
DAD团队 投稿
量子位 | 公众号 QbiAI
单目深度估计新成果来了!
西湖大学AGI实验室等提出了一种创新性的蒸馏算法,成功整合了多个开源单目深度估计模型的优势。
在仅使用2万张无标签数据的情况下,该方法显著提升了估计精度,并刷新了单目深度估计的最新SOTA性能。
这一技术突破不仅提升了单目深度估计的鲁棒性,还大幅降低了对标注数据的依赖,使得该技术能够更容易地应用于数据匮乏的场景。
此外,单目深度估计的进步也进一步推动了2D到3D内容转换技术,使得单张图片的3D建模更加精准高效。随着这一研究的推进,单目深度估计将在更多领域实现高效、低成本的三维感知,为人工智能和计算机视觉的发展提供更强有力的支持。
该成果由西湖大学AGI实验室、浙江工业大学等单位的研究人员共同完成的。
目前,该研究的推理代码、模型和Demo已经上线,感兴趣的读者可以通过文章最后的链接体验并试用该技术。

自动驾驶、考古中都会使用单目深度估计
在计算机视觉领域,单目深度估计是一项备受关注的任务,它能够仅凭一张RGB图像推测场景的深度信息,为三维空间的重建提供了关键支持。相比于依赖多摄像头或激光雷达的传统深度感知技术,单目深度估计具有低成本、易部署的优势,因此在多个领域展现出广阔的应用前景。
单目深度估计的应用范围极其广泛,在自动驾驶中,车辆需要精准感知周围环境的深度信息,以确保安全驾驶和高效避障;在机器人导航方面,深度估计增强了机器人的环境感知能力,使其能够自主规划路径、避开障碍物;在增强现实(AR)和虚拟现实(VR)技术中,可靠的深度估计能使虚拟对象更自然地融入现实世界,为用户带来更具沉浸感的体验。

此外,在考古学和文化遗产保护方面,该技术能够对历史文物进行精确的三维重建,避免传统测量手段的损伤风险。影视制作和游戏开发高度依赖深度信息来实现逼真的光影效果和环境渲染,增强沉浸式体验。在2D和3D生成领域,单目深度估计技术也发挥着重要作用。
例如,在图像生成与编辑中,深度信息可用于生成视差效果、动态光照调整、甚至是从单张图片中推理出完整的三维结构。在AI驱动的内容生成(如虚拟角色建模、数字孪生)中,单目深度估计提供了强大的几何信息支持。建筑与室内设计也受益于单目深度估计,设计师可以利用该技术快速构建三维模型,实现虚拟预览,优化空间利用。
尽管单目深度估计拥有巨大的潜力,但其面临的挑战同样不容忽视。在不同光照条件、复杂纹理、动态场景等情况下,现有方法的鲁棒性和精度仍然存在提升空间,限制了单目深度估计在实际应用中的可靠性。此外,深度估计模型往往依赖大规模标注数据进行训练,而获取高质量深度数据集成本较高,这进一步限制了其推广。
Distill Any Depth正是为此而来。
它提出了一种基于跨上下文与多教师模型的蒸馏框架,能够同时从多个深度估计模型中学习,从而提升深度估计的精度和鲁棒性。具体实现过程如下:
单目深度估计伪标签蒸馏的瓶颈:归一化问题
单目深度估计技术旨在通过单张RGB图像推断场景的深度信息,广泛应用于自动驾驶、增强现实及3D场景理解等多个领域。随着技术的不断进步,研究者们逐步提出了更为创新的解决方案,尤其是在归一化深度表示和伪标签蒸馏学习方法方面,前者通过优化深度表征,后者则借助大规模无标签数据来提高模型的泛化能力。尽管这些方法在一定程度上推动了深度估计技术的发展,但仍存在一个显著瓶颈——归一化处理方式的选择。
目前,基于蒸馏的深度估计方法通常依赖全局归一化策略,尽管该策略能够在一定程度上提升模型的稳定性,但却放大了噪声伪标签,进而降低了蒸馏的效果。这一问题尤为突出,尤其在面对复杂的场景时,归一化处理往往限制了模型的性能。因此,如何克服这一挑战,并在蒸馏过程中提高信息传递与学习效率,成为了当前研究中的核心问题。
在图示中,研究人员比较了两种对齐策略:
-
全局最小二乘法:在对齐前对整个图像进行归一化。
-
局部最小二乘法:在裁剪区域内进行归一化对齐。
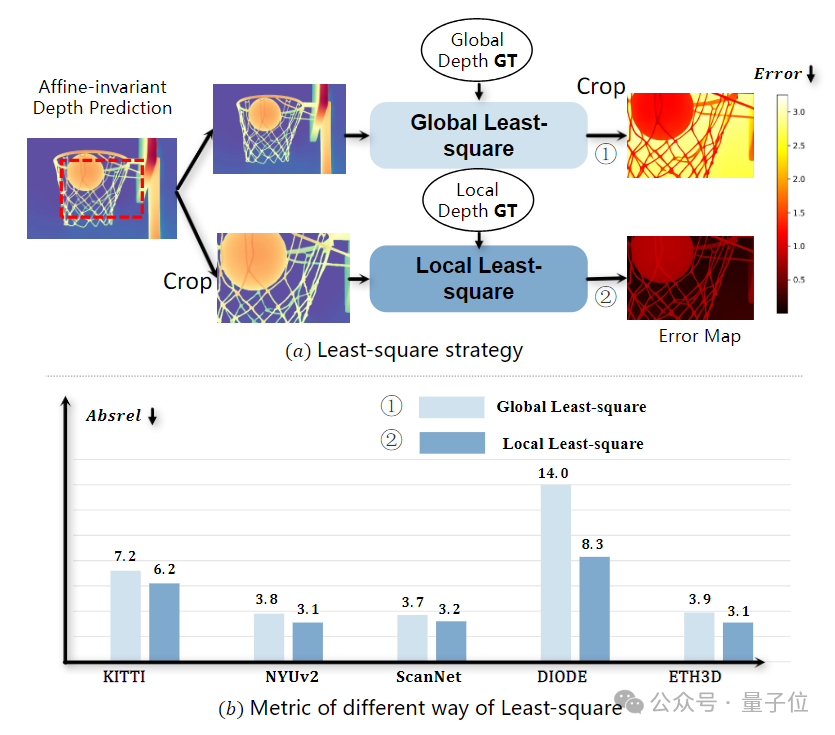
如图所示,局部归一化策略相较于全局归一化,在局部区域的准确性上表现更好。全局归一化会影响到局部精度,而局部归一化则能更好地保留细节信息,因此局部归一化在提升模型性能方面具有更大的潜力。
创新突破:更细化、多教师联合的伪标签蒸馏算法
基于以上的发现,针对传统深度归一化方法中存在的问题,研究团队进行了总结分析,并提出两项创新性技术:
1、系统性分析不同深度归一化策略对伪标签蒸馏的影响:研究团队深入探讨了全局归一化和局部归一化在蒸馏过程中的作用,重点分析了它们对模型性能的影响。特别是在精细化深度预测中,局部归一化相较于全局归一化,能够更好地保留局部细节信息并减小噪声伪标签的影响。通过实验发现,混合归一化方法结合了全局和局部的深度信息,有效提高了预测精度。下图展示了不同归一化策略下,红点标记的归一化区域内的像素分布,结果表明,混合归一化在多个场景中均表现出了优异的性能。

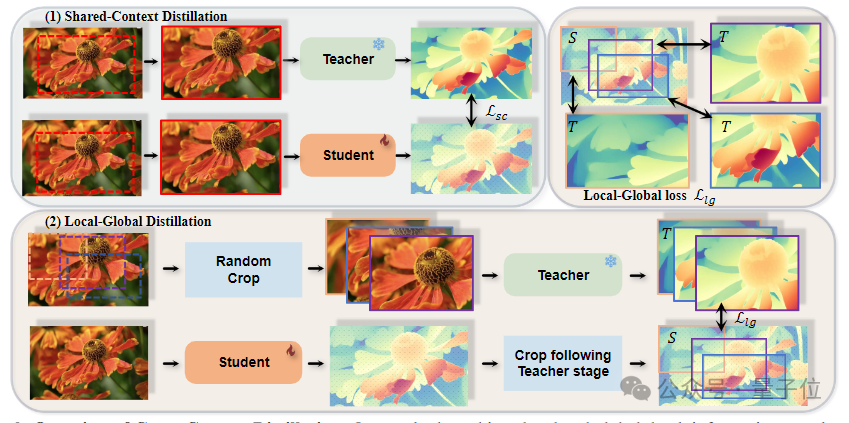
跨上下文蒸馏:针对蒸馏过程中的信息传递问题,研究团队提出了一种结合局部和全局深度信息的蒸馏框架——“跨上下文蒸馏”。该框架通过优化伪标签质量,提高了模型的鲁棒性,具体分为两种场景:
-
共享上下文蒸馏:教师模型与学生模型使用相同的图像进行蒸馏,使得两者之间的深度信息保持一致。
-
局部-全局蒸馏:在该模式下,教师模型专注于重叠区域进行深度预测,而学生模型则在整个图像上进行预测。通过局部-全局损失,确保了局部与全局预测的一致性,从而使得学生模型能够同时学习细节与全局结构,显著提升了深度估计的精度与鲁棒性。
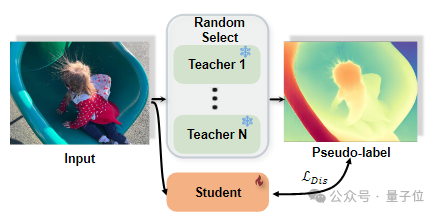
2、多教师蒸馏框架:为了进一步增强蒸馏效果,研究团队引入了多教师模型机制。在每次训练迭代时,随机选择一个教师模型为无标签图像生成伪标签。不同教师模型的互补优势为蒸馏过程提供了更多的知识,使得学生模型能够综合多个视角的深度估计信息。通过这种多教师框架,深度预测的稳定性和准确性得到了显著提高,特别是在面对多样化场景时,模型展现出了更强的鲁棒性。
实验结果
在多个公开基准数据集上的实验结果表明,”Distill Any Depth” 方法在定量和定性分析中均表现出了显著的性能优势,尤其在野外环境中的深度估计任务中,所提出的方法显著提升了模型的鲁棒性和泛化能力。
定性分析
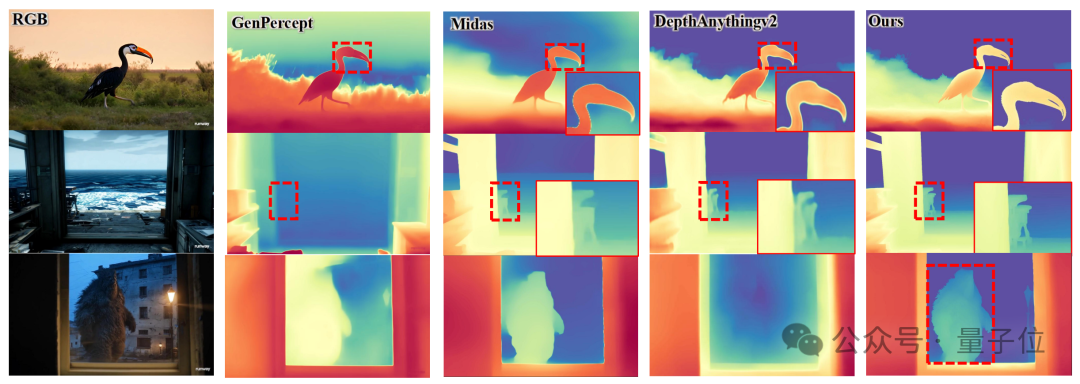
研究团队展示了来自“Distill Any Depth”方法与其他经典深度估计模型(如MiDaS v3.1、DepthAnythingv2、Marigold等)的深度估计结果。与现有的最先进方法相比,团队提出的模型在细节层次上表现得更加精准,特别是在图像中标注位置(如黑色箭头所示)的深度估计上,展现了更细粒度的深度估计效果。
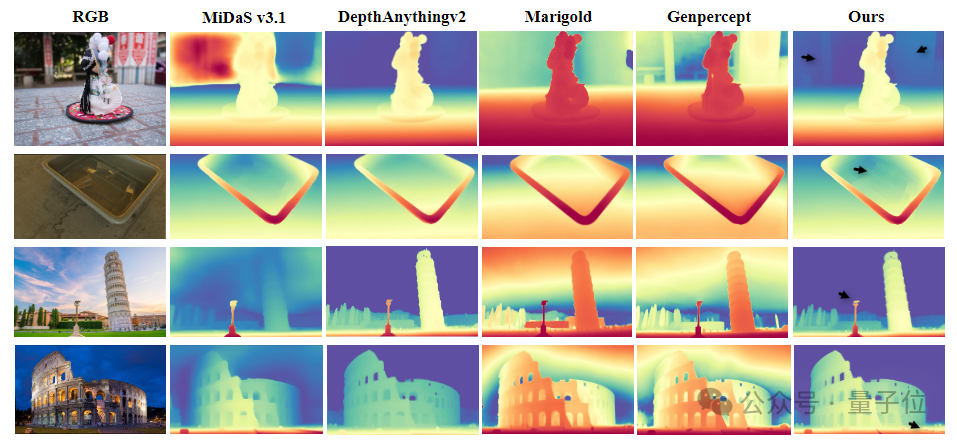
同时下面的大量例子表明,特别是在复杂环境下(如简笔画、头发、卡通场景等),该方法依然能够产生清晰的边缘和更详细的深度图,展示了其卓越的鲁棒性和精度。

定量分析:
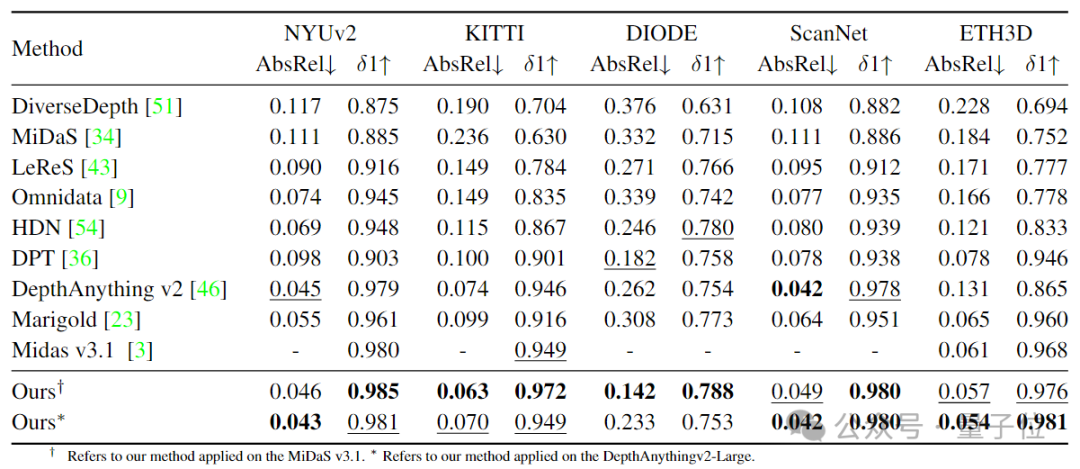
实验结果显示,基于新提出的蒸馏框架,模型在不同benchmark下的深度估计表现显著优于现有最先进方法。尤其是在NYUv2、ScanNet等结构化室内场景和KITTI、DIODE、ETH3D等复杂的户外环境下,所提出的方法都展现出了强大的泛化能力。优化伪标签蒸馏和深度归一化后,学生模型不仅超越了教师模型,还在多个基准测试中创下了新的SOTA,充分证明了该方法的有效性。
总结与展望
总体而言,”Distill Any Depth”方法通过引入创新的多教师蒸馏框架和跨上下文蒸馏技术,显著提高了单目深度估计的精度和鲁棒性。该方法成功克服了传统深度归一化策略的局限,为无标签数据的有效利用提供了全新的思路和解决方案。通过这种技术,深度估计的性能不仅得到了提升,也为进一步拓展深度估计的应用场景奠定了基础。
随着该方法的不断优化和推广,未来有望在自动驾驶、3D重建、增强现实以及AGI等领域中发挥重要作用。特别是在复杂场景下的应用中,预计该方法能够进一步提升模型的泛化能力和实用性,从而推动相关领域技术的突破与进步。
展望未来,”Distill Any Depth”方法仍有进一步发展的空间,尤其是在算法优化、计算效率和跨领域适应性等方面,随着更多创新的出现,单目深度估计技术将在更多实际应用中取得显著进展。
在线试用:
https://huggingface.co/spaces/xingyang1/Distill-Any-Depth
论文链接:https://arxiv.org/abs/2502.19204
项目主页:https://distill-any-depth-official.github.io/
代码仓库:https://github.com/Westlake-AGI-Lab/Distill-Any-Depth
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)