
-
感知(如文本检测、识别)
-
理解(如信息抽取、视觉问答)
多模态大语言模型(MLLMs)的出现为文本丰富的图像理解(TIU)领域带来了新的维度,系统地分析了该领域 MLLMs的时间线、架构、训练流程、数据集与基准测试。
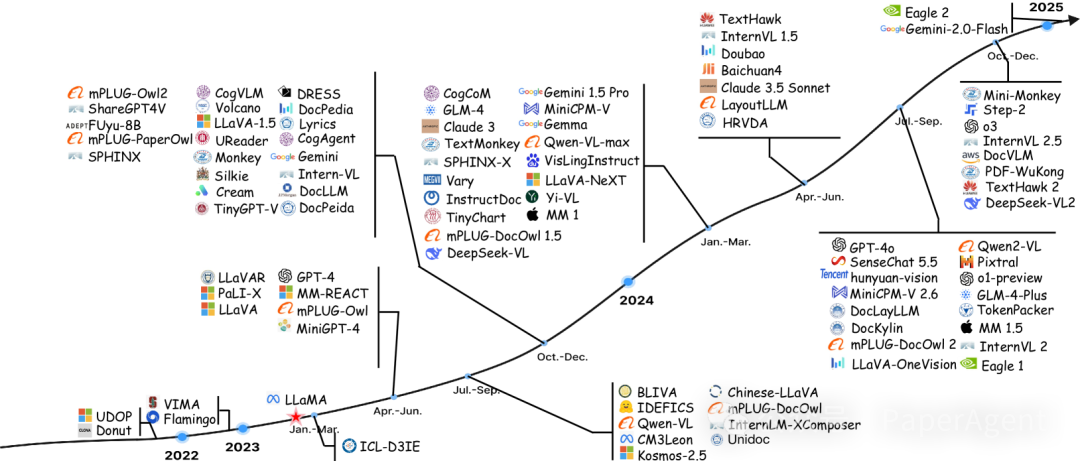
TIU MLLMs时间线
1、模型架构
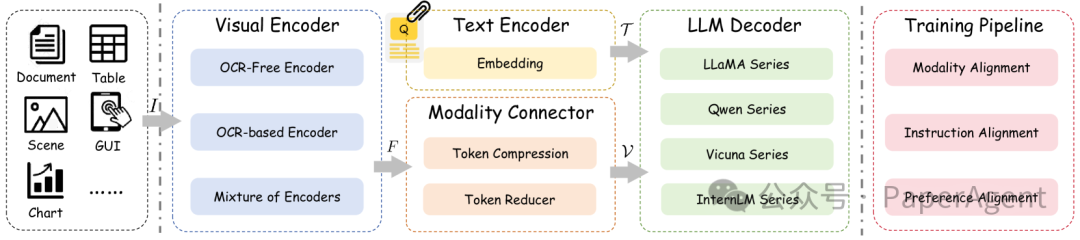
TIU MLLMs的框架通常包括三个核心组件:视觉编码器、模态连接器和LLM解码器。
-
视觉编码器:负责将输入图像转换为特征表示,分为OCR-free(如CLIP、ConvNeXt)和OCR-based(如LayoutLMv3)两种方式。混合编码器结合了两者的优点。
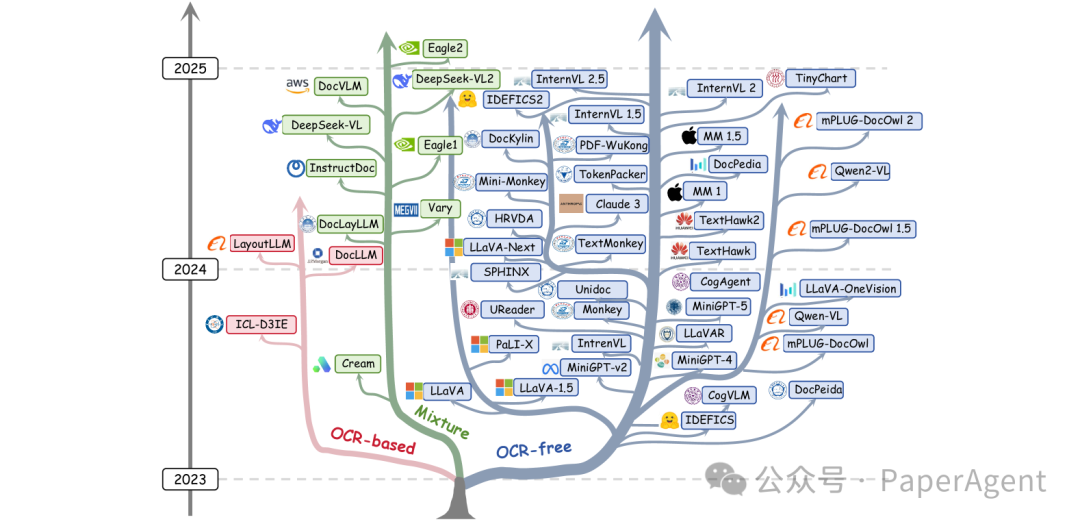
现代LLMs的进化树追溯了近年来语言模型的发展,并突出了其中一些最知名的模型。根据编码器的分类,蓝色分支代表OCR-free(无OCR),粉色分支代表OCR-based(基于OCR),绿色分支代表混合编码器。
-
模态连接器:用于将视觉特征与语言特征对齐,常见的方法包括线性投影、多层感知机(MLP)、交叉注意力等。
-
LLM解码器:将对齐后的特征输入LLM进行推理,生成最终答案。常用的LLM包括LLaMA系列、Qwen系列、Vicuna系列和InternLM系列。
2、训练流程
MLLM的训练分为三个阶段:模态对齐、指令对齐和偏好对齐。
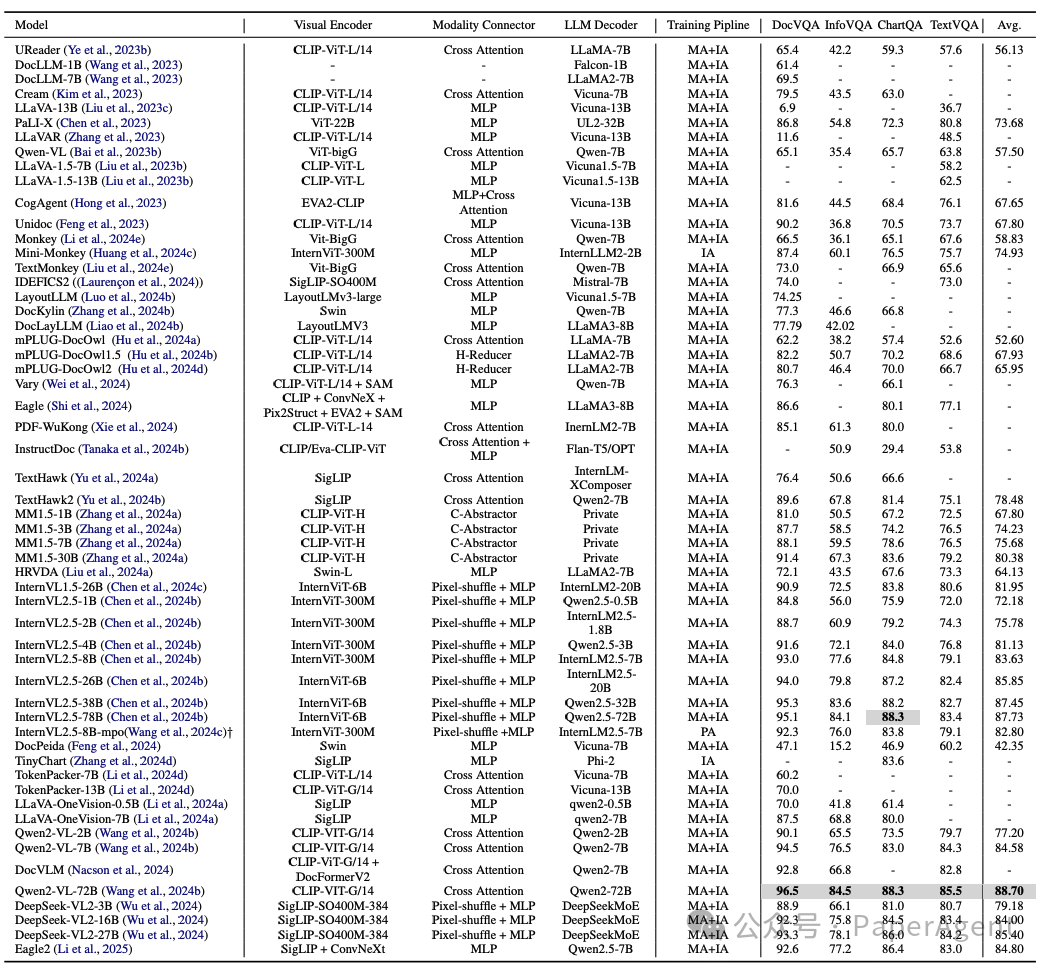
代表性主流多模态大语言模型(MLLMs)的总结,包括模型架构、训练流程以及在TIU领域四个最受欢迎基准测试中的得分。“Private”表示该MLLM使用了专有的大型模型。“†”表示结果是通过下载官方开源模型并在本地测试获得的。
-
模态对齐:通过OCR数据预训练模型,弥合视觉和语言模态之间的差距。任务包括文本识别、文本定位、图表解析等。
-
指令对齐:通过指令微调(SFT)提升模型的多模态感知、跨模态推理能力和零样本泛化能力。分为视觉-语义锚定、提示多样化增强和零样本泛化三个层次。
-
偏好对齐:优化模型输出以符合人类价值观和期望,如通过混合偏好优化(MPO)提升模型性能。
3、 数据集与基准测试
TIU任务的发展依赖于大量专门的数据集和标准化基准测试。这些数据集分为领域特定(如文档、图表、场景、表格、GUI)和综合场景两大类。
文本丰富图像理解领域的代表性数据集和基准测试。每个数据集通常根据其内容、功能和用户需求标记为训练或测试用途。
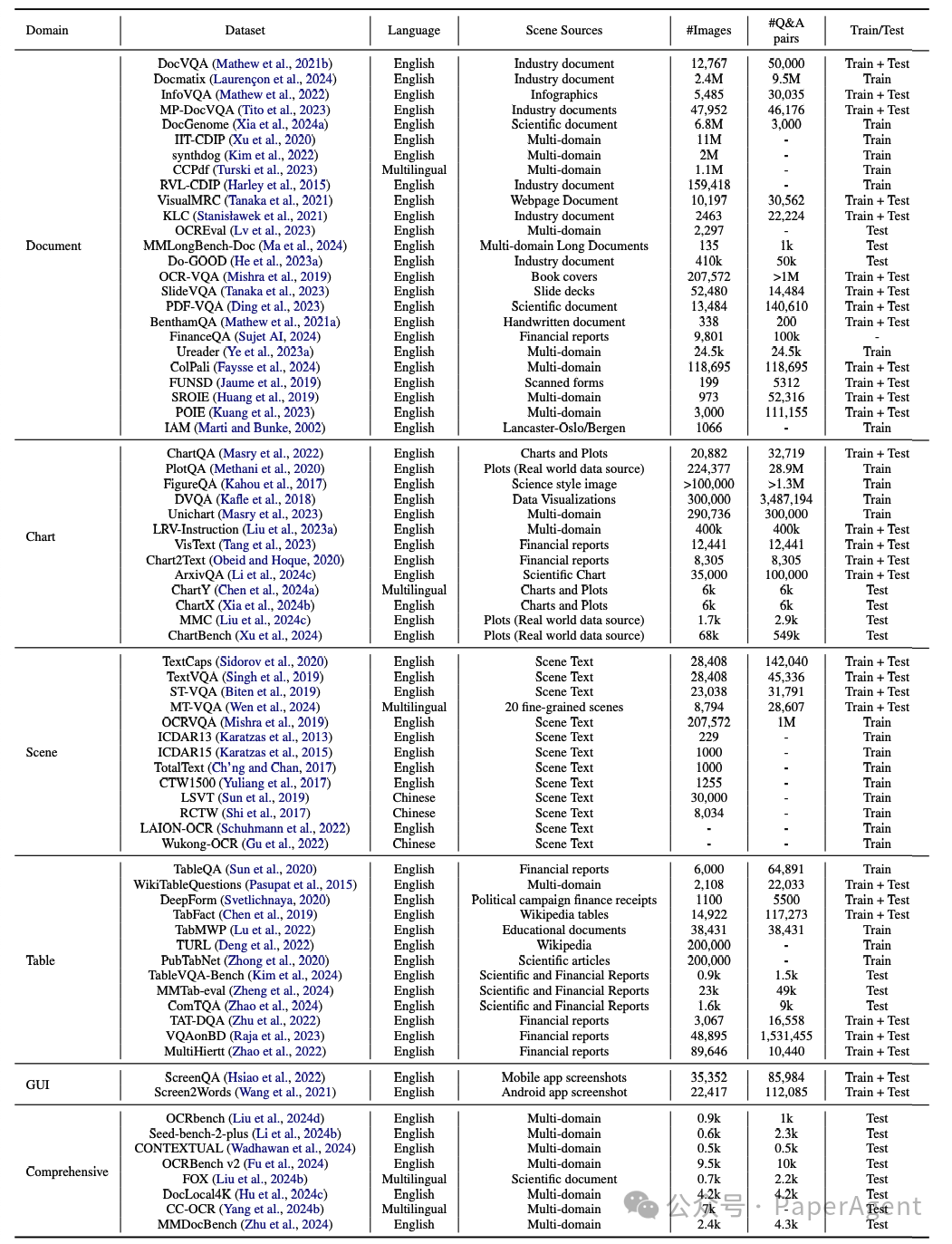
例如:
-
文档:DocVQA、InfoVQA、DocGenome等。
-
图表:ChartQA、PlotQA、ChartBench等。
-
场景:TextCaps、TextVQA、ICDAR系列等。
-
表格:TableQA、WikiTableQuestions、TableVQA-Bench等。
-
综合:OCRbench、Seed-bench-2-plus、MMDocBench等。
https://arxiv.org/pdf/2502.16586Multimodal Large Language Models for Text-rich Image Understanding: AComprehensive Review
(文:PaperAgent)