

DeepSeek R1 催化了 reasoning model 的竞争:在过去的一个月里,头部 AI labs 已经发布了三个 SOTA reasoning models:OpenAI 的 o3-mini 和deep research, xAI 的 Grok 3 和 Anthropic 的 Claude 3.7 Sonnet。随着头部 Al labs 先后释出自己的 reasoning model,新范式的第一轮竞赛暂时告一段落。
各家 reasoning model 各有长板,但都没有拉开大的领先优势:OpenAI 和 xAI 有着最强的 base model 和竞赛解题能力,Anthropic 更关注真实世界的工程问题,Claude 3.7 Sonnet 的混合推理模型可能会成为之后各家发布新模型的标准操作。
在这一波新模型密集发布后的间隙,我们对已有的 reasoning models 发布进行了总结梳理,除了平行比较各些模型的实际能力和长板外,更重要的目标是识别出本轮发布中的关键信号。
整体上,我们还处于 RL Scaling 的早期阶段,就在昨天, Dario 也暗示了 Sonnet 4 即将到来,RL 范式下整个领域还在高速进化,颠覆式的大变化尚未出来。我们也会这个领域保持密切追踪,输出思考。

-
高浓度的主流模型(如 DeepSeek 等)开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传。
01
Reasoning model 还没有出现
全面明显领先的 SOTA
今天我们还处于 RL Scaling 的早期阶段,通用智能第二幕的激烈竞争刚刚开始。
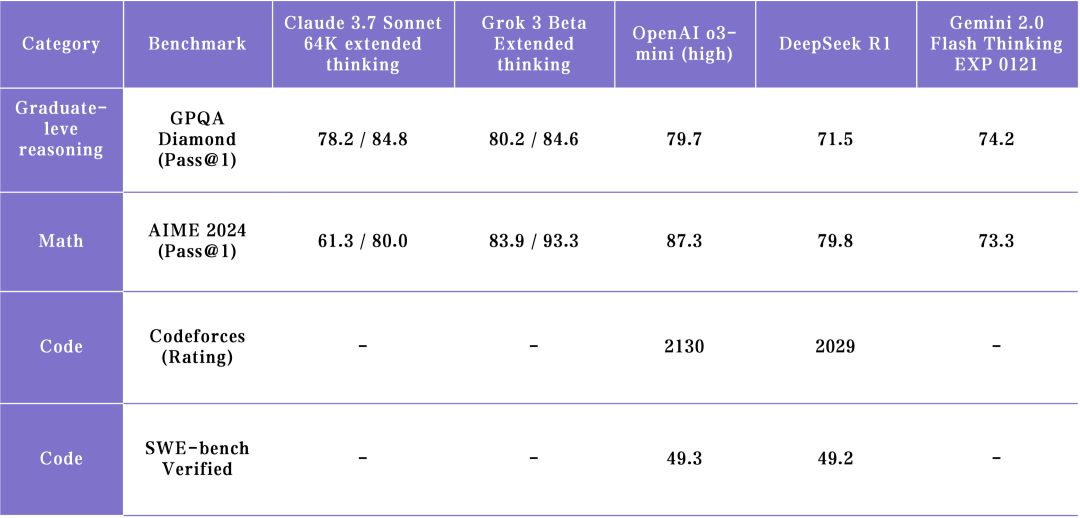
截止到目前,市场上已经发布的 reasoning models 中,还没有一个全方位领先的 SOTA。o3-mini 在推理和数学解题能力上有优势,新发布的 Grok 3 Think 已经追上了 o3-mini ,而 Claude 3.7 Sonnet 在 agentic coding 方面延续并扩大了 Anthropic 的优势:
o3-mini,没有甩开身位差距的领先者:
o3-mini-high 在数理解题能力上是最强的,但在多样化的创作内容能力上不如 Grok 和 DeepSeek 模型。Grok 3 用和 ChatGPT 一个水平的 base model 也达到了同一水平的数理解题能力,这代表着 OpenAI 目前已开放的模型领先优势是不明显的。
Grok 3 Think,充裕资源下的最快追赶者:
xAI 追赶到 o3-mini SOTA 水平的时间比 DeepSeek 更短, Grok 3 Think 各项评分水平接近于 o1-pro,处于 reasoning model SOTA 水平,优于 DeepSeek-R1 和 Gemini 2.0 Flash Thinking。而且 Grok 3(Think) 的推理速度非常快,体验上比 Gemini 2.0 Flash Thinking 还稍快。不过考虑到这是 20 万卡开发出来的 SOTA 模型,所以有些遗憾的是还没有揭示对新范式有启发意义的地方。
Claude 3.7 Sonnet,解决真实世界问题最好的模型:
我们可以把代码能力分为两类,第一类是 engineering code,即如何解决现实世界的代码问题,Claude 3.7 Sonnet 在 coding 和 agentic tool use 上跑分(参考 SWE-bench)大幅领先,并且在解决实际问题中也表现最好;第二类是 competitive code,解决最难的算法竞赛问题,在这类问题上 o3-mini 和 Grok-3 是表现更好的(参考 Codeforce)。Claude 3.7 擅长的能力是对 AI Coding Agent 产品应用更为关键的。
Gemini 2.0 Flash,受关注较少的遗珠:
Gemini 2.0 Flash 的模型能力被低估了。作为“水桶型”模型,它的 reasoning 能力在实际表现中没有明显的长板和短板,不容易受到用户关注 。值得关注的是,他们在多模态理解能力上是绝对的领先者,但多模态融合目前还没有涌现出更高阶的能力,可以作为一个观测 Gemini 的侧重点。
DeepSeek R1,有限资源下的开源创新:
DeepSeeK在有限的集群资源下做了很多创新,并把技术扩散给了整个业界。但当前 R1 的表现暂时落后于其他 top lab,这个落后可能来自 base model 能力的落后。拿短时间的落后去对比其他模型是不公平的,毕竟 DeepSeek 在时间和算力上都有明显的局限, 我们更期待 R2、R3 的持续进步。
02
最强 LLM base model 之争:
Grok 3 可能上限更高
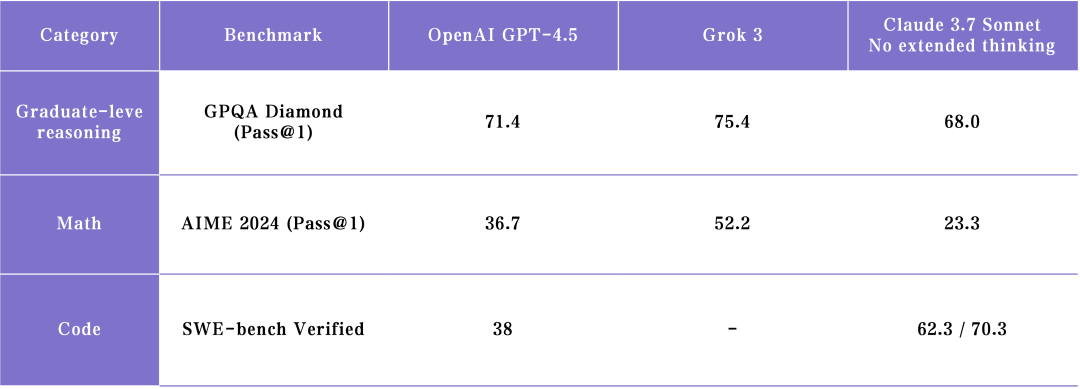
上周 xAI 和 OpenAI 先后放出了自己的最新一代模型,我们也都第一时间使用和收集用户评价后明显感觉 Grok 3 在 base model 的能力上很可能已经领先 GPT 4.5 了。而业界也对于 GPT 4.5 的失望声音居多。
作为同一参数量级的模型, Grok 3 在很多任务上的表现和风格更有优势,下一步更重要的是如何用 RL、 post-training 把 base model 的能力激发出来,毕竟目前 Grok DeepSearch 的用户反馈还不如 OpenAI Deep research 来得好。
03
底座模型预训练依然关键
GPT-4.5 和 Grok 3 的出现市场质疑 base model pre-training 的边际收益是否已经枯竭,但我们认为,这个质疑其实没有考虑到以下两个因素:
1. 高质量的 base model 是强化学习做 reasoning model 的基础,这件事在 DeepSeek R1 论文中已经被验证。要在 RL Scaling 中保持领先还是需要最好的 base model,因此大家不会停止在 base model capbility 上的探索。
2. 今天激发和评估模型能力的方法其实已经远远跟不上模型智能的提升。现在的大部分 benchmark 对模型评估已经进入了“你好我也好”的状态,很难把顶尖模型的能力边界探索出来,”天才只能答 100 分是因为试卷只有 100 分“,模型可能已经表现出了某种未被发现的“暗智能”,需要业界用 RL、post-training 甚至是交互形态来激发出来。
04
Claude 3.7 Sonnet 的混合推理
会成为后续模型发布标配
Claude 3.7 sonnet 的混合推理模型(Hybrid Reasoning Model)是 LLM 和 reasoning model 的结合的新范式,之后大概率所有 AI labs 的模型发布模型都会以类似形式,社区也不会再单独比较 base model 和 reasoning model 的能力。
使用 Claude 3.7 Sonnet 时,用户可以通过“extended thinking” 的设置选择是否需要输出长 CoT:
• 打开 extended thinking,则输出 CoT step-by-step 思考,类似开启了人类的 Slow thinking 并且其思考长度是可以选择的,因此 extended thinking 并不是 0 或 1,而是一个可以拖动的光谱,
• 关闭 extended thinking,则和 LLM 一样直接输出。
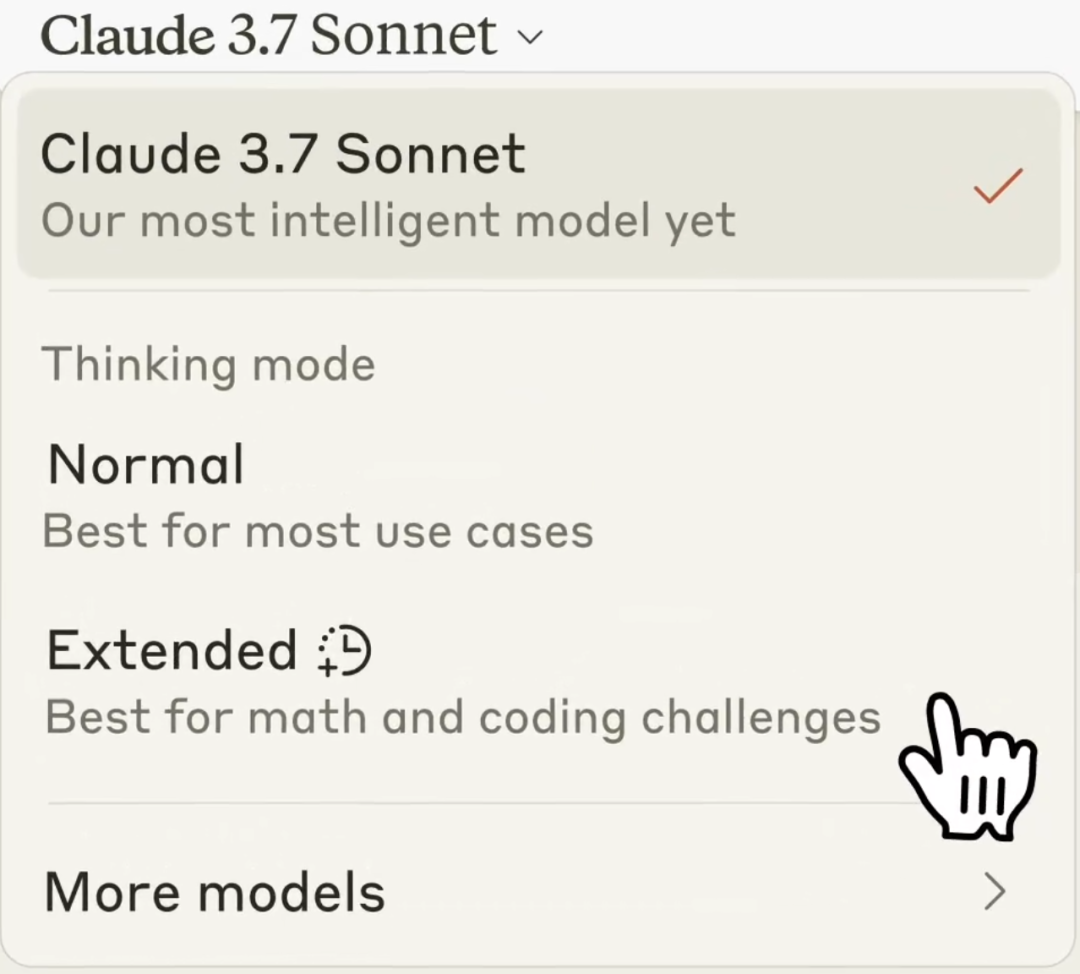 Claude 的这种模式用户只需在最新的模型下自行选择快思考 vs. 慢思考
Claude 的这种模式用户只需在最新的模型下自行选择快思考 vs. 慢思考
这个设计其实 Dario 很早就暗示过,在他看来:base model 与 reasoning model应该是个连续光谱。Claude System Card 中提到,extended thinking 的开关与长短是通过定义 system prompt 来实现的。我们推测要实现这样的融合模型,应该需要在 RL 训练之后通过 post training 让模型学会什么时候应该 step by step thinking,如何控制推理长度。
对于这个新范式,我们的预测是:
1. 之后的 hybrid reasoning model 需要在 fast thinking 和 slow thinking 的选择上更加智能,模型自己具备 dynamic computing 能力,能规划并分配解决一个问题的算力消耗和 token 思考量。Claude 3.7 Sonnet 目前还是将 inference time 的打开和长短交由用户自己来决定,AI 还无法判断 query 复杂度、无法根据用户意图自行选择。
2. 之后所有头部 research lab 发布模型都会以类似形式,不再只是发 base model。
其实现在打开 ChatGPT 上方的模型选择,会弹出五六个模型,其中有 4o 也有 o3,用户需要自行选择是用 LLM 还是 reasoning model,使用体验非常混乱。因此,hybrid reasoning model 从智能能力和用户体验看都是下一步的必然选择。
 ChatGPT 的模式需要用户在不同的 LLM 和 LRM 中做选择
ChatGPT 的模式需要用户在不同的 LLM 和 LRM 中做选择
05
Claude 3.7 Sonnet 延续并扩大了
3.5 的领先优势
Sonnet 3.5 发布后推动了一波 AI Coding 产品能力的升级,3.5 是开发者首选的 coding 模型,Sonnet 3.7 延续、且进一步扩大了这一领先优势,SWE-bench accuracy 相比 Sonnet 3.5 和其它家模型都领先了 20%+。
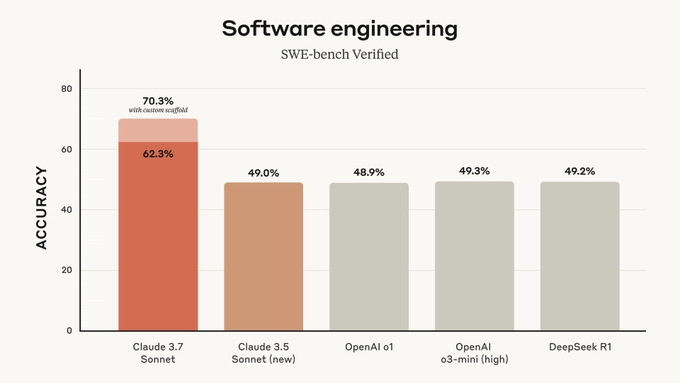
AI Coding 领域还有一个很重要的 benchmark 是“模型单次可以输出多长的可靠代码”。当时 Sonnet 3.5 可以做到 200 行,而 Sonnet 3.7 我们这次初步测试下来可以输出 1000-1500 行代码,是第一个可靠代码长度上千行的模型,所以对于 Sonnet 3.7 推动 AI Coding 产品解锁一波新的 use case 这件事我们相当期待且有信心。
以上这些 benchmark 可能都不足以反应 Sonnet 3.7 在编程应用上的提升,因为 Sonnet 3.7 更在乎解决真实世界问题,而非优化数学或编程竞赛题目。
Devin,Cursor 等 AI coding 产品都在第一时间接入了 Sonnet 3.7,我们观察到 B 端用户的使用反馈主要有几个:
1. Sonnet 3.7 是解决真实世界问题的 SOTA,对于 debug、codebase search、agentic workflow planning 等一系列的任务都是最好的模型(Cursor、Cognition、Perplecity、Vercel 反馈);
2. Canva 和不少个人开发者都反馈 Sonnet 3.7 的代码在前端的设计品味更好了,能生成更 production-ready、且更美观的前端应用。
06
Claude Code 不是 AI IDE 的直接竞对
而是 AI Coding 产品的重要基建
在这次发布中,Anthropic 终于推出了自己的 coding 产品:Claude Code。Claude Code 的产品形态是命令行产品,也就是 GUI 出现之前的操作系统交互界面。这个界面初看起来对用户的使用门槛很高,只有专业开发者才能用起来,让人觉得 Claude 又做了一个比较极客的产品尝试。
但仔细理解产品后,我们认为 Claude Code 其实是 AI Coding 产品走向 AI-native 的核心组件,它并不是只面向人类用户设计的。
也就是说,Anthropic 发布这个产品,不是为了和 AI IDE 或 Coding Agent 直接竞争终端用户,而是给他们、以及领域其他竞争者提供重要的基建。这一产品定位确实也符合 Anthropic 一直以来的风格, OS 级别的问题 > 具体 application。
Claude Code demo 展示出的是一个命令行版的 Cursor Composer 或者 Windsurf Cascade。用户可以输入自然语言需求,Claude 就会基于其强大的 tool use 能力,开始理解完整的代码库、并修改文件,实际编程中有一定的自我更正能力。
因为 3.7 Sonnet 的 action scaling 能力, Claude Code 又展现出了 Devin 水平的 agentic 能力,可以像一个开发实习生一样去主动探索代码库,找到需要重点理解和使用的代码模块。
这带来的优势是 Claude Code 正在帮助 AI onboard 人类传统代码库。只有让 AI Agent 在大型代码库中扎根更深,才能让 AI Coding 不再只是从 0 到 1 prototype 用来生成软件 prototype 的工具,而能够直接形成 AI-native 开发工作流,开始更深入地参与到 CI/CD。
再往前推演一步,“MCP +Claude Code + Computer use agent”的组合有潜力成为新一代的 Coding Agent OS:reasoning model 在这个环境中进行 long horizon reasoning,包括任务规划、执行、验证和迭代。之前 Anthropic computer use agent 的步子迈得太大,AI 很难一下子理解整个 GUI 操作系统。而现在命令行是更 AI-native 的交互界面,一直是一个适合 heavy machine operation 的环境,这个环境的输出都是高度 veifiable 的,因此这是一个适合给 AI agent 进行协同开发的环境,面向的不只是普通用户。
07
Agent playbook 再升级:
action scaling ,verifiable environment
和 online learning
Claude 3.7 博客中提到了一系列新的关键能力, action scaling,能够连续做 function call 和 tool use ,并持续根据环境的反馈迭代,直到把一个开放式问题解决。其中的几个关键词为我们揭示了 AI Agent 要落地未来的关键 roadmap:
• RL 带来的 action scaling 能力:
这个能力中包含了两部分,tool use 和 long horizon reasoning。Tool use 的可靠性是让一个连续行为能够可靠的必要条件。要实现可靠的 action scaling,每一个 tool use 步骤必须比较准确,不然过程中的错误会以乘法形式累加:例如一个 10 步的推理任务,如果每一步的准确率是 90%,但叠加起来 10 步任务的准确率就只有 35%。同时 long horizon reasoning 保证了当发生了错误之后,能让 Long CoT 回到正确的轨迹上。
• RL 需要构建 verifiable environment:
如果我们定义中的 AI Agent 是要解一个开放性的问题,能够充分在各个 open-ended 领域泛化,那么单纯的 RL Scaling 并不足以实现 AI Agent 的目标。
这是因为 RL 最擅长在 verifiable environment 中不断增强能力解决一个端到端的问题,但现实世界的问题往往太过开放没有这样的环境。潜在由高上限的 AI agent 环境主要是集中在这几个领域:OS browser、Coding、游戏、科研、搜索,这几个环境都有比较明确可用的信号。
• 持续学习能力 online learning/ iterative RL:
个性化智能的 agent 需要模型自己根据新的环境做动态的 RL fine-tuning。实现这样持续学习的 agent 有两个明显的瓶颈:
其一,暂时没有看到成熟的 RL fine-tuning 算法能像 LoRA 那样更新部分参数(LoRA 也不够好,学习到的知识无法泛化,只能用来做个性化需求);
其二,模型智能程度不够:没法在新环境中自己试错,并做好 rejection sampling 来找到好的数据更新自己的参数。
08
OpenAI Deep Research 是 RL scaling 范式下
第一个PMF 的产品形态
Deep research 是第一个高度可用的 agent 原型,其完成任务的准确性是比 Devin 要高很多的。其实 Gemini 其实是最早发布这个产品形态的,但当时模型可用性还比较低。
说到产品形态,Deep research 是 RL scaling 范式下第一个 PMF 的产品形态,就像 ChatGPT 出现时一下打开了 chatbot 类产品形态一样。Grok、Perplexity 等公司的积极跟进是对这个产品形态的认可。
我们收集了用户对 OpenAI Deep research、Gemini、Perplexity Deep Research 和 Grok DeepSearch 的评价,发现 OpenAI Deep research 的用户体验有一定领先,在深度研究上做得更好:
• 对网页内容理解深度出色,超越 perplexity/google 式的简单索引,猜测是对网站内容做了更完整的语义理解;
• 信息幻觉少,大部分来源都经过严谨的 reference;
• 在生成回答前会先问 Follow-up,能对用户意图做比较好的识别。这是一个很好的 Fast thinking + Slow thinking 结合思路;
• 更长的提示可以促使 AI 生成更长、更详细的报告,说明未来用户可以调整某种参数,控制 AI 生成答案的回答深度。
在 Deep research 团队与红杉的访谈中,团队提到 Deep research 是基于 o3 对 research 任务做了端微调。开源领域也有很多个版本,基于 DeepSeek R1 或 o3 api,在不微调的情况下也做到了不错的效果,这些系统普遍有以下元素:
• 不断迭代研究:通过迭代生成 query、处理结果并根据发现进行深入研究,执行深度研究。
• 深度与广度控制:可配置的参数控制研究的广度(广泛性)和深度(深入性)。
• 智能 follow-up:生成跟进问题,以更好地理解用户意图。
• 并行处理:高效地处理多个搜索和结果处理任务。
09
RL Fine-tuning 是 Reasoning model 落地的
downside 保证;
但 RL Scaling 的效果更好
垂直领域 Fine-tuning 效果到底如何?这个功能最早是 OpenAI 在 2024 年 12 月发布会的第二天公布的,发布演示很惊艳,不需要太多数据点就能做到不错的效果。但实际情况似乎有些出入:
1. 之后实际能看到的客户数据点很有限。
2. OpenAI 最近发布的 Competitive Programming 报告反而表明:reasoning model 做通用 RL scaling 比 domain RL finetuning 效果更好。
具体模型的表现如何?o3 在 competitive coding 上的能力比在 IOI 数据上 finetune 的 o1 模型效果更好。也就是说,RL finetuning 只能对有专有数据的细分场景有优势,通用场景可能还是很难比过 RL scaling。所以从通用智能的角度来说,我们有信心对 o4 保持乐观。另外,OpenAI 对微调数据的量级及组成 Setting 只字不提,虽然这是 OpenAI 的一贯操作,但很难判断这是否是面向投资者、避免被 R1 Finetuning 超越的说辞。
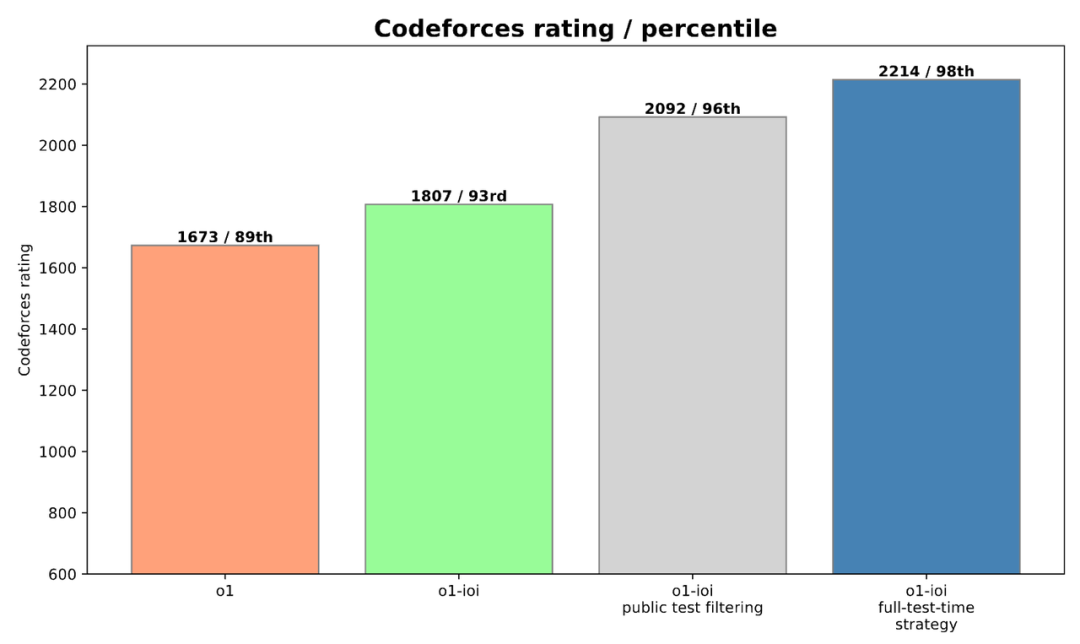 o1 使用 Domain-specific RL fine-tuning paired 配合 advanced selection heuristics(a simple filter rejecting any solution that failed public tests),提升效果显著
o1 使用 Domain-specific RL fine-tuning paired 配合 advanced selection heuristics(a simple filter rejecting any solution that failed public tests),提升效果显著

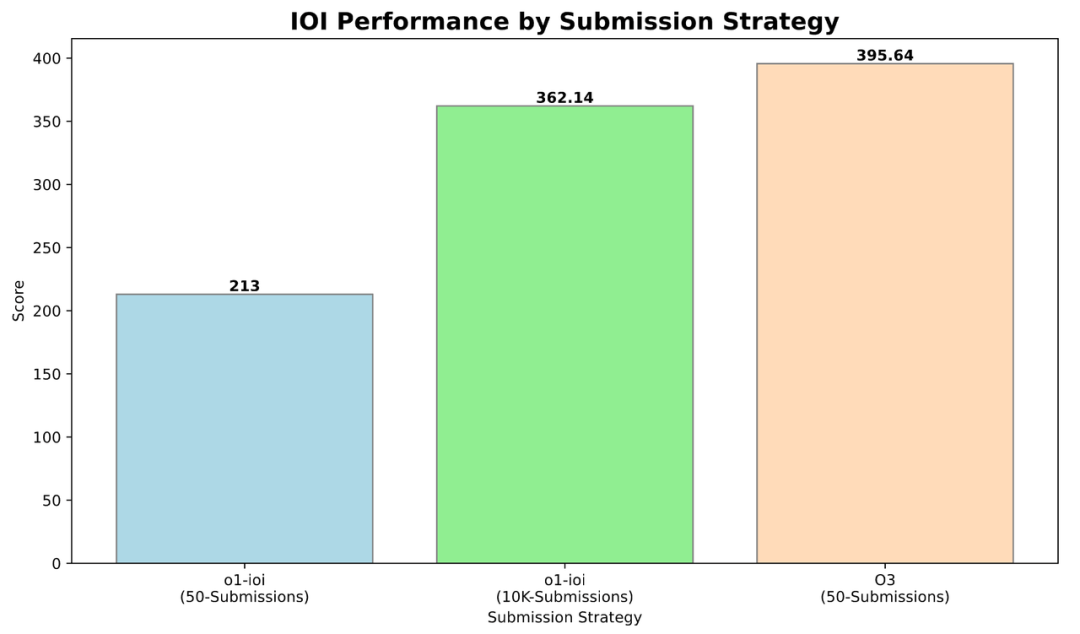
不过,至少 RL Fine-tuning 能够保证 Reasoning model 落地的 downside:Competitive Programming 文章中做了一个有意思的尝试:在 o1 微调的模型上,他们做了比较完善的 test time strategy:将每个 IOI 问题分解为其组成子任务,为每个子任务从 o1-ioi 中采样 10,000 个解决方案,然后采用基于聚类和重新排序的方法来决定从该集合中提交哪些解决方案。在这样的策略下,o1 能做到接近 o3 的水平,o3 可以做到接近人类最高水平。所以,从垂直领域落地来说,R1 和 R2 开源 fine-tuning 也是十分值得关注的信号。
(文:Founder Park)