
移动操作赋予了机器人跨越大空间执行复杂操作任务的能力。随着智能机器人系统的日益普及,家庭服务、制造和物流等领域对机器人移动操作能力提出了迫切需求,但要想机器人在非结构化环境中执行如协助人们的日常生活等多样化任务,仍面临重大挑战。
要想实现移动操作,机器人就必须能够对移动基座和机械臂进行全身控制。目前现有的移动操作框架可分为模块化和端到端两类。其中,模块化移动操作框架通常是对导航和固定基座模块进行分别训练,不仅需进行大量训练,同时也会导致误差累积。端到端方法则主要通过模仿学习直接预测基于视觉观察的移动操作动作,该方法虽实现了导航和操作动作的联合优化,却依赖专家轨迹学习,其训练成本相对较高,这在一定程度上限制了数据集规模和泛化能力。
相比之下,在多样化操作任务重展现出强大泛化能力的视觉-语言-动作 (VLA) 模型,能够直接基于RGB视觉观察输出末端执行器的7自由度动作,且无需依赖预测的对象类别和姿态,有望为机器人移动操作领域带来新改变,但VLA模型同时也存在专注于固定基座任务,无法生成移动基座和机械臂之间的协同动作的问题。
▍提出策略迁移框架MoManipVLA,实现多样化任务与环境高度泛化
针对VLA模型在移动操控领域的应用挑战,来自北京邮电大学、南洋理工大学和清华大学的研究人员携手合作进行了深入研究,并提出了一种高效策略迁移框架 MoManipVLA。该框架通过将预先训练VLA模型从固定基座操作环境迁移到移动操作环境中,实现了移动操作策略在不同任务和环境中的高度泛化。
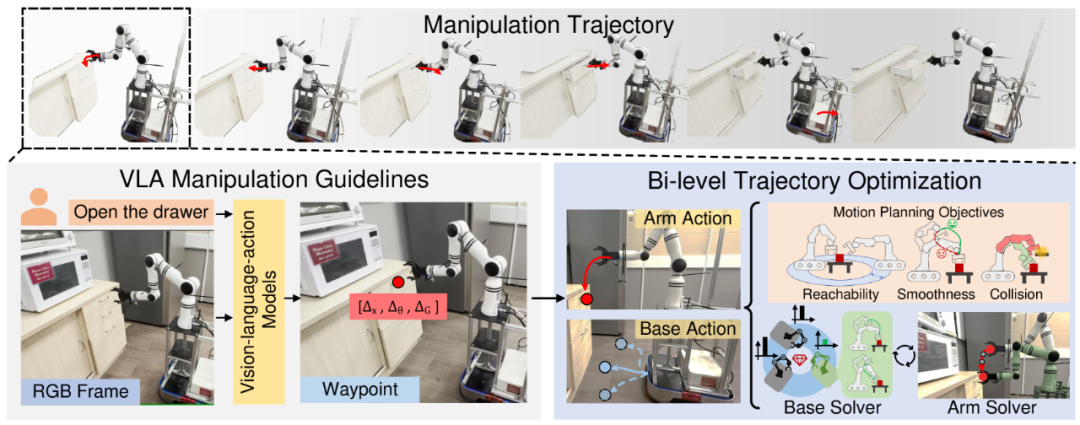
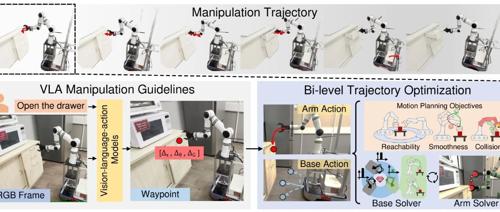
具体来说,研究团队利用预先训练的 VLA 模型生成具有高泛化能力的末端执行器的航点,并为移动基座和机械臂设计了旨在最大限度提高轨迹物理可行性的运动规划目标。此外,研究团队还提出了一个高效的双层目标优化框架用于轨迹生成,实现了以零样本方式调整机器人基座的位置,并确保从固定基座 VLA 模型预测的航点在移动操作中切实可行。
通过在OVMM 和现实世界中进行大量实验,研究团队验证了MoManipVLA框架的有效性。实验结果显示,MoManipVLA的成功率较当前最先进的移动操纵技术高出4.2%。同时,得益于预训练VLA模型的强大泛化能力,该框架在现实世界部署时的训练成本仅需50个样本。
该研究成果的相关论文“MoManipVLA: Transferring Vision-language-action Models for General Mobile Manipulation”目前已被IEEE国际计算机视觉与模式识别会议(CVPR2025)接受。论文作者包括北京邮电大学智能工程与自动化学院研究生吴振宇,南洋理工大学周宇恒、王子伟,清华大学自动化系博士生徐修伟等人。通讯作者为北京邮电大学智能工程与自动化学院闫海滨教授。
那么,该成果具体是如何实现的呢?接下来,和机器人大讲堂一起来深入了解!
▍现实部署仅需50个样本,MoManipVLA具体如何实现?
MoManipVLA框架的核心在于将预训练的固定基座VLA模型策略有效迁移到移动操作任务中。其总体框架设计巧妙,旨在联合生成移动基座和机械臂的轨迹,以实现高泛化能力。
在工作流程中,MoManipVLA首先利用预训练的VLA模型,根据环境观察和人类指令,预测出最优的末端执行器路径点。随后,系统联合规划基座和机械臂的轨迹,以确保末端执行器能够准确、高效地到达这些路径点。

为了实现这一目标,研究团队首先设计了详细的运动规划目标,这些目标充分考虑了轨迹的安全性、平滑性和可达性,以最大化轨迹的物理可行性。在轨迹规划过程中,路径点首先从基座坐标系转换到世界坐标系,然后系统通过最小化一个综合成本函数来优化整个轨迹。该成本函数涵盖了可达性成本、平滑性成本和碰撞成本,确保了轨迹在物理上的可行性和安全性。
由于移动基座和机械臂的位姿搜索空间庞大且复杂,直接搜索最优解极具挑战性。为此,研究团队提出了一种双层轨迹优化框架。在上层优化中,系统搜索基座的最优位姿,为机械臂位姿的搜索提供基础;在下层优化中,则在给定的搜索空间内寻找最优的机械臂位姿,以遵循预训练的VLA模型的指导完成任务。
为了应对搜索空间庞大且可能非凸的问题,研究采用了双退火搜索算法进行目标优化,并利用基于梯度的局部优化器SLSQP来进一步细化解决方案。这种方法不仅提高了轨迹生成的效率,还有效避免了陷入局部最优的风险。
通过一系列创新方法,MoManipVLA框架几乎无需额外的训练成本,即可成功将预训练的固定基座VLA模型策略迁移到移动操作任务中。
▍OVMM与现实世界双重测试,验证MoManipVLA框架有效性
为了验证MoManipVLA框架的有效性,研究团队在OVMM基准测试集和现实世界中进行了全面的实验。
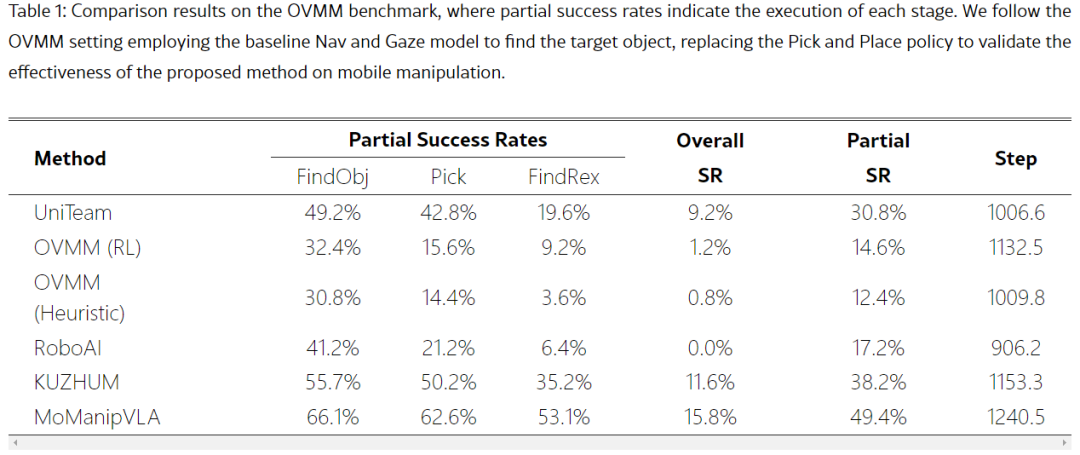
在OVMM基准测试集中,研究团队将MoManipVLA框架所提策略与当前最先进的移动操控策略进行了全面对比。实验结果显示,MoManipVLA在总体成功率上实现了4.2%的增益,同时在部分成功率上也取得了11.2%的提升。特别是在Pick成功率方面,MoManipVLA方法比最先进方法高出12.4%。这一结果有效证明了MoManipVLA框架能够将预训练的VLA模型策略成功且高效地转移到移动操作任务中。
为了深入探究MoManipVLA框架中运动规划目标各成本项的作用,研究团队还进行了消融实验。他们分别删除了可达性、平滑度和碰撞项,并仔细评估了这些变动对成功率和效率的影响。实验结果表明,每个成本项都对整体成功率的提高有着明显的贡献。其中,可达性对成功率的提升最为显著,这主要是因为移动操作任务需要在较大的区域内与目标进行交互,而基座的位置往往限制了代理的到达能力。这一发现进一步验证了移动操控任务中,移动基座和手臂的协同控制以确保末端执行器的可达性是性能的关键瓶颈,也是将预训练的VLA模型有效转移到移动操控任务中的关键所在。
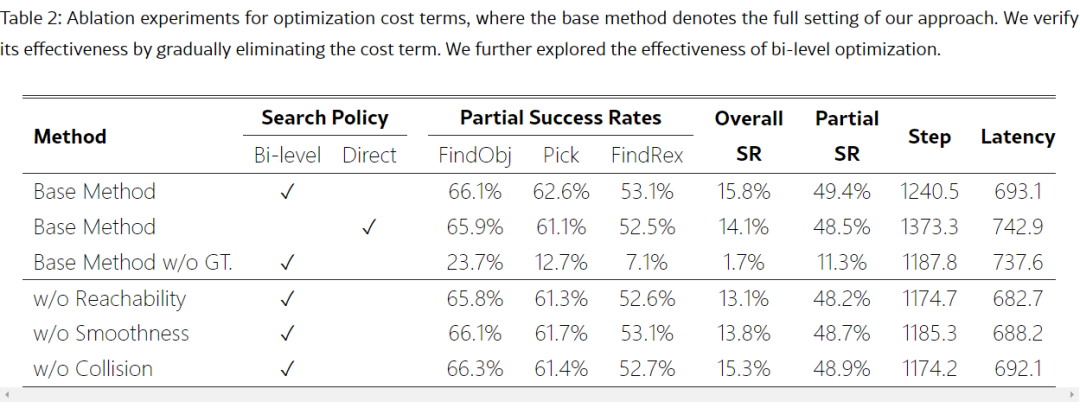
在算法优化方面,研究团队对双层目标优化方法和普通双退火搜索算法进行了对比实验。尽管普通双退火搜索算法在成功率上表现出色,但双层目标优化方法在降低延迟方面显著优于前者。这一结果表明,双层目标优化方法在避免搜索缺陷、提高算法效率方面具有明显优势。
为了公平且全面地评估MoManipVLA框架的移动操作策略,研究团队还利用真实对象蒙版和Detic等视觉基础模型生成的对象蒙版进行了实验。但由于家庭环境中的物体通常摆放杂乱无章,会导致视觉感知质量大幅下降,在使用视觉输入时,总体成功率远低于使用真实蒙版的方法。
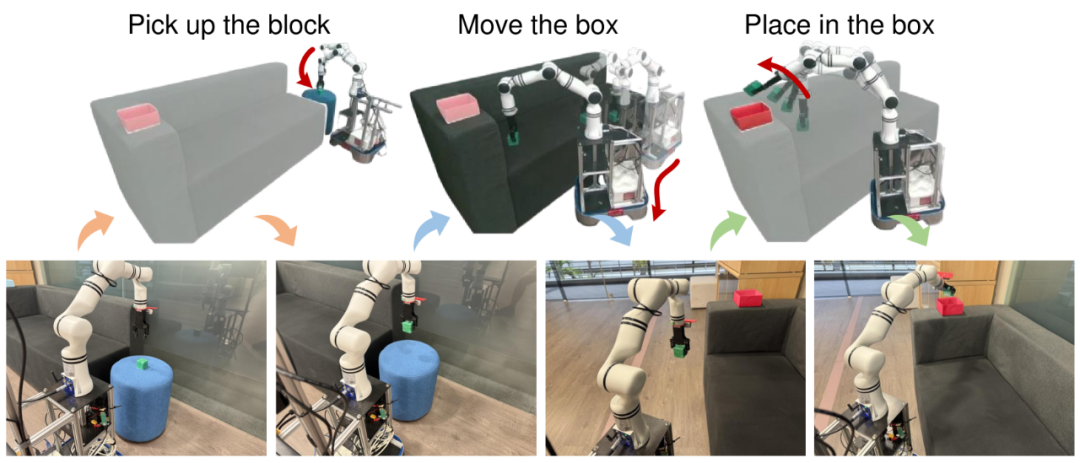
在真实世界实验中,研究团队采用了hexman echo plus base和RM65机械臂组件构成的离线移动平台,并利用nvblox重建场景ESDF(欧几里得符号距离场)和Grounding SAM(语义分割和匹配)获取机械臂和目标物体的掩码。实验过程中,他们遵循ORB-SLAM(同时定位与地图构建)设置,并使用英特尔Realsense T265跟踪摄像头获取实时摄像头姿势和基准姿势。实验结果显示,MoManipVLA框架仅需50个样本即可完成微调,并在移动操作任务上实现了40%的成功率。在更具挑战性的抽屉打开任务中,尽管需要满足物理约束并避免与铰链物体运动发生碰撞难度更高,其成功率也达到了10%。
参考文章:
https://arxiv.org/html/2503.13446v1
(文:机器人大讲堂)