
“AI音频时代”研究小组独家专稿,转载请务必先联系

从2024年春节伊始,Sora的横空出世为内容创作新AI时代拉开了序幕,这一年来,AIGC(人工智能内容生成)取得了从开天辟地到就要翻天覆地的变化。AIGC同样包含文字、图片、视频、音频等领域,作为音频领域最重要分支之一-TTS(Text to Sound)文本生成音频,也有了火山大爆炸似的发展,已经从一开始的巨头引领到了百花齐放,特别是2024下半年,从基础发展到直接应用都有了巨大的突破,当然这样的发展离不开各大模型的进步和开放,我们从今天开始进行系列独家连载,为当下的zhongTTS发展做一个小小总结(本文部分内容来自于ChatGTP、豆包、DeepSeek等):
GPT-SoVITS
基于 SoVITS(Singing Voice Conversion)技术与 GPT 相关能力结合的语音合成项目,在 AI 音频领域展现出独特优势,同时也面临一些挑战:
优势:
GPT-SoVITS可以说是当下开源中文克隆语音的新天花,具有零样本语音转换能力出色:其显著特点是在零样本的文本转语音转换方面表现卓越。这意味着无需大量特定说话人的语音数据进行训练,就能实现高质量的语音克隆。例如,用户只需提供少量文本,它就能生成与目标说话人极为相似的语音,极大地降低了语音合成对数据量的依赖,提高了语音克隆的效率和便捷性。
支持多语言:可以支持包括中文在内的多种语言,满足了不同语言背景用户的需求。无论是在亚洲、欧洲还是其他地区,不同语言的使用者都能利用该技术进行语音合成,扩大了技术的应用范围,使其在全球市场具有更高的实用性。
集成工具包方便易用:提供了集成工具包,方便开发者将其无缝集成到各种应用程序中。这对于希望在自己的产品,如语音助手、有声读物应用等中添加语音合成功能的开发者来说,大大降低了开发成本和技术门槛,加速了相关产品的开发进程。
局限:
语音自然度仍有待提升:尽管能够克隆出与目标说话人相似的声音,但在语音的自然度和流畅度方面,与人类自然语音相比仍有差距。在语调、韵律、停顿等细节处理上,有时会显得生硬和机械,影响听众的听觉体验,特别是在长文本的语音合成中,这种不自然感可能会更加明显。
情感表达不够精准:对于语音中情感的细腻表达能力有限。在需要传达复杂情感,如微妙的悲伤、喜悦或愤怒等情绪时,生成的语音可能无法准确捕捉和呈现这些情感的细微差别,导致语音缺乏情感共鸣,难以让听众产生强烈的情感连接。
版权与伦理问题:作为语音克隆技术,GPT-SoVITS 面临着严重的版权和伦理挑战。未经授权克隆他人声音,可能侵犯个人的声音版权和隐私权。同时,恶意使用该技术,如伪造名人声音进行诈骗、传播虚假信息等,会对社会秩序和个人权益造成极大危害,引发一系列法律和道德争议。
Fish Speech
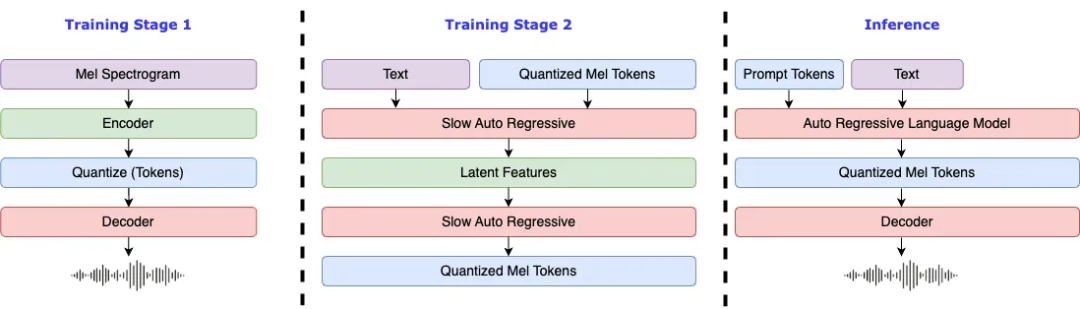
Fish Speech 以稳定性和卓越的语音克隆能力闻名,经过 300,000 小时的中文等多语言音频数据训练,适用于需要高稳定性语音合成的场景。
优势:
-
采用高效算法:运用 Flash-Attn 算法,在处理大规模数据时效率高、准确性和稳定性强,极大提升了 TTS 性能。
-
集成多种技术:集成 VQGAN、Llama 和 VITS 等先进技术,实现了文本到语音的高级别转换质量,增强了语音的自然度和真实感。
-
整合 Text2Semantic 模型:能够深入挖掘文本语义和情感色彩,使合成语音更具情感表达力,更贴近人类真实对话。
-
多语言支持:涵盖中文、英语和日语等多种语言,满足了不同语言用户的需求,方便在全球范围内应用。
-
语音克隆出色:用户只需提供一段参考语音,就能快速进行语音克隆,无需复杂训练过程,为内容创作者等提供了便利。
-
低显存需求:仅需 4GB 显存即可推理,8GB 用于微调,对硬件要求低,降低了使用门槛,普通个人设备也能轻松运行。
-
推理速度快:优化了推理过程,能实现快速的文本到语音转换,减少用户等待时间,可满足直播、在线教育等实时性要求高的场景。
-
个性化定制:提供丰富的音色库,有明星、游戏角色、动漫人物等多种音色可供选择,还支持用户根据喜好调整语速、音调、音色等,创建专属虚拟声音角色。
-
开源共享:代码和模型开源,全球开发者可共同参与和贡献,推动技术发展,也方便用户根据自身需求进行定制和改进。
-
平台友好:提供在线平台,无需技术基础也能轻松体验 AI 语音合成。有 “发现”“语音合成”“构建声音”“我的声音” 等模块,操作简单。
-
可集成性强:提供 API 接口和 SDK,便于集成到各种应用程序、网站、游戏或智能设备中,拓展了应用场景。
技术先进
功能强大
使用便捷
局限:
-
情感精准度不足:尽管整合了 Text2Semantic 模型,但在一些复杂情感的精准表达上可能仍有欠缺,与人类自然语音在情感细腻度上存在一定差距。
-
语音自然度瑕疵:在某些特殊语境或特定发音上,生成的语音可能还存在一些不自然的地方,如一些连读、变调等细节处理可能不够完美。
-
适用场景有限:主要集中在文本转语音和语音克隆领域,对于一些更复杂的语音交互任务,如实时语音对话中的多轮交互、语音理解后的深度语义分析等,功能相对较弱。
Seed-TTS
Seed-TTS:由字节跳动开发的的语音合成系统,支持多种语言,能处理各种文本类型,可生成带有不同情感和语境细微差别的同语言或跨语言语音。
优势:
多语言与跨语言能力:支持多种语言的语音合成,并且能够处理同语言或跨语言的语音转换任务。这使得它在全球范围内具有广泛的适用性,无论是跨国公司用于多语言客服语音,还是语言学习类应用中不同语言的发音示范,Seed-TTS 都能满足多样化的需求。例如,在国际商务场景下,企业可以利用它快速生成多种语言的产品介绍语音。
情感与语境感知:能够生成带有不同情感和语境细微差别的语音。通过对文本内容的理解,它可以为语音赋予喜怒哀乐等不同情绪,使合成语音更加生动、贴合实际场景。在有声读物制作中,Seed-TTS 能够根据故事情节的起伏,精准地调整语音情感,让听众更沉浸于故事之中。
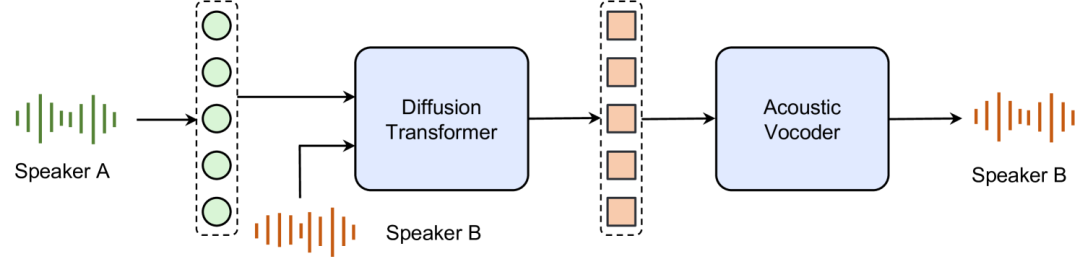
文本类型适应性强:对各种文本类型都有出色的处理能力,无论是正式的新闻稿件、日常的对话,还是诗歌、歌词等富有韵律和创意的文本,都能生成自然流畅的语音。这体现了其强大的文本解析和语音生成的适配性,拓宽了在内容创作领域的应用边界。
技术实力支撑:依托字节跳动的强大技术团队,在语音合成技术的研发上不断投入。采用先进的深度学习模型和算法,确保了语音合成的高质量和稳定性,在行业内处于技术领先地位。
局限:
特定领域优化不足:尽管对多种文本类型都能处理,但在一些高度专业化的领域,如医学、法律等,合成语音可能无法完全体现专业术语的独特发音和语感。对于专业领域的内容创作者或使用者来说,可能需要进一步优化才能满足专业场景的需求。
极端场景表现受限:在一些极端或特殊的场景需求下,如模拟极端恶劣环境下的语音失真效果,或者特定方言土语中非常生僻的发音,Seed-TTS 可能无法精准地实现,其语音生成的灵活性和对极端情况的适应性有待提升。
训练数据依赖:虽然技术先进,但语音合成的效果仍在一定程度上依赖于训练数据的规模和多样性。如果遇到非常小众或新兴的语言变体、口音,可能由于训练数据覆盖不足,导致合成语音的质量受到影响。
ChatTTS
ChatTTS:专注于具有详细韵律的对话式 TTS,支持中文和英文,在生成逼真且细致入微的多说话人对话方面表现出色。
优势:
技术创新
-
对话场景优化:专门为对话场景设计,能根据上下文调整语气和情感,使生成的语音在对话中更加连贯、自然,富有表现力,为用户带来沉浸式的对话体验,更贴近真实的人际交流。
-
韵律调控精准:可以精准预测并细致调控语音中的韵律特征,如笑声、停顿和插入语等,在韵律表达上超越了许多现有的开源 TTS 模型,让语音更生动。
-
模型先进:采用先进的自回归模型和细粒度声学特征预测技术,实现了高质量和自然度的语音合成。
-
多语言支持:全面支持中文和英文两种主流语言,为全球各地的用户搭建了无障碍沟通的桥梁,拓宽了应用场景和用户群体。
-
多说话人模拟:能够呈现不同性别和风格的语音,满足各种场景下对不同说话人声音的需求,为合成效果增添了更多趣味和多样性。
-
实时合成:具有强大的实时语音合成功能,能在用户输入文本后迅速生成对应的语音,适用于智能客服、在线教育和虚拟助手等需要即时反馈的场景。
-
开源共享:项目开源,代码和预训练模型资源可获取,开发者能在其基础上进行深入开发和创新应用,推动语音合成技术发展。
-
体验方式多样:提供在线体验功能,用户可在网页上输入文本生成语音文件;也支持本地安装,方便有高级定制需求的用户;还有 Windows 环境下的一键启动包,降低了使用门槛。
-
社区活跃:在 GitHub 等平台上拥有活跃的社区,用户可以方便地获取技术支持、分享经验,共同推动模型的发展,也会有持续的更新和优化。
功能实用
使用便捷
局限:
-
长文本处理短板1:目前版本存在生成音频时长限制,处理较长文本时可能出现分词问题,合成质量也可能会受影响,计算资源需求高,算法优化有待提升。
-
训练数据局限1:开源版本使用了 4 万小时的数据,相比一些大规模的 TTS 模型,训练数据量相对较少,可能会影响模型的泛化能力和对一些复杂语言现象的处理。
-
伦理潜在风险1:为防止滥用,开发者在训练过程中添加了少量额外的高频噪音并压低了音质,一定程度上可能会影响语音质量和用户体验,且仍可能存在被恶意利用的风险。
MARS5-TTS

MARS5-TTS:由 CAMB.AI 团队开发的一款先进的语音合成模型,擅长为体育评论和动漫等韵律复杂多样的场景生成语音,可应用于多种动态场景,满足不同场景下的语音合成需求。
优势:
技术架构先进
-
独特的两阶段 AR – NAR 管道:采用自回归(AR)和非自回归(NAR)的两阶段处理流程,AR 阶段生成粗略语音特征,NAR 阶段利用多变量 DDPM 模型细化,使模型在处理复杂韵律场景如体育解说、动漫配音等方面表现出色。
-
自动编码器与字节对编码:利用自动编码器学习和重建语音信号编码表示,采用字节对编码技术处理文本数据,提高了对文本的处理效率。
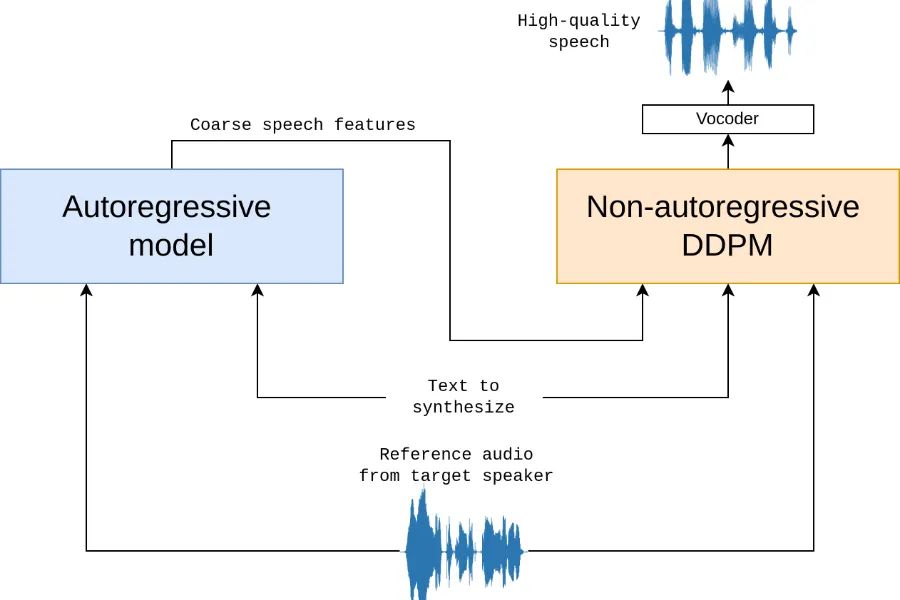
-
语音克隆出色:支持浅层推理和深层推理两种方式,深层推理可提供更高输出质量。通过提供 5 秒的音频样本和文本输入,能模仿参考音频的语音特征,实现高质量的语音克隆。
-
韵律与情感控制佳:能够根据文本中的标点和大写来控制语音的停顿、强调等,还可模拟不同的情感表达,使生成的语音更自然、富有表现力。
-
多语言支持:虽然专注于英语,但所属团队提供多语言的 TTS 解决方案,且模型本身也支持 140 多种语言,适用范围广泛。
-
简单的加载与调用:通过 <代码开始> torch.hub < 代码结束 > 提供方便的模型加载方式,无需克隆仓库。提供简单的 API 调用方式,开发者可轻松集成到自己的应用中。
-
开源协作:项目开源,鼓励社区成员参与改进和优化,有活跃的社区,文档齐全,用户可获取技术支持、分享经验。
功能特性强大
使用便捷性高
局限:
-
硬件要求高:需要至少 20GB 的 GPU VRAM 来运行,对硬件配置要求较高,可能限制了一些用户的使用,增加了使用成本。
-
输入条件限制:语音合成的质量依赖于参考音频质量和转录文本的准确性,若参考音频质量不佳或文本不准确,会影响最终的语音输出质量。
-
功能有待完善:目前只能识别并生成单人的语音片段,无法生成对话音频,在一些需要多人对话的应用场景中存在局限性。
未完待续……

Resreach
“AI音频时代”研究小组由扎根电影声音行业的资深人士以及对音频发展有兴趣的年轻音频人组成,核心目标是跟踪并实践当下AI音频技术的发展,未来在内容创作,音频技术方面积极应用,由电影声音网,DiffuSound 弥声工作室提供场地、技术及设备支持。欢迎合作。
由电影声音网,DiffuSound 弥声工作室提供场地、技术及设备支持
(文:AI音频时代)