连续控制的VLA。
多机器人协作,第一个同时在两个机器人上运行的 VLA,使它们能够使用从未见过的物品解决共享的、远程操作任务。
拿起任何东西,只需按照自然语言提示,就能拿起几乎任何小型家居物品,包括数千种它们从未遇到过的物品。
一个神经网络,与之前的方法不同,Helix 使用一组神经网络权重来学习所有行为(挑选和放置物品、使用抽屉和冰箱以及跨机器人交互),而无需任何针对特定任务的微调。
可立即商业化部署,第一款完全在嵌入式低功耗 GPU 上运行的 VLA,可立即进行商业部署。
Helix由两个系统组成,两个系统经过端到端训练,并且可以进行通信。
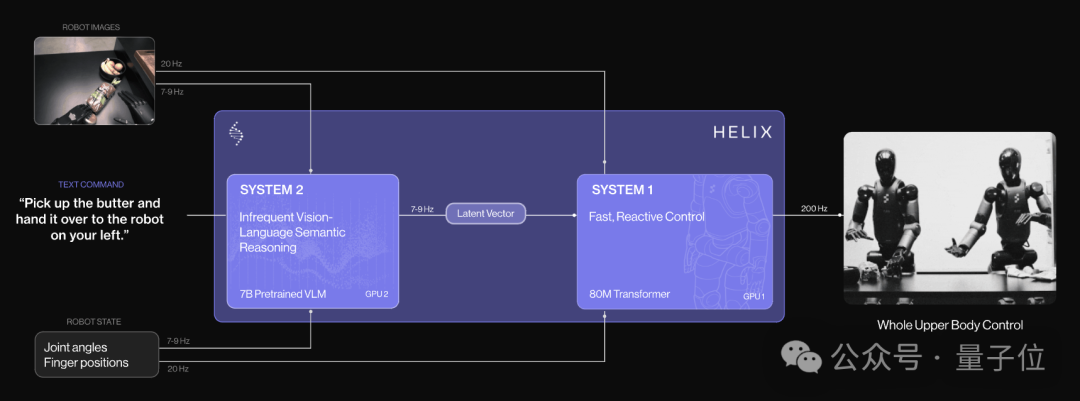
系统2:VLM主干,基于在互联网规模数据上预训练的7B开源VLM,它将单目机器人图像和机器人状态信息(包括手腕姿势和手指位置)投射到视觉语言嵌入空间后进行处理。
工作频率为 7-9 Hz,用于场景理解和语言理解,可对不同对象和语境进行广泛的泛化。
系统1:80M参数的交叉注意力Transformer,用于处理底层控制。它依靠一个完全卷积、多尺度的视觉骨干网进行视觉处理,该骨干网由完全在模拟中完成的预训练初始化而成。
将 S2 生成的潜在语义表征转化为精确的连续机器人动作,包括所需的手腕姿势、手指弯曲和外展控制,以及躯干和头部方向目标。速度为200Hz。
他们在动作空间中附加了一个合成的 “任务完成百分比 ”动作,使 Helix 能够预测自己的终止条件,从而更容易对多个任务进行排序。
这种解耦架构允许每个系统在其最佳时间尺度上运行。S2可以“慢慢思考”高级目标,而 S1 可以“快速思考”以实时执行和调整动作。
训练过程是完全端到端,从原始像素和文本命令映射到具有标准回归损失的连续动作。
并且Helix 不需要针对特定任务进行调整;它保持单个训练阶段和单个神经网络权重集,无需单独的动作头或每个任务的微调阶段。
人形机器人的Scaling Law
CEO透露,这项工作他们花费了一年多的时间,旨在解决通用机器人问题——
像人类一样,Helix可以理解语音、推理问题并能抓住任何物体。
而就在两周前,他们宣布取消与OpenAI之间的合作关系,当时就透露会在接下来的30天展示“没人在人形机器人上见过的东西”。
如今已经揭晓,就是Helix。
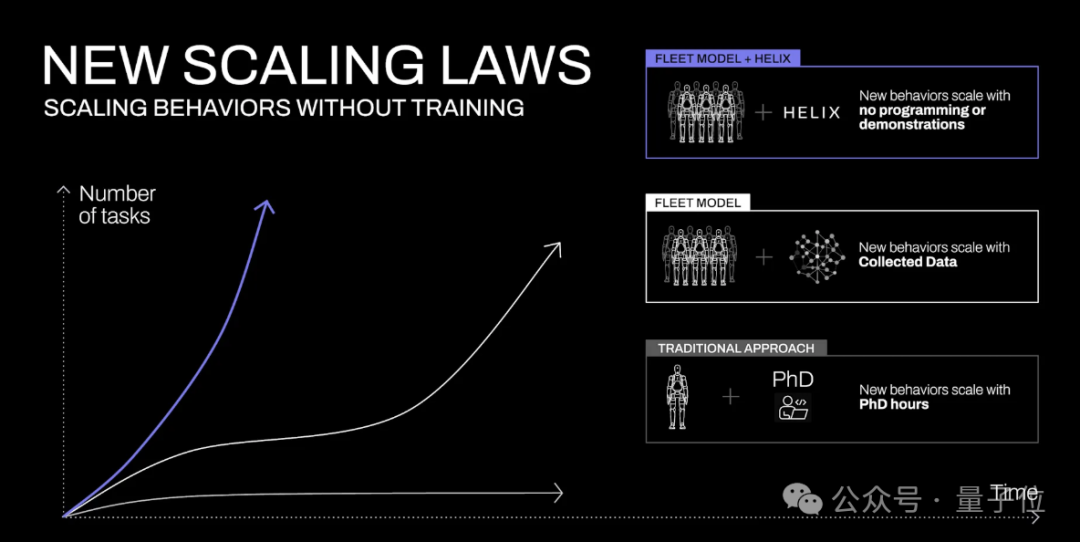
值得一提的是,Helix还代表着一种新型的Scaling Law。
他们认为,家庭是机器人面临的最大挑战。与受控的工业环境不同,家里堆满了无数的物品。为了让机器人在家庭中发挥作用,它们需要能够按需产生智能的新行为,尤其是对它们从未见过的物体。
当前,教机器人一种新行为需要大量的人力。要么是数小时的博士级专家手动编程,要么是数千次演示。
这两种方式成本都很高,所以都是行不通的(dont work)。
与早期的机器人系统不同,Helix能够即时生成长视界、协作、灵巧的操作,而无需任何特定任务的演示或大量的手动编程。
Helix 表现出强大的对象泛化能力,能够拾取数千种形状、大小、颜色和材料特性各异的新奇家居用品,而这些物品在训练中从未见过,只需用自然语言询问即可。
这意味着,这代表 Figure 在扩展人形机器人行为方面迈出了变革性的一步。
到时候,当Helix 扩大1000倍、机器人扩展到十亿级别,会是什么样子?有点子期待。
(文:量子位)