

0x0. 前言
本片文章解析一下vLLM/SGLang中 awq int4的反量化kernel,这个kernel触发条件为当输入x的shape的tokens<256时,这个时候会先把int4的awq权重使用awq_dequantize反量化回float16,然后调用PyTorch Matmul执行float16的乘法,代码位置见: https://github.com/vllm-project/vllm/blob/b82662d9523d9aa1386d8d1de410426781a1fa3b/vllm/model_executor/layers/quantization/awq.py#L162-L184
def apply(self,
layer: torch.nn.Module,
x: torch.Tensor,
bias: Optional[torch.Tensor] = None) -> torch.Tensor:
qweight = layer.qweight
scales = layer.scales
qzeros = layer.qzeros
pack_factor = self.quant_config.pack_factor
out_shape = (x.shape[:-1] + (qweight.shape[-1] * pack_factor, ))
reshaped_x = x.reshape(-1, x.shape[-1])
# num_tokens >= threshold
FP16_MATMUL_HEURISTIC_CONDITION = x.shape[:-1].numel() >= 256
if FP16_MATMUL_HEURISTIC_CONDITION:
out = ops.awq_dequantize(qweight, scales, qzeros, 0, 0, 0)
out = torch.matmul(reshaped_x, out)
else:
out = ops.awq_gemm(reshaped_x, qweight, scales, qzeros,
pack_factor)
if bias isnotNone:
out.add_(bias)
return out.reshape(out_shape)
本文要解析的就是这里的 vllm ops.awq_dequantize这个kernel,这个kernel的代码单独抽出来只有几十行代码,但是代码中涉及到的魔法和数学有点多,如果不了解这里的原理就会很痛苦,所以我这里来详细解析一下。vllm ops.awq_dequantize这个算子的原始来源是FasterTransformer仓库,然后sglang的sgl-kernel也有一份针对这个算子的干净实现,并通过调整线程块有更快的速度,我这里直接针对这份代码来解析,链接见:https://github.com/sgl-project/sglang/blob/main/sgl-kernel/csrc/gemm/awq_kernel.cu#L7-L127
还需要说明一下,对于AWQ/GPTQ来说,权重的量化不是PerChannel的而是GroupWise的,也就是在K方向会有GS组Scales和Zeros,例如假设K/GS=128,那就是在K方向有128行的Weight共享一个Scales和Zeros。因此,它和PerChannel的差异就是需要在反量化的时候乘以Scales并加上Zeros。除此之外,AWQ本身需要在Activation计算之前乘以它自己的ActScale。在下面的Kernel中,针对的是weight,K方向就是行(row)方向。
0x1. 接口函数
// PyTorch接口函数,用于AWQ权重反量化
torch::Tensor awq_dequantize(torch::Tensor qweight, torch::Tensor scales, torch::Tensor qzeros) {
// 获取输入张量的维度信息
int qweight_rows = qweight.size(0);
int qweight_cols = qweight.size(1);
int group_size = qweight_rows / scales.size(0); // 计算量化组大小
// 设置CUDA网格和块的维度
int x_num_threads = 16;
int y_num_threads = 16;
int x_blocks = qweight_cols / x_num_threads;
int y_blocks = qweight_rows / y_num_threads;
// 确保在正确的CUDA设备上执行
const at::cuda::OptionalCUDAGuard device_guard(device_of(qweight));
// 创建输出张量,与scales具有相同的数据类型和设备
auto output_tensor_options = torch::TensorOptions().dtype(scales.dtype()).device(scales.device());
at::Tensor output = torch::empty({qweight_rows, qweight_cols * 8}, output_tensor_options);
// 获取各个张量的数据指针
auto _qweight = reinterpret_cast<int*>(qweight.data_ptr<int>());
auto _scales = reinterpret_cast<half*>(scales.data_ptr<at::Half>());
auto _zeros = reinterpret_cast<int*>(qzeros.data_ptr<int>());
auto _output = reinterpret_cast<half*>(output.data_ptr<at::Half>());
// 配置CUDA核函数的执行参数
dim3 num_blocks(x_blocks, y_blocks);
dim3 threads_per_block(x_num_threads, y_num_threads);
// 获取当前CUDA流并启动核函数
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
dequantize_weights<<<num_blocks, threads_per_block, 0, stream>>>(
_qweight, _scales, _zeros, _output, group_size, qweight_cols);
// 返回反量化后的权重张量
return output;
}
需要注意的点是,kernel的输入是int4类型的,输出是float16类型的,然后输入的shape是[qweight_rows, qweight_cols],输出的shape是[qweight_rows, qweight_cols * 8]。由此,我们也可以看出输入数据的元素是一个32位整数 source,它包含了8个4位整数(每个4位可以表示0-15的值)。这8个4位整数被紧密地打包在一起,如下图所示:
[4bit][4bit][4bit][4bit][4bit][4bit][4bit][4bit]
接下来,在kernel launch配置方面,使用二维的线程网格和线程块,并且每个线程处理输入Tensor中的一个元素,非常直观:
int x_num_threads = 16;
int y_num_threads = 16;
int x_blocks = qweight_cols / x_num_threads;
int y_blocks = qweight_rows / y_num_threads;
dim3 num_blocks(x_blocks, y_blocks);
dim3 threads_per_block(x_num_threads, y_num_threads);
0x2. dequantize_weights kernel 流程
// 权重反量化的CUDA kernel,最大线程数为256
__global__ void __launch_bounds__(256) dequantize_weights(
int* __restrict__ qweight, // 量化后的权重
half* __restrict__ scales, // 量化比例因子
int* __restrict__ qzeros, // 量化零点
half* __restrict__ output, // 输出的反量化权重
int group_size, // 量化组大小
int qweight_cols) { // 量化权重的列数
// 计算当前线程处理的列和行索引
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
// 获取当前处理位置的零点,并反量化为fp16x2格式
uint4 zeros = dequantize_s4_to_fp16x2(qzeros[col + (row / group_size) * qweight_cols]);
// 加载对应的缩放因子
uint4 loaded_scale = *(uint4*)(scales + 8 * col + (row / group_size) * qweight_cols * 8);
// 将量化权重反量化为fp16x2格式
uint4 weight_fp16 = dequantize_s4_to_fp16x2(qweight[col + row * qweight_cols]);
// 对每个fp16x2元素执行(weight - zero) * scale操作
// 处理第一对fp16值
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.x) : "r"(weight_fp16.x), "r"(zeros.x));
asm volatile("mul.rn.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.x) : "r"(weight_fp16.x), "r"(loaded_scale.x));
// 处理第二对fp16值
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.y) : "r"(weight_fp16.y), "r"(zeros.y));
asm volatile("mul.rn.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.y) : "r"(weight_fp16.y), "r"(loaded_scale.y));
// 处理第三对fp16值
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.z) : "r"(weight_fp16.z), "r"(zeros.z));
asm volatile("mul.rn.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.z) : "r"(weight_fp16.z), "r"(loaded_scale.z));
// 处理第四对fp16值
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.w) : "r"(weight_fp16.w), "r"(zeros.w));
asm volatile("mul.rn.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.w) : "r"(weight_fp16.w), "r"(loaded_scale.w));
// 计算输出指针位置并存储结果
half* output_ptr = output + 8 * col + 8 * row * qweight_cols;
*(uint4*)output_ptr = weight_fp16;
}
这里整体是非常好理解的,我们根据线程id定位到当前线程处理的列和行索引之后分别加载零点zeros,缩放系数loaded_scale和权重weight_fp16并对zeros/weight_fp16应用dequantize_s4_to_fp16x2反量化kernel把当前行列所在的int32类型的值(8个int4)反量化为8个half类型的输出值,注意这里是用4个half2来存储的。然后使用(weight - zero) * scale操作来完成反量化的过程。
这里解析一个asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(weight_fp16.x) : "r"(weight_fp16.x), "r"(zeros.x));指令:
这行代码使用了CUDA PTX,用于执行半精度浮点数(fp16)的减法操作。它的基本语法为:
asm [volatile] ("汇编指令" : 输出操作数 : 输入操作数 : 可能被修改的寄存器);
下面是详细解析:
-
asm volatile: -
asm关键字表示这是内联汇编代码 -
volatile修饰符告诉编译器不要优化或重排这段汇编代码,确保它按照指定的顺序执行 -
sub.f16x2 %0, %1, %2;\n: -
这是实际的CUDA PTX汇编指令 -
sub.f16x2是CUDA的指令,表示对两个并排的fp16值(packed half2)执行减法操作 -
%0, %1, %2是占位符,分别对应后面定义的输出和输入操作数 -
\n是换行符,用于格式化汇编代码 -
: "=r"(weight_fp16.x) : "r"(weight_fp16.x), "r"(zeros.x)); -
第一个冒号后的 "=r"(weight_fp16.x)是输出操作数,=r 表示这是一个输出到通用寄存器的值 -
第二个冒号后的 "r"(weight_fp16.x)和"r"(zeros.x))是两个输入操作数,r 表示它们来自通用寄存器
通过这个指令就实现了反量化中的减零点的功能,kernel中其它的ptx指令类推。
0x3. dequantize_s4_to_fp16x2 kernel(魔法发生的地方)
这段代码对应的原理在nvidia 2023年夏日专场其实简单讲了一下,我这里结合当时的PPT复述一下这里的原理,通过这个复述读者稍后就可以知道代码中的那一堆魔术和用于计算的PTX指令是做了什么了。注意下面引用的图来BiliBili NVIDIA英伟达频道 上传的《TensorRT-LLM中的 Quantization GEMM(Ampere Mixed GEMM)的 CUTLASS 2.x 实现讲解》。
FasterTransformer 高效的Int8/Int4 快速Convert为FP16
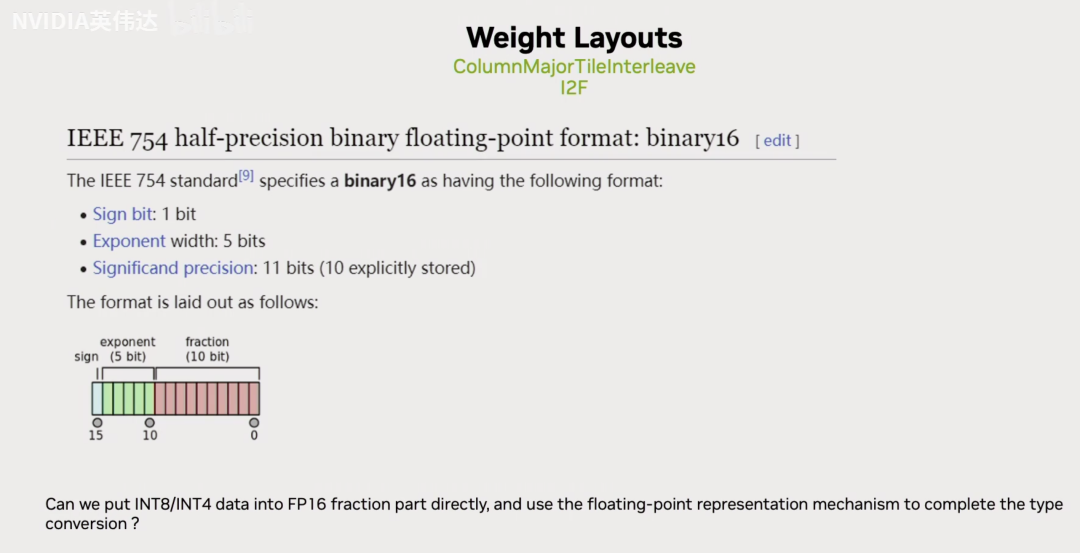
这张slides展示了FP16的IEEE 754标准,一个16bit的数里面包含1个符号位,5个基码位,10个尾数。

假设我们有一个uint8的数143,如果我们把它放到实际的FP16的尾数位里面去,那么我们是否有办法通过合理的设置基码位把143表达出来呢?那我们按照已知的FP16的数值计算方法,拿基码位的二进制前面加上一个1.x,然后去乘以2的(基码位的值-15)次方,我们已知143对应的实际上对应的是下面的值。假设我们想用这个FP16的值来表达Int8,我们可以发现如果x=25的话,我们把上面的FP16的值减去1024就是下面的143了。因此,我们只需要把int8的值放到尾数位,然后把它的基码位设置成25,然后再把FP16的数值结果减去1024就可以得到UINT8转换到FP16的值。
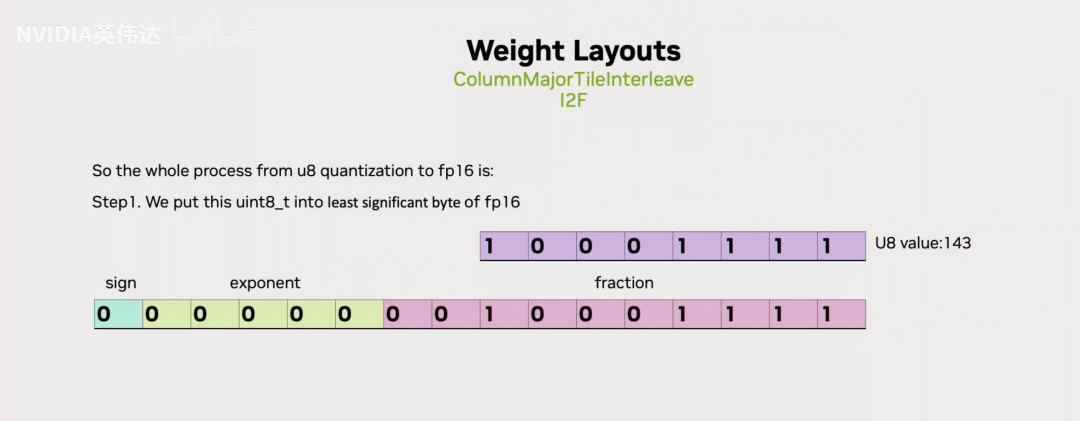
总结一下就是直接把UINT8的数值放在FP16的尾数位,

然后再把FP16的基码位设置成25,这个25对应的十六进制表示就是0x64,

随后再把最终的这个值减去FP16形式的1024,就完成了从UINT8到FP16的转换。

如果是Int8的话,应该怎么做呢?可以注意到UINT8和INT8只是数值范围的区别,那么我们需要把INT8的数据加上128,就能把它转换成UINT8的形式。这样转换出来的FP16的结果,只需要在减去1024的时候多减去128,就恢复到了对应的原始INT8的数值。
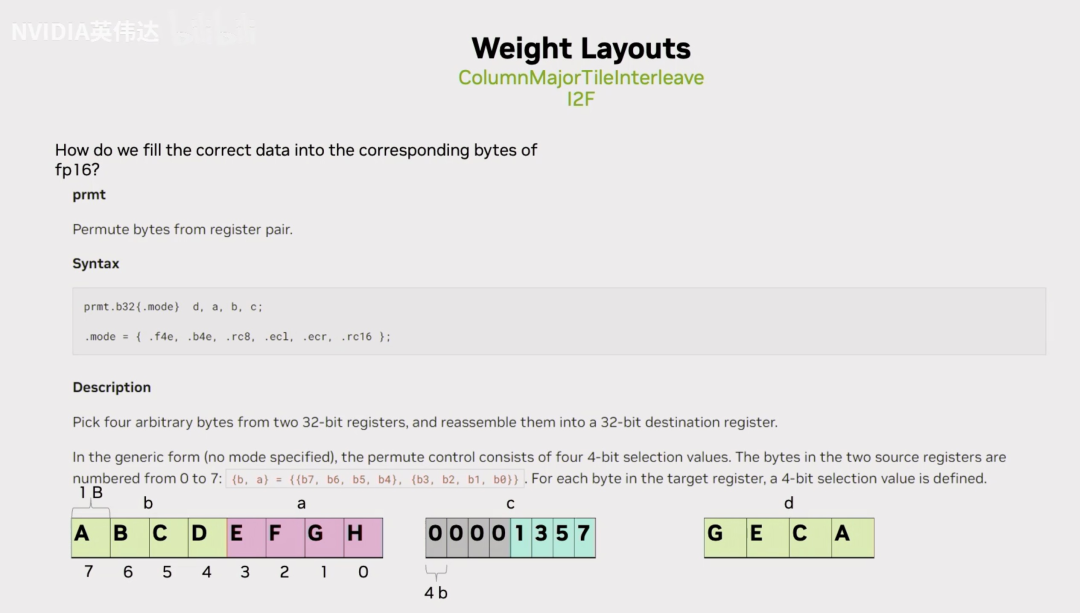
那么我们怎么实际的去用指令完成上面描述的这个操作呢?可以注意到有一种叫作prmt的PTX指令,这个指令做的事情就是从2个32bit的寄存器A,B中抽出4个8bit组成最终的d。而这4个8bit怎么抽取,就是每个8bit对应到c寄存器里面的低4bit,就是说c寄存器的低4bit每个bit都是一个索引,假设A,B两个32位寄存器里面存放的是上方左图这样的数据形式,即ABCDEFGH。那么在c寄存器中,索引的4个数字分别是1,3,5,7,那么最终这个D寄存器里面的4个8bit数据就是GECA。通过这种指令就可以实现从32bit寄存器里面抽取对应想要的一个字节出来的效果。
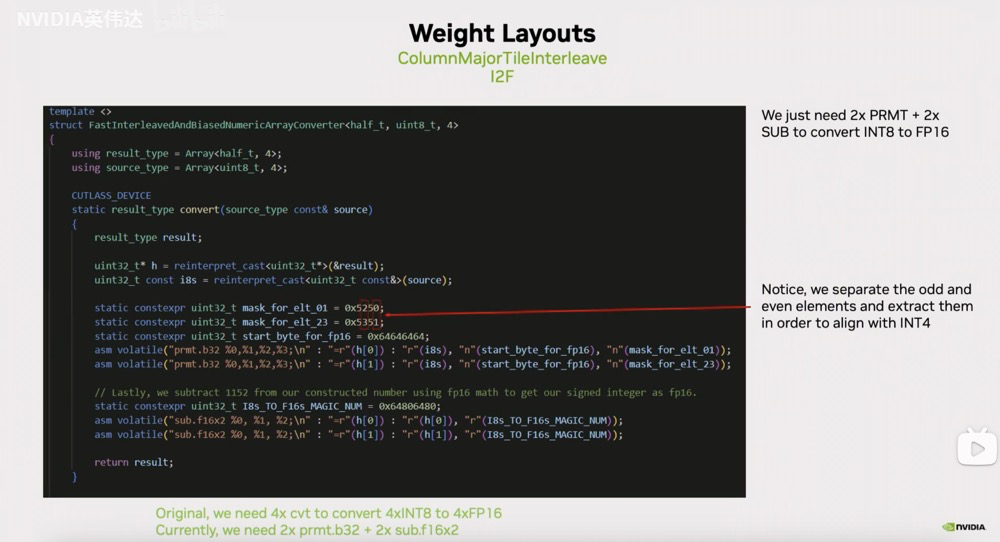
对应到TRT-LLM的转换代码就是这样的形式,我们可以注意到它用permute指令从输入的UINT8数据和magic number组成的这两个32位寄存器中去抽取4个8bit,抽取的索引放在这个mask_for_elt_01/23中。这里的两个掩码值 mask_for_elt_01 = 0x5250 和 mask_for_elt_23 = 0x5351 是用于CUDA的PRMT(Permute)指令的控制参数,它们决定了如何重排字节。
——————–分割线———————
这里我感觉比较难理解,所以下面详细拆解一下:
PRMT指令基础
首先,PRMT指令的格式是:
prmt.b32 d, a, b, c;
其中,d 是目标寄存器;a 和 b 是源寄存器;c 是控制码(即我们讨论的掩码)。然后PRMT指令将 a 和 b 的字节重新排列,根据控制码 c 中的每个字节决定输出的每个字节。
掩码的二进制表示
将掩码转换为二进制 (我用计算器算的):

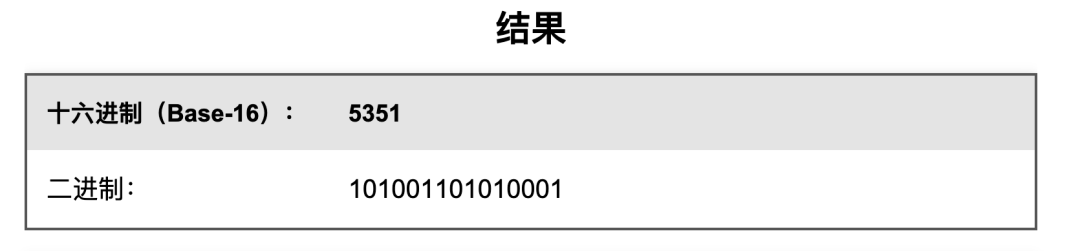
掩码的工作原理
在PRMT指令中,控制码 c 的每个字节控制输出的一个字节。每个控制字节的格式为:
[7:6] 选择源(00=a的低字, 01=a的高字, 10=b的低字, 11=b的高字)
[5:3] 保留或用于其他功能
[2:0] 选择字节索引(0-3)
mask_for_elt_01 (0x5250) 分析
拆分为4个字节:0x52, 0x50
-
第1个字节 0x52 = 0101 0010 -
01: 选择a的高字(即源数据的高16位) -
010: 选择索引2的字节 -
第2个字节 0x50 = 0101 0000 -
01: 选择a的高字 -
000: 选择索引0的字节 这个掩码用于提取源数据中的第0和第2个字节(即偶数位置的字节),并将它们放入结果的低16位。
mask_for_elt_23 (0x5351) 分析
拆分为4个字节:0x53, 0x51
-
第1个字节 0x53 = 0101 0011 -
01: 选择a的高字 -
011: 选择索引3的字节 -
第2个字节 0x51 = 0101 0001 -
01: 选择a的高字 -
001: 选择索引1的字节 这个掩码用于提取源数据中的第1和第3个字节(即奇数位置的字节),并将它们放入结果的低16位。
对应到代码
asm volatile("prmt.b32 %0,%1,%2,%3;\n" : "=r"(h[0]) : "r"(i8s), "r"(start_byte_for_fp16), "r"(mask_for_elt_01));
asm volatile("prmt.b32 %0,%1,%2,%3;\n" : "=r"(h[1]) : "r"(i8s), "r"(start_byte_for_fp16), "r"(mask_for_elt_23));
-
第一条指令使用 mask_for_elt_01提取源数据i8s中的偶数位置字节(0和2),并与start_byte_for_fp16(0x64006400)结合 -
第二条指令使用 mask_for_elt_23提取源数据i8s中的奇数位置字节(1和3),并与start_byte_for_fp16结合
static constexpr uint32_t I8s_TO_F16s_MAGIC_NUM = 0x64806480;
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(h[0]) : "r"(h[0]), "r"(I8s_TO_F16s_MAGIC_NUM));
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(h[1]) : "r"(h[1]), "r"(I8s_TO_F16s_MAGIC_NUM));
之后再像我们刚才描述的那样,在它的基础上减掉(1024+128)就得到了真实的这4个INT8对应的FP16的值。注意这里的 (1024+128)是dtype=float16下的1152对应的二进制。
—————————-分割线—————————–
我们可能会注意到,这里为什么要分别抽取01和23,而不是抽取0123呢?这主要是为了和之后的INT4的实现保持一致,在INT4的实现里不得不按照02,13的方式去抽取。

前面介绍了INT8到FP16的转换,如果是INT4应该怎么转呢?permute指令只能以8Bit为单位进行数据的操作,但是在4Bit的转换中,我们知道4Bit就是一个8Bit里面高4Bit存一个数据,低4Bit存另外一个数据。那么,我们就需要一种形式能把实际的8Bit里面的高低4个Bit给抽取出来。
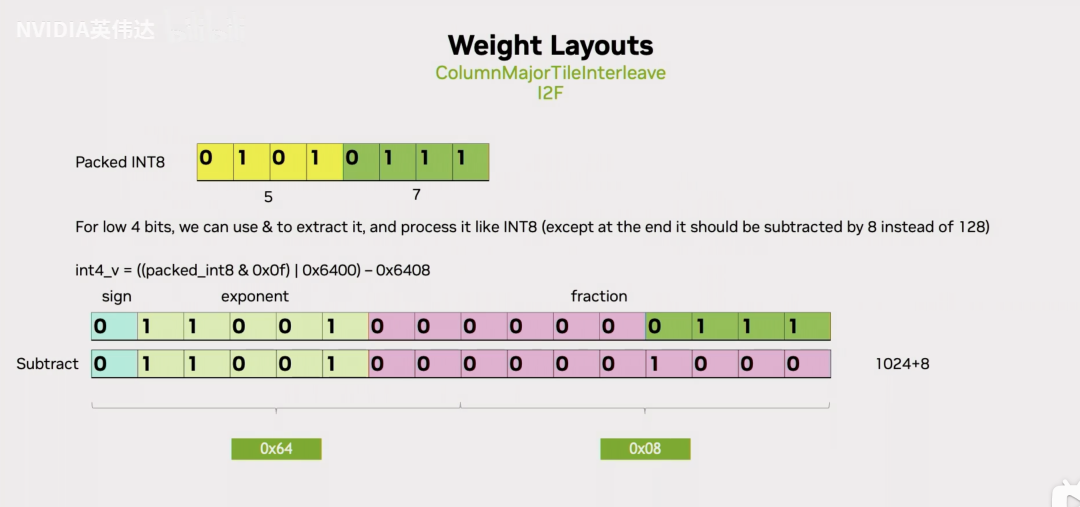
抽取出来之后我们应该怎么做呢?先看低4个bit,假设我们以位运算的方式把8Bit中的低4个Bit给抽取出来放到一个FP16的尾数里面去,然后前面也在基码位上赋值和Int8相同的25,也就是16进制的64。我们再把这个得到的值减去(1024+8),就得到了最终这个低4Bit对应的FP16的值。

那如果是高4个Bit应该怎么做呢?我们注意到低4个Bit是直接放到最低的4个Bit位,高4个Bit同样用位运算抽取出来之后这高4个Bit是存在于一个Int8的高4Bit里面,那放到尾数位的话那么它就需要去进行一个额外的除以16的操作,相当于右移了4位,最后就移到了黄色的位置。移动到这里之后,就可以进行和刚才一样的那些操作了,减去对应的值就得到了实际对应的FP16的值。这里减去的值是1024/16=64,因为移位的原因还要减掉8。

注意到在提取Int4数据的时候是用这张Slides的形式去提取的,而刚好有一种叫lop3的PTX指令可以完成这件事情。lop3这个PTX指令的大概描述就是他会在输入a, b, c三个寄存器作为输入,然后有一个Lut值,这个Lut值是怎么确定的呢?假设a,b,c分别对应了0xF0,0xCC,0xAA,我们把这三个值进行我们想要的操作得到的值作为Lut值,把这个Lut值放进去之后指令就会自动对a, b, c进行相应的操作,把结果写到d。所以,我们就可以利用这个指令把Lut值给它,它就可以帮我们高效完成Int4数据的提取了。最后,我们就把Int4转成FP16的过程转换成了一条lop3指令加上一条fma(或者sub)指令。
结合我们的AWQ的转换代码,LOP3的应用是:
asm volatile("lop3.b32 %0, %1, %2, %3, %4;\n"
: "=r"(h[0])
: "r"(i4s), "n"(BOTTOM_MASK), "n"(I4s_TO_F16s_MAGIC_NUM), "n"(immLut));
这里LOP3指令实现了类似 (i4s & BOTTOM_MASK) | I4s_TO_F16s_MAGIC_NUM 的操作,但只用一条指令就完成了,大大提高了效率。
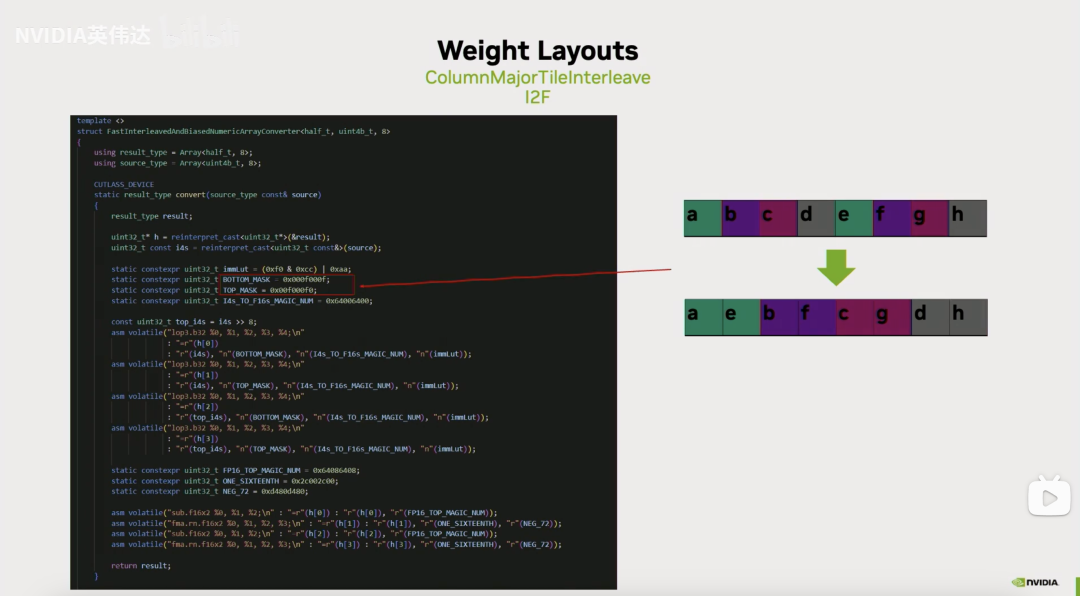
这张Slides展示了Int4到FP16的具体代码实现,我们注意到它提取的时候会用到0x0f或者0xf0来提取Int4,这样的话假如我们有连续的Int4的话,那被提取出来的分别是第0个Int4和第4个Int4以及第1个Int4和第5个Int4。所以它的奇偶被分别提取了出来。实际上我们是用8个连续的Int4来进行类型转换,因此它每次先把第0个Int4和第4个Int4提取出来,放到两个连续的FP16里面去,然后再去把第1和第5个Int4提取出来,放到两个连续的FP16里面去,以此类推。我们之前在做Int8的时候也分奇偶提取就和这里不得不做的这个数据提取动作保持一致。
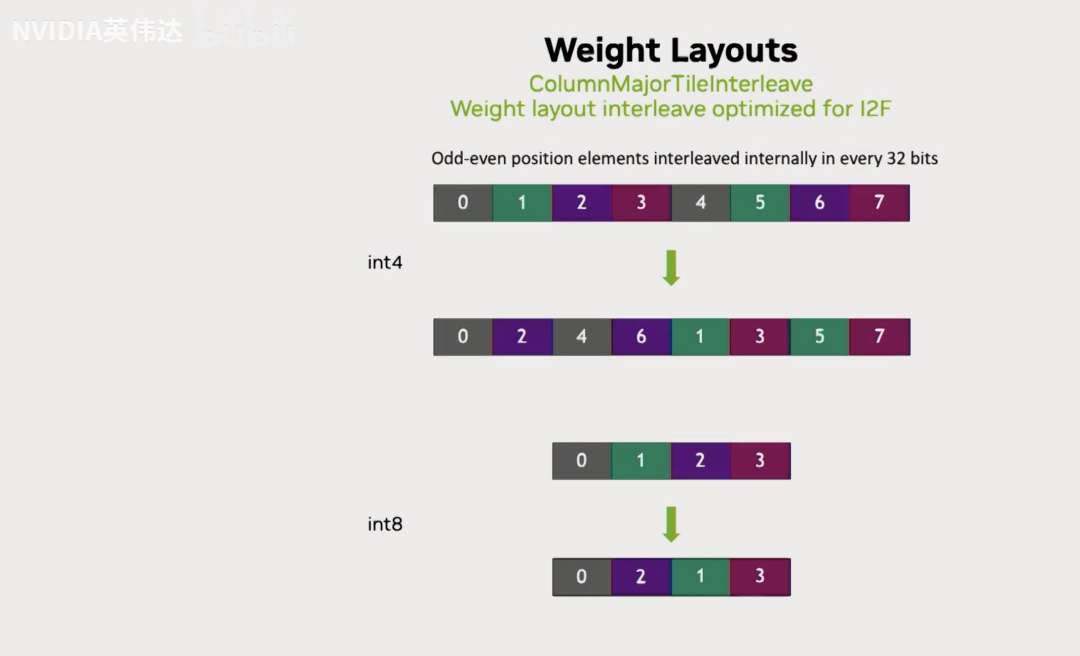
为了实际计算的时候去逆转这个元素排布的变化,我们需要在计算之前把Layout进行相应的调整。就是说以Int4位例的话就分别把它的奇偶位元素分别提取出来,这样在我们真正做计算把它从INT4转成FP16的时候,就会通过上一页Slides介绍的操作完成对这个Layout的逆运算,还原回了真实的连续排布的layout。
这就是描述的最后一种快速的Int4/Int8转FP16的优化的layout变化。通过这种优化就把前面提到的一个convert指令转换成了一系列lop3或者prmt指令。虽然指令数没有变化,但是指令的latency会更低。
dequantize_s4_to_fp16x2 kernel 解析
实际上上面的原理解析的代码就是这个dequantize_s4_to_fp16x2 kernel,根据上面的原理解析添加了几个注释,现在细节应该都比较清楚了。
__device__ uint4 dequantize_s4_to_fp16x2(uint32_t const& source) {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 750
uint4 result;
uint32_t* h = reinterpret_cast<uint32_t*>(&result);
uint32_tconst i4s = reinterpret_cast<uint32_tconst&>(source);
// First, we extract the i4s and construct an intermediate fp16 number.
staticconstexpruint32_t immLut = (0xf0 & 0xcc) | 0xaa;
staticconstexpruint32_t BOTTOM_MASK = 0x000f000f;
staticconstexpruint32_t TOP_MASK = 0x00f000f0;
staticconstexpruint32_t I4s_TO_F16s_MAGIC_NUM = 0x64006400;
// 注释说明了这种实现的优势:
// 1. 整个序列只需要1条移位指令
// 2. 利用寄存器打包格式和无符号整数表示
// 3. 利用sub和fma指令具有相同的吞吐量来优化转换
// 将i4s右移8位,用于处理第4-7个元素
// 提前发出以隐藏RAW依赖关系
constuint32_t top_i4s = i4s >> 8;
// 提取并转换第0和第1个元素(低字节的低4位)
// 使用LOP3指令实现(i4s & BOTTOM_MASK) | I4s_TO_F16s_MAGIC_NUM
asm volatile("lop3.b32 %0, %1, %2, %3, %4;\n"
: "=r"(h[0])
: "r"(i4s), "n"(BOTTOM_MASK), "n"(I4s_TO_F16s_MAGIC_NUM), "n"(immLut));
// 提取并转换第2和第3个元素(低字节的高4位)
// 使用LOP3指令实现(i4s & TOP_MASK) | I4s_TO_F16s_MAGIC_NUM
asm volatile("lop3.b32 %0, %1, %2, %3, %4;\n"
: "=r"(h[1])
: "r"(i4s), "n"(TOP_MASK), "n"(I4s_TO_F16s_MAGIC_NUM), "n"(immLut));
// 提取并转换第4和第5个元素(高字节的低4位)
asm volatile("lop3.b32 %0, %1, %2, %3, %4;\n"
: "=r"(h[2])
: "r"(top_i4s), "n"(BOTTOM_MASK), "n"(I4s_TO_F16s_MAGIC_NUM), "n"(immLut));
// 提取并转换第6和第7个元素(高字节的高4位)
asm volatile("lop3.b32 %0, %1, %2, %3, %4;\n"
: "=r"(h[3])
: "r"(top_i4s), "n"(TOP_MASK), "n"(I4s_TO_F16s_MAGIC_NUM), "n"(immLut));
// 定义用于最终转换的魔数常量
// 表示fp16格式的{1024, 1024}
staticconstexpruint32_t FP16_TOP_MAGIC_NUM = 0x64006400;
// 表示fp16格式的{1 / 16, 1 / 16},用于缩放高4位的值
staticconstexpruint32_t ONE_SIXTEENTH = 0x2c002c00;
// 表示fp16格式的{-64, -64},用于偏移校正
staticconstexpruint32_t NEG_64 = 0xd400d400;
// 最终转换步骤:将中间fp16值转换为实际的int4值
// 处理第0和第1个元素:直接减去1024
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(h[0]) : "r"(h[0]), "r"(FP16_TOP_MAGIC_NUM));
// 处理第2和第3个元素:乘以1/16再减去64
// 相当于(h[1] * 1/16 - 64),因为高4位需要右移4位
asm volatile("fma.rn.f16x2 %0, %1, %2, %3;\n" : "=r"(h[1]) : "r"(h[1]), "r"(ONE_SIXTEENTH), "r"(NEG_64));
// 处理第4和第5个元素:直接减去1024
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(h[2]) : "r"(h[2]), "r"(FP16_TOP_MAGIC_NUM));
// 处理第6和第7个元素:乘以1/16再减去64
asm volatile("fma.rn.f16x2 %0, %1, %2, %3;\n" : "=r"(h[3]) : "r"(h[3]), "r"(ONE_SIXTEENTH), "r"(NEG_64));
return result; // 返回包含8个fp16值的uint4结构
#else
assert(false); // 如果CUDA架构低于7.5,则断言失败
return {};
#endif
}
0x4. 总结
本文详细解析了vLLM/SGLang中AWQ int4反量化kernel的实现原理和优化技巧。该kernel巧妙利用IEEE 754浮点数表示特性,通过LOP3和PRMT等PTX指令高效地将int4权重转换为fp16格式。通过直接操作尾数位和基码位,避免了传统转换方法中的多次移位和类型转换,实现了高性能的反量化操作。整个过程只需少量高效指令,充分利用了CUDA硬件特性,是一种精巧的底层优化技术。因为很底层,所以代码实现虽然简短但引入了大量的Magic Number和先验知识,我这里结合nvidia的一个PPT和自己的理解把它搞清楚了,希望可以帮助到有相同困惑的读者。
(文:GiantPandaCV)