

©作者 | 胡逸凡
单位 | 同济大学
研究方向 | 时序预测

背景介绍
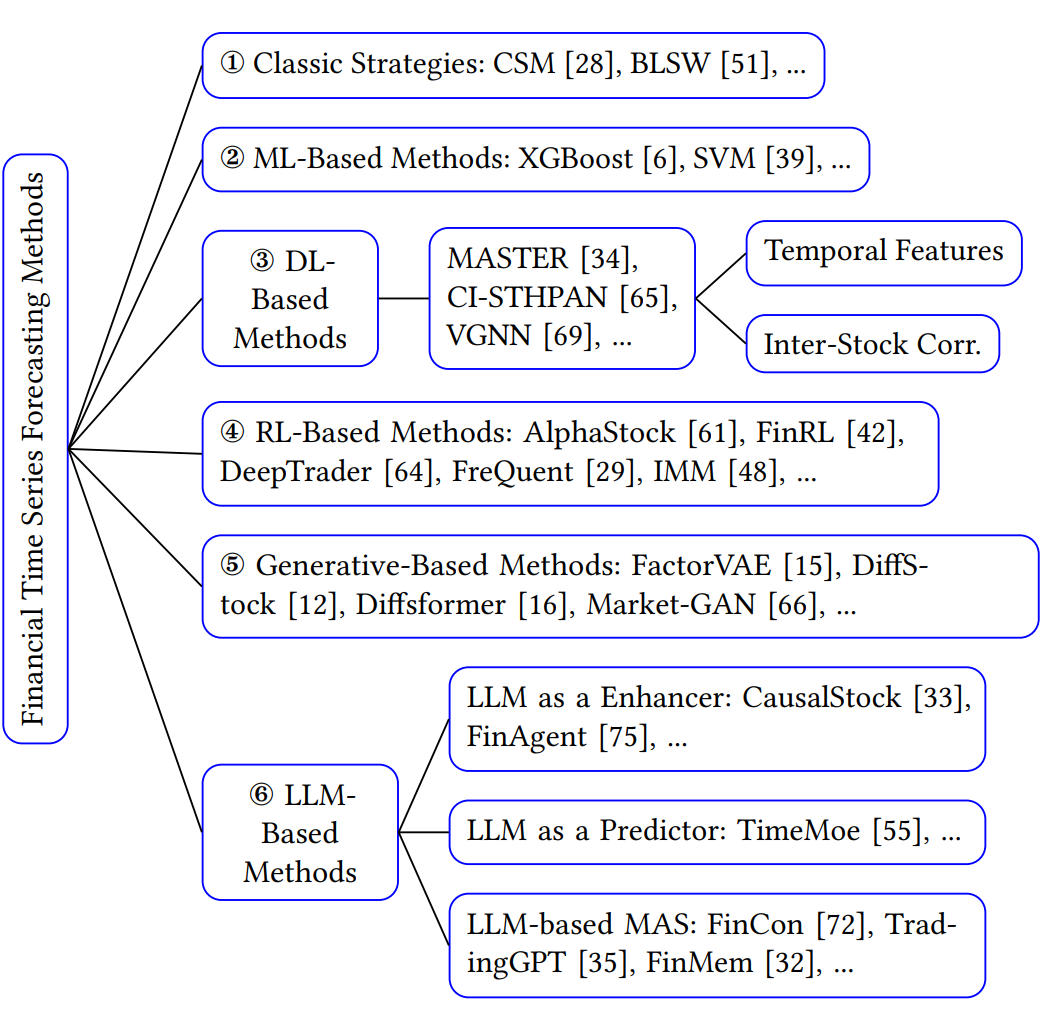
▲ 图1 现有金融时间序列预测方法分类
金融时间序列预测在量化投资领域中占据着核心地位。由于市场价格变化受到多种因素的影响,如宏观经济数据、政策变化、突发事件、市场情绪以及全球经济环境等,准确预测股票、债券、外汇等金融资产的价格和市场趋势,对于投资者和金融机构来说至关重要。
金融市场的动态特性和复杂性要求投资者依赖先进的预测技术来识别潜在的投资机会,并进行风险控制。因此,金融时间序列预测不仅是量化投资的核心环节,也直接关系到市场参与者的决策效率和资本的有效配置。
现有的解决金融时间序列预测任务的模型层不出穷,如图 1 大体可以分为 6 类。包括根据经验得出的经典策略,传统机器学习算法,深度学习算法,强化学习算法,生成模型以及金融大语言模型。随着越来越多的不同种类的方法被提出,金融时间序列模型的公平和全面评测成为了亟待解决的问题。
如图 2,该领域现有的评测方法常常无法避免以下三个局限性:
多样性鸿沟(Diversity Gap),难以包含金融市场中全部的波动模式,导致模型泛化能力不足,尤其在未见过的模式上比如极端黑天鹅事件;
标准化匮缺(Standardization Deficit),现有研究使用的数据集、评测标准差异较大,导致不同模型的比较缺乏一致性;
落地脱节(Real-World Mismatch),现有的评测往往忽略了真实交易中的限制条件,导致基于投资组合的指标过高,难以在真实场景中落地。
为了解决以上问题,同济大学国家级(省部共建)网络金融安全协同创新中心团队联合清华大学、上海人工智能实验室提出了金融时序评测框架(FinTSB),它构建细粒度、多元的股票波动模式数据集来实现多样性涵盖,倡导采用多维度的全面评测指标并设计统一的评测框架来增强公平一致性,考虑真实的交易场景限制来对齐落地业务,辅助金融时间序列预测评测。

论文标题:
FinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
作者单位:
同济大学,清华深圳国际研究生院,上海人工智能实验室
论文链接:
https://arxiv.org/pdf/2502.18834
框架代码:
https://github.com/TongjiFinLab/FinTSB
awesome paper仓库:
https://github.com/TongjiFinLab/awesome-financial-time-series-forecasting

▲ 图2 现有金融时间序列评测方法的三大局限

FinTSB
2.1 数据集构建
在本文中,我们首先利用真实的历史数据来构建数据集,具体流程包括数据脱敏、波动模式分类、数据预处理、序列指标评价等等步骤。大体上,我们把金融时间序列的波动模式分为了上升、下降、波动、极端事件共 4 类。在获得数据集后,我们通过 Hexbin 图验证了 FinTSB 的全面性。
如图,相比 ALSP-TF(IJCAI’22)、ADB-TRM(IJCAI’24)、CI-STHPAN(AAAI’24)所采用的 2013 年到 2017 年的数据,LSR-iGRU(CIKM’24)、FinMamba 所采用的 2018 年到 2023 年的数据,LARA(IJCAI’24)、RSAP-DFM(IJCAI’24)采用的 2008 年到 2020 年的数据,FinTSB 涵盖了最丰富的波动模式,全面反映了变化多端的金融市场。
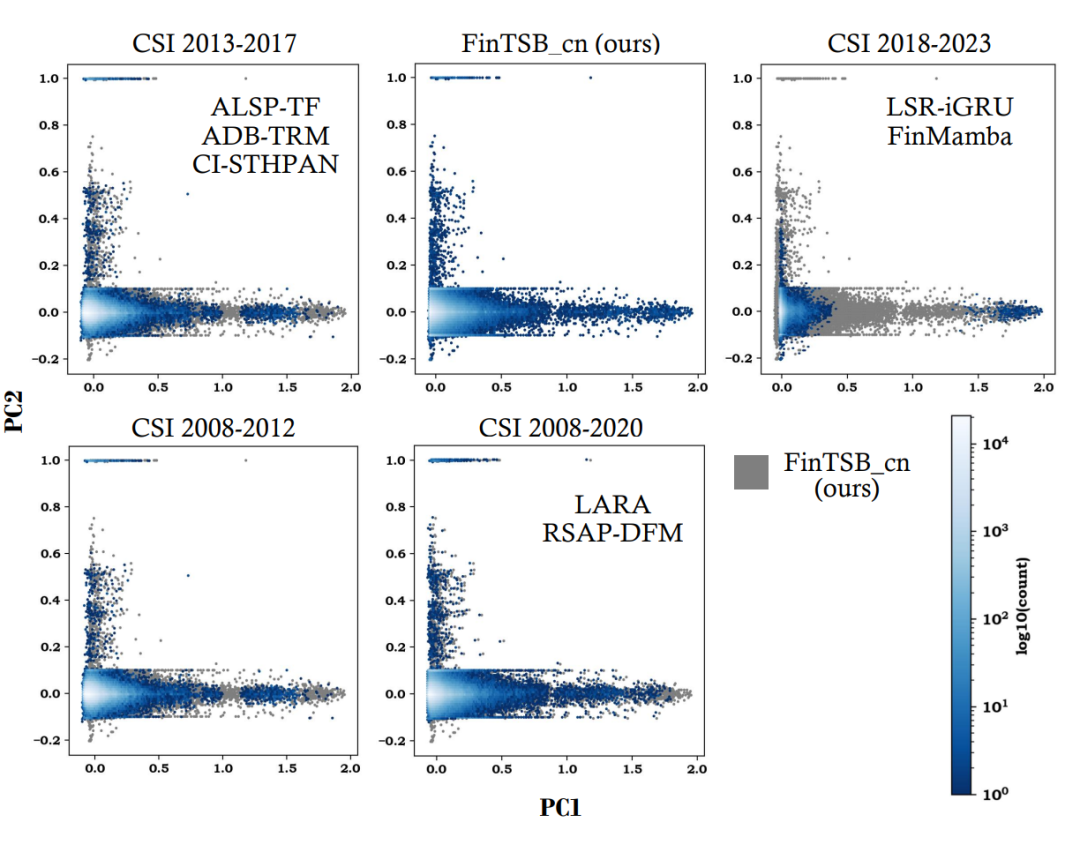
▲ 图3 FinTSB 与其他工作所采用数据集的多样性对比
我们还计算了非平稳性、可预测性等指标来观察不同波动模式的性质,可以看到极端事件的可预测性最低,而上升或下降模式则更容易被预测。

▲ 图4 FinTSB 的统计指标
2.2 统一评测框架设计
本模块中,我们首先倡议实用 3 个维度的全面指标进行评测,包含误差指标(MSE、MAE)即最经典的时序预测误差衡量方式,排名指标(IC、ICIR、RankIC、RankICIR)评价预测收益率与真实收益率之间的相关性和排名准确性,以及基于投资组合的指标(ARR、AVoL、MDD、ASR、IR)评价根据预测结果生成投资组合的表现。
之后我们搭建了基于 Qlib 的统一评测框架,主要分为 4 个模块,数据层用于数据预处理和数据构建,训练层用于调用各种基于不同 backbone 的模型,回测层用于根据预测结果生成符合真实市场限制的投资组合并进行评测,反馈层用于记录日志、保存输出结果和可视化文件。
在训练层中,我们的损失函数全部采用了回归误差损失和排名损失。


▲ 图4 固定96输入长期预测的实验评估
2.3 回测交易协议
我们采用了 TopK-Drop 投资组合方法,用以避免 TopK 方法带来的高换手率问题,并考虑交易手续费。具体来说,在交易日 时,根据预测的日收益率排名可以构造一个等投资权重的股票集合 ,其中共 支股票。
由于换手率限制,每天需要交易的股票数量 需要满足 。我们选择 为全部标的股票的 10%,即 , 为 5。另外,我们按照每次交易的 0.1% 收取手续费。

实验分析
3.1 各个模型在 FinTSB 表现
我们评测了各种 backbone 在 FinTSB 上的表现如下表所示,其中加粗为最好的指标,下划线为最不好的指标。我们发现没有一个模型可以在几乎全部的指标上达到最优,及时基于相同的架构,模型间表现差异也比较大,我们将其归因于各个模型捕获时间依赖和股票间关系的能力差距。
另外,值得注意的是,随着参数量增加,基于 LLM 的模型表现先表差,在超过某个参数阈值之后,模型效果显著变好,体现了 LLM 在金融时间序列预测任务上的涌现能力。其次,传统机器学习算法与经典策略并不如想象中不如更新的深度学习模型等等,说明了全面考虑各种类型模型的重要性。
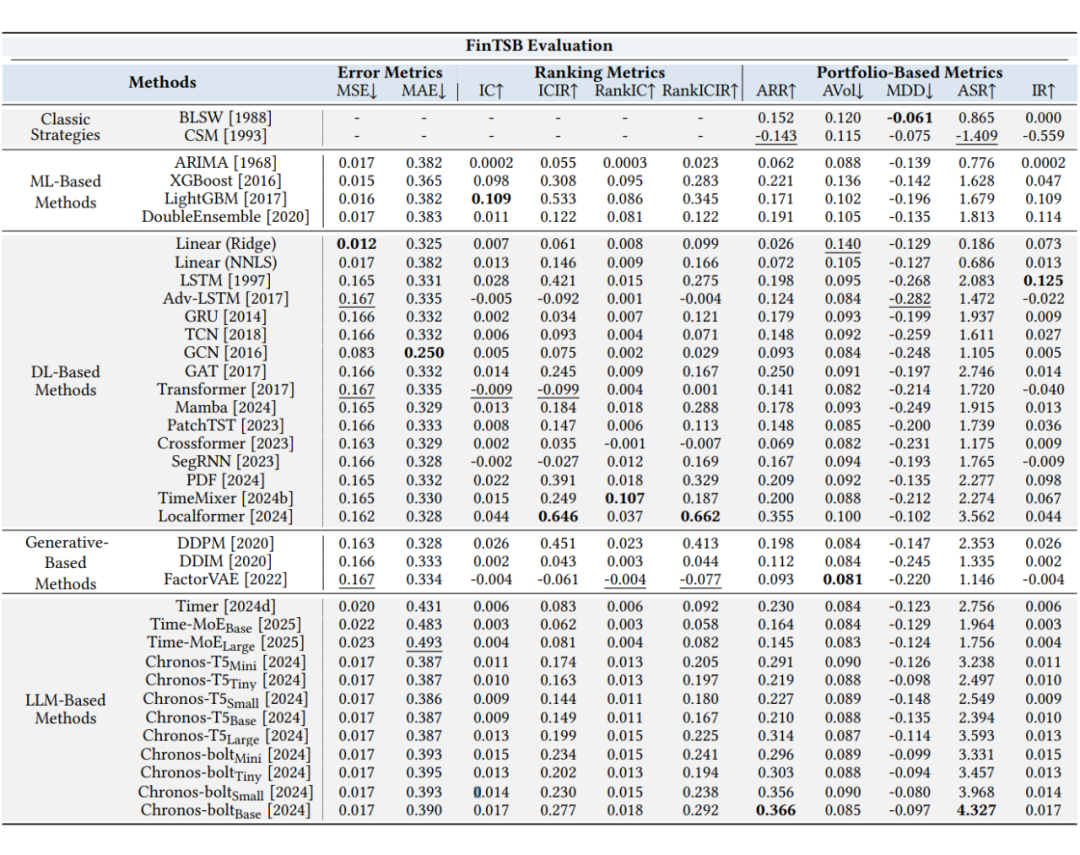
▲ 图6 FinTSB 实验结果
3.2 真实市场迁移学习实验
为了验证 FinTSB 的有效性,我们将在 2024年全年的中国股市上评测了再 FinTSB 上训练的模型,其中,在 FinTSB 上表现好的 GAT 、Transformer、Localformer 等模型在真实历史市场上也有较好的表现。
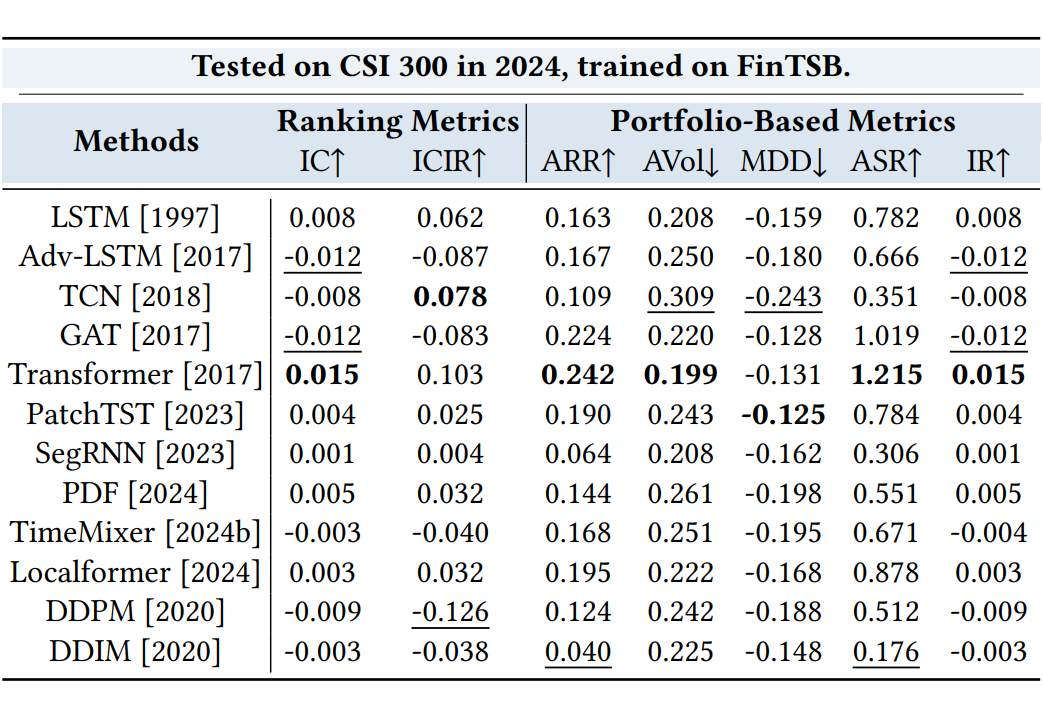
▲ 图7 迁移学习实验结果
3.3 交易实时性要求
TimeFilter 与同样与多种现有方法在 4 个基准数据集上进行了测评。短时预测任务中数据的时变特性较强,对模型的局部依赖捕捉能力提出了更高要求。图 6 实验结果表明,TimeFilter 在捕捉短期波动方面表现出色,超越了多种先进模型,尤其在 PEMS08 数据集。
为了考察算法的效率能否满足真实交易环境的实时性要求,我们还可视化了多个算法的推理时间、内存占用和年化夏普比率。

▲ 图8 推理时间比较

结论
在本文中,我们提出了 FinTSB,一个针对 FinTSF 的综合基准,解决了三大挑战。
首先,通过将股票走势分为四种类型,确保评估更具多样性和代表性,填补了以往研究中的“多样性缺口”。其次,引入统一评估框架,标准化多维度性能指标,缓解“标准化不足”,使跨研究比较更可靠。最后,结合关键市场结构因素,克服“现实世界不匹配”,减少性能指标的失真。
FinTSB 为 FinTSF 方法的评估与发展提供了坚实平台,有望推动 FinTSF 在实际应用中的进一步研究。
(文:PaperWeekly)