
新智元报道
新智元报道
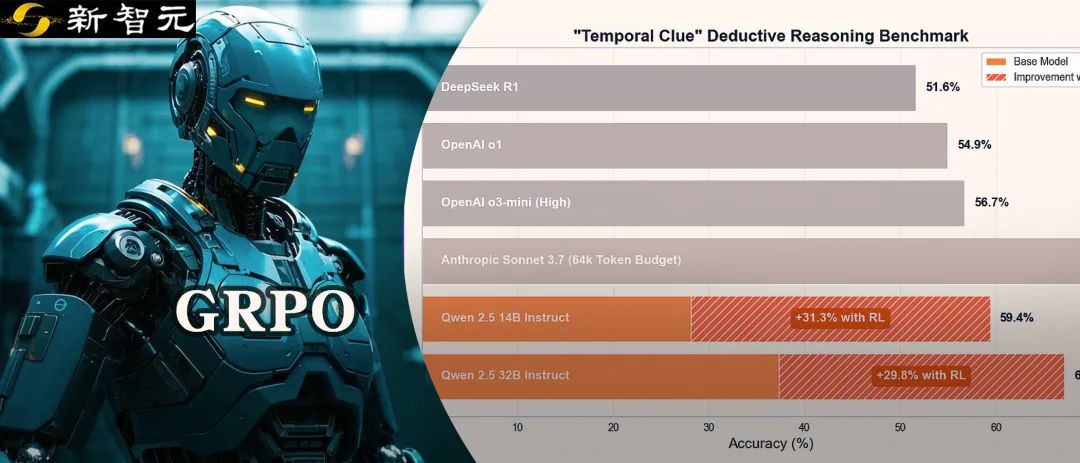
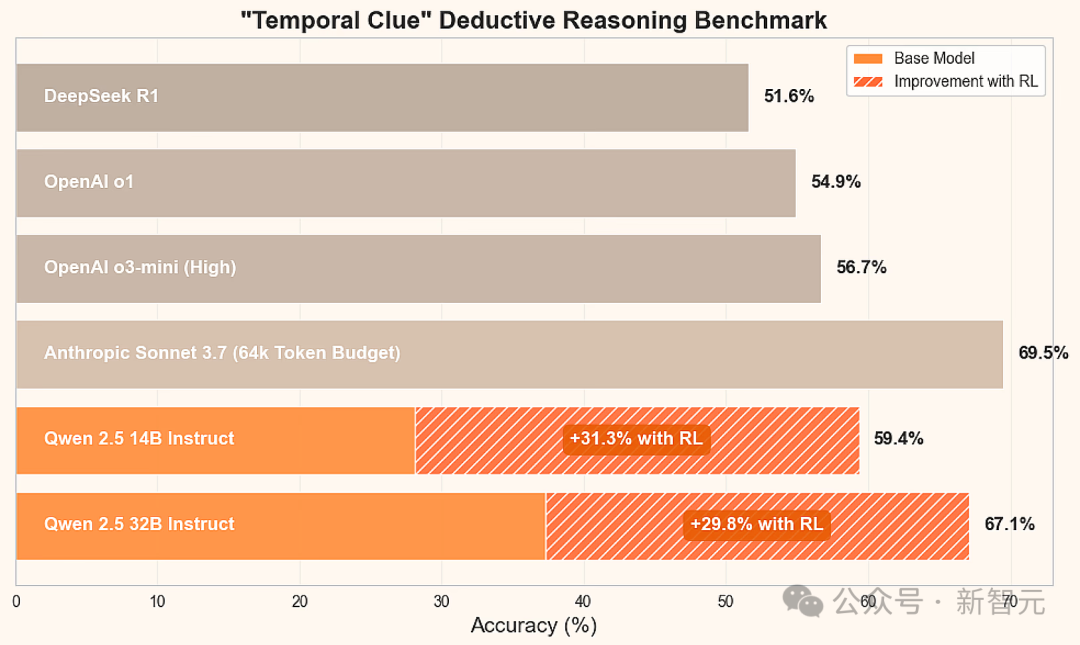
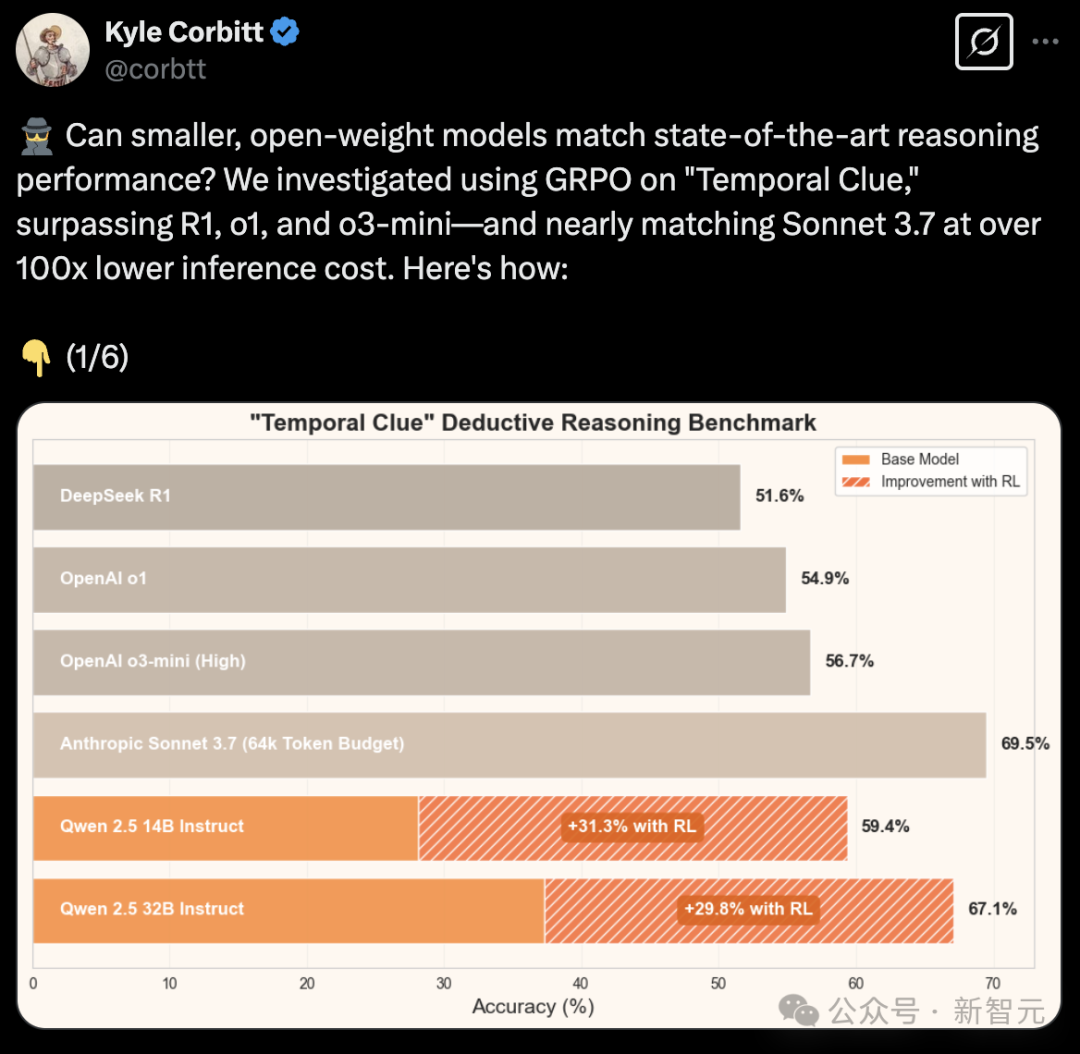
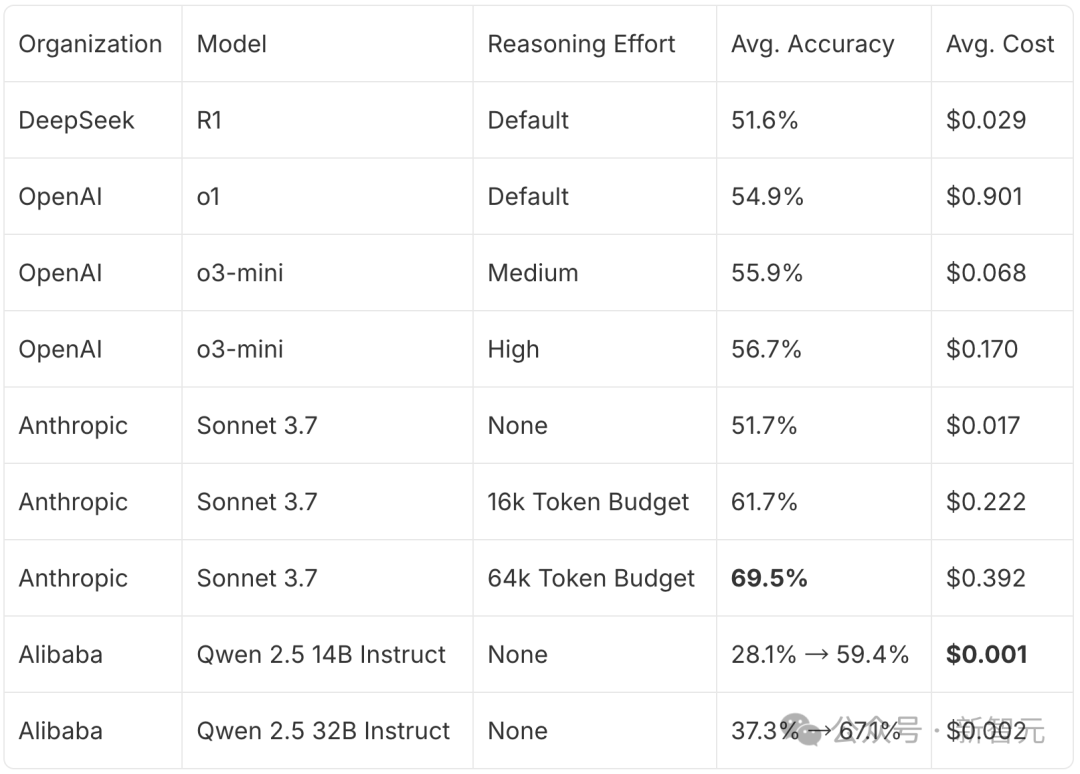
【新智元导读】32B小模型在超硬核「时间线索」推理谜题中,一举击败了o1、o3-mini、DeepSeek-R1,核心秘密武器便是GRPO,最关键的是训练成本暴降100倍。
小模型在复杂推理任务中,能否逆袭,达到或超越顶尖LLM?

AI推理新战场:时间线索
基准测试
在一个寒冷的冬夜,富有且神秘的John Q. Boddy先生为几位亲密伙伴举办了一场小型但奢华的晚宴。然而,夜晚以悲剧收场——清晨,Boddy先生被发现死在都铎庄园的某个房间内。以下为涉案嫌疑人名单…
小模型逆袭秘诀:GRPO
-
生成模型对谜题任务的响应 -
对响应进行评分,并估计每组对话完成的优势(这是GRPO中「分组相对比较」的部分) -
使用由这些优势估计指导的裁剪策略梯度对模型进行微调 -
使用新的谜题和最新版本的模型重复这些步骤,直到达到峰值性能
-
激活检查点(Activation Checkpointing) -
激活卸载(Activation Offloading) -
量化(Quantization) -
参数高效微调(PEFT),例如低秩适应(LoRA)
-
多设备和单设备训练 -
参考模型加载和权重交换,用于计算KL散度 -
使用组ID和父ID进行高级因果掩码计算 -
GRPO损失集成和组件日志记录
-
模型:Qwen 2.5 Instruct 14B和32B -
每次迭代的任务数:32 -
每次迭代每个任务的样本数:50 -
每次迭代的总样本数:32*50=1600 -
学习率:6e-6 -
Micro-Batch大小:14B模型为4个序列,32B模型为8个序列 -
批大小:可变,取决于序列数量
100次迭代,实现SOTA

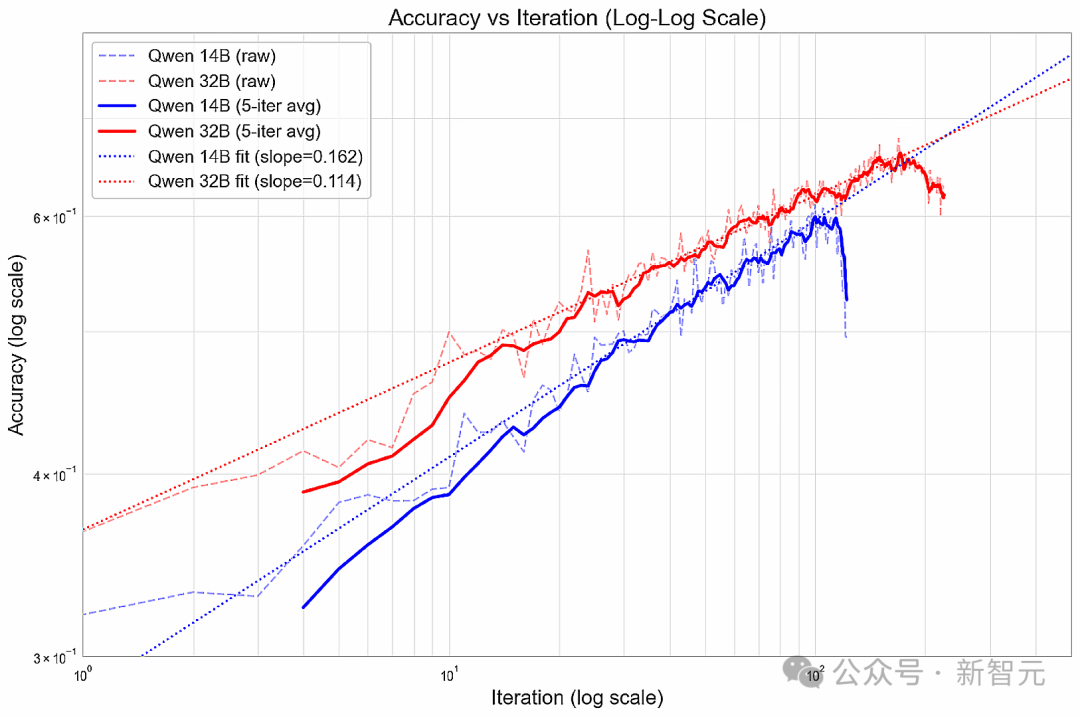
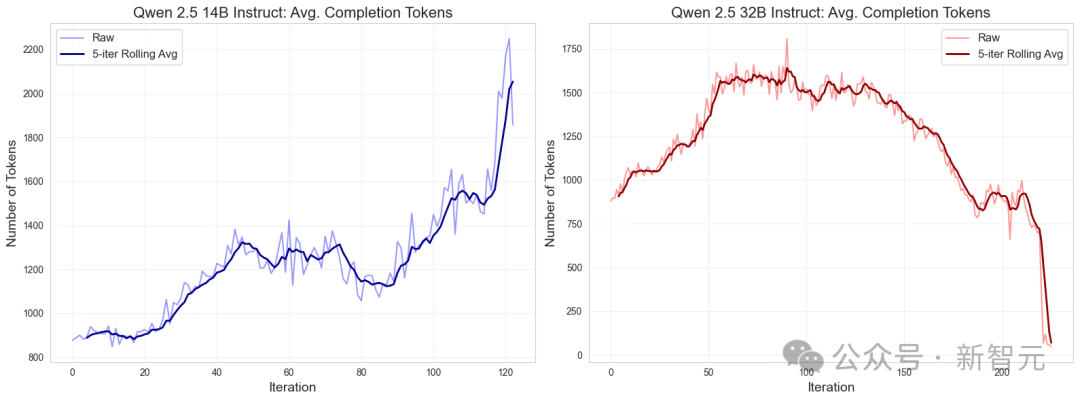
-
在未经训练的基础模型中,Sonnet识别出了6个推理结论,其中5个被判定为错误 -
在经过100多次迭代训练后的模型中,Sonnet识别出了7个推理结论,其中6个被判定为符合逻辑
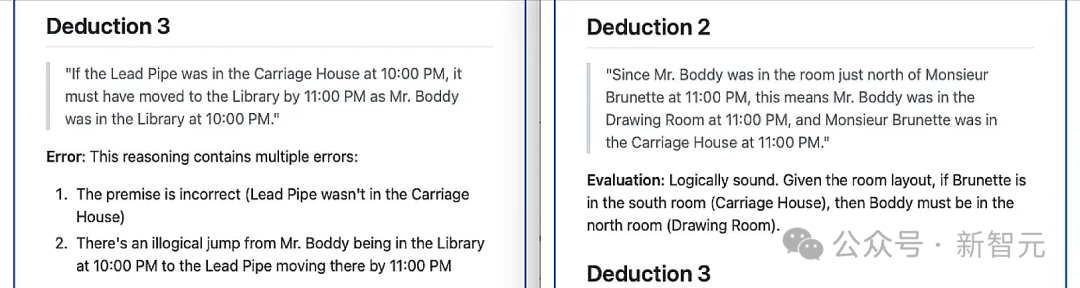
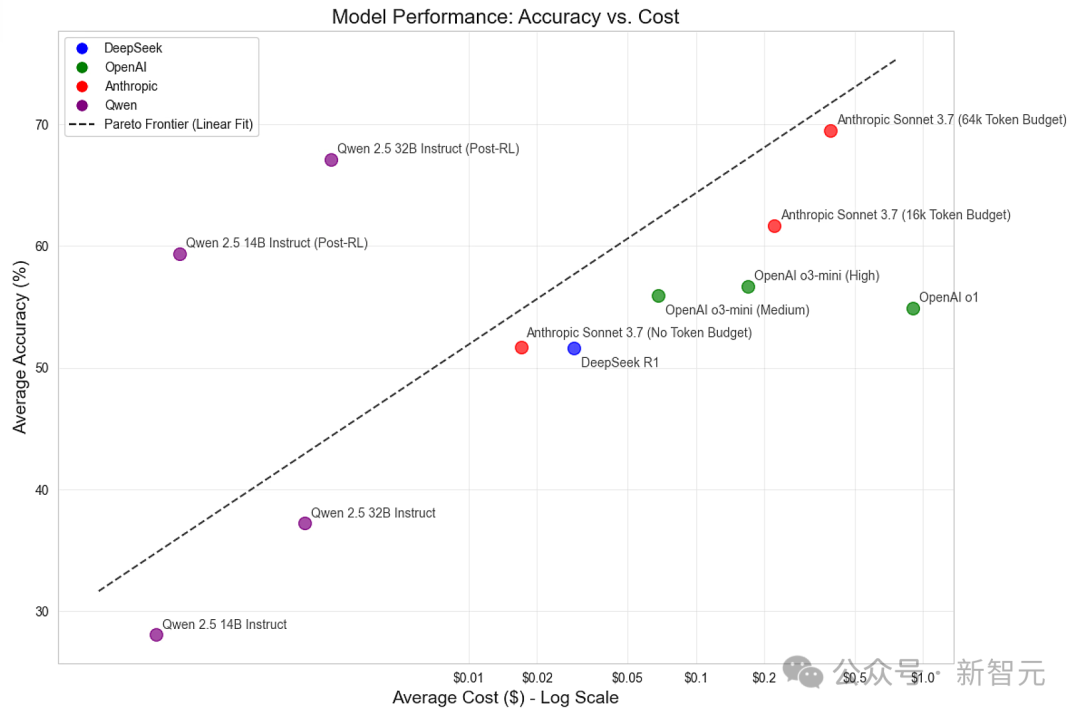
随着工作的圆满完成,我们彼此相视一笑,随即叫了一辆双轮马车返回贝克街——这里正是复盘「案情」的绝佳场所。
(文:新智元)