


DeepSeek R1 是一款高性能的开源大模型,具备强大的理解和推理能力,适用于多种 AI 任务。
Ollama 则是一款专门用于本地部署和管理大模型的工具,它简化了模型的调用和运行,使得开发者可以在本地环境中高效地使用 LLM。二者结合,使得 RAG 系统不仅具备强大的生成能力,还能灵活适配不同的应用场景。
搭建 RAG 系统的第一步是环境准备,需要安装 DeepSeek R1 和 Ollama。Ollama 允许在本地运行大模型,避免了云端 API 访问的延迟和费用问题,同时确保数据的隐私性。
确保您已安装所需的 Python 包。您可以使用以下方式安装它们:
pip install langchain-core langchain-community langchain-ollama langchain-huggingface faiss-cpu psutil
安装完成后,需要准备一个知识库,可以是结构化的数据库,也可以是非结构化的文本数据,如网页、PDF 文档或公司内部文档。
为了优化检索效果,可以使用向量数据库,如 FAISS、Chroma 或 Weaviate,将文本数据转换为向量表示,以便 AI 在查询时能够快速检索到相关信息。

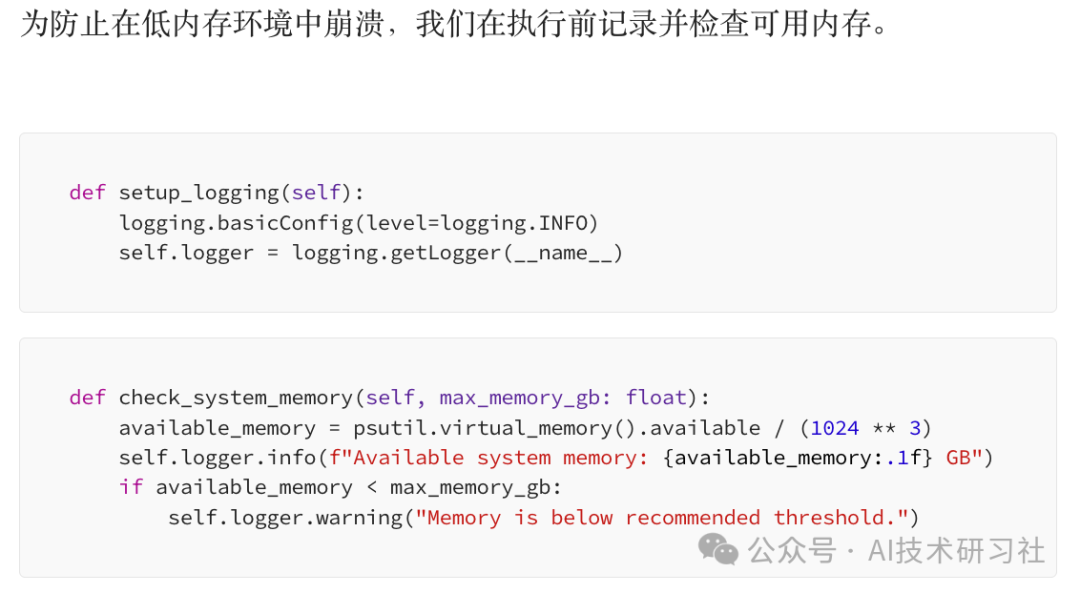
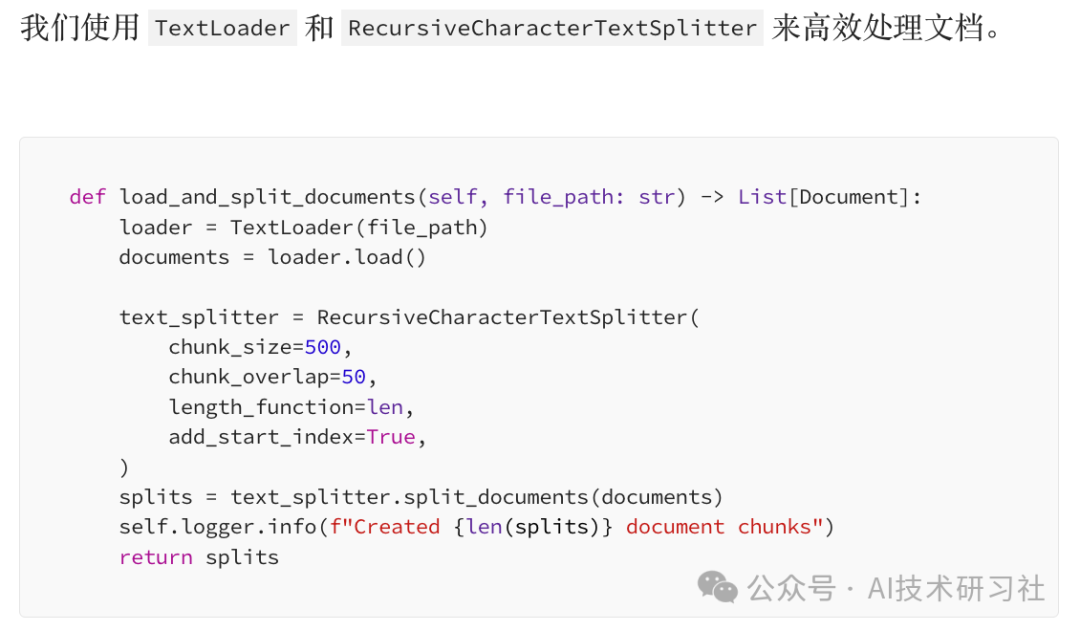
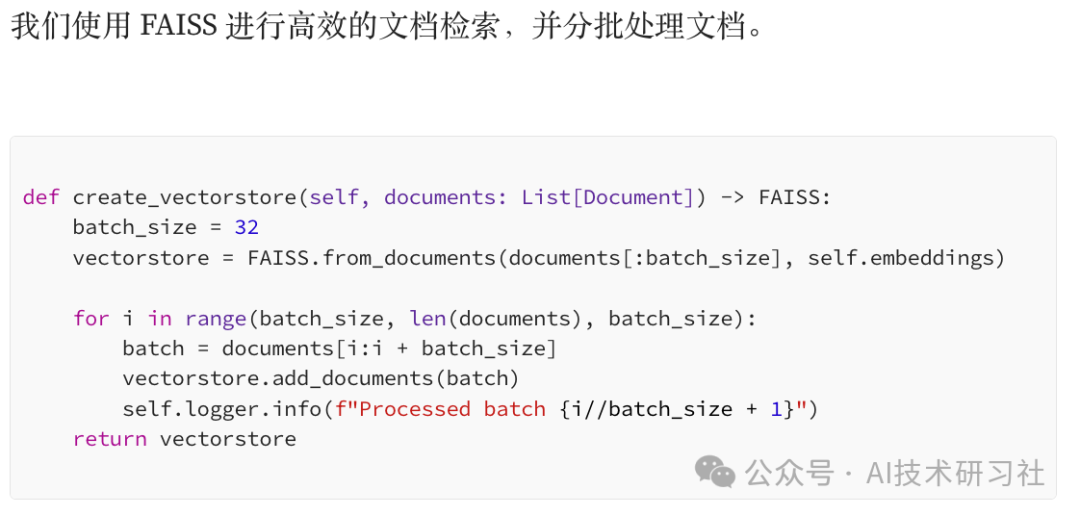

RAG 之所以成为 AI 领域的颠覆性变革,是因为它结合了信息检索与生成式 AI,使 AI 能够在生成答案之前,先从外部知识库中获取最新、最相关的信息。传统的 AI 生成模型仅依赖于训练数据,在处理专业领域问题或实时信息时,往往存在局限性。
而 RAG 通过引入动态检索机制,使 AI 能够基于实时获取的信息进行生成,从而提高回答的准确性和可靠性。无论是智能客服、法律咨询、医学问答,还是技术文档解析,RAG 都能提供更符合用户需求的答案。
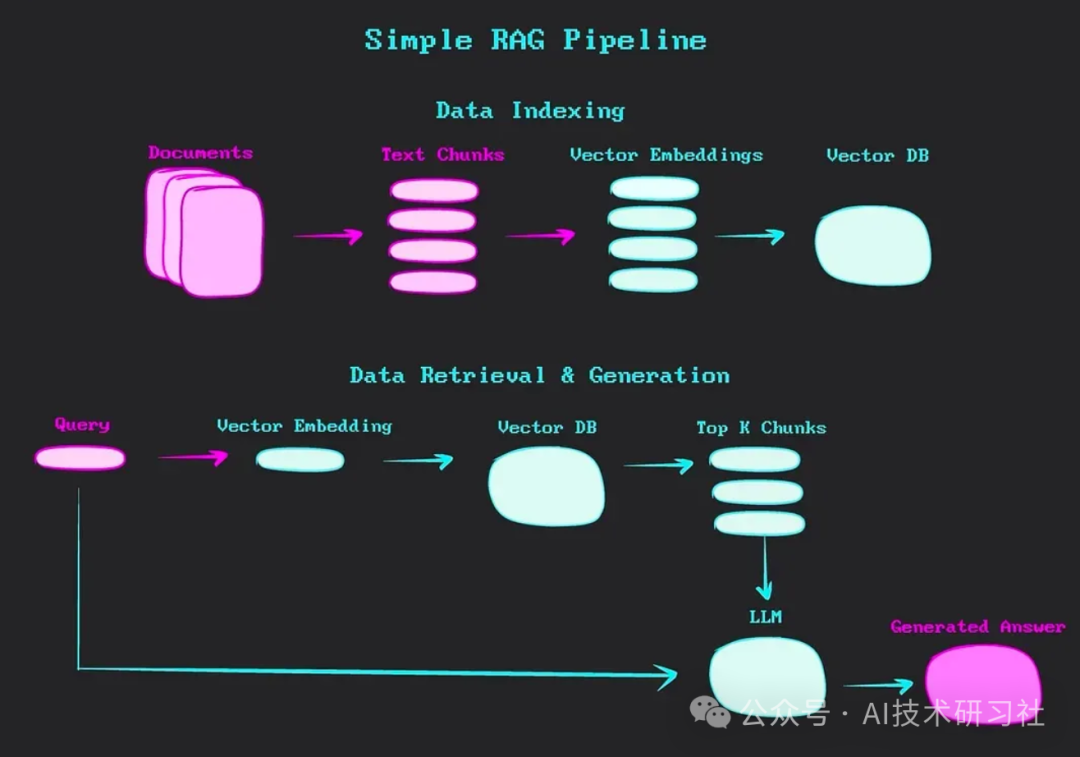
在 RAG 系统的核心流程中,用户输入问题后,系统首先会利用检索模块从知识库中找到相关信息,然后将这些信息与用户的输入一起传递给 DeepSeek R1 进行生成。
为了提高检索的准确性,可以使用关键词搜索、语义匹配或向量检索等技术。向量检索结合了 NLP(自然语言处理)和嵌入模型,使得系统能够理解语义上的相似性,而不仅仅是基于关键词进行匹配。这种方式能够有效提升 RAG 系统在处理复杂问题时的表现。

为了优化 RAG 系统的响应质量,需要对检索和生成过程进行调整。首先,知识库的数据质量至关重要,确保数据的准确性和覆盖面可以提高 AI 生成答案的可靠性。
其次,可以通过 Prompt Engineering(提示词优化)来引导 DeepSeek R1 生成更符合预期的回答。例如,可以在输入中加入更具体的背景信息,或者提供示例回答,让 AI 更好地理解用户的需求。
此外,可以使用 Ranker(排序模型)对检索到的候选信息进行重新排序,确保最相关的信息被优先用于生成答案。
除了技术优化,RAG 系统的实际应用场景也值得探讨。在智能客服系统中,RAG 能够帮助 AI 快速查找并引用企业内部知识库中的信息,提供精准的解答;在法律和医学领域,RAG 可以检索专业文献,确保 AI 生成的内容具有权威性;在开发者文档查询中,RAG 可以帮助工程师快速查找技术资料,提升开发效率。这些应用场景都凸显了 RAG 在增强 AI 交互能力方面的巨大潜力。
未来,随着 RAG 技术的不断发展,DeepSeek R1 和 Ollama 可能会与更多 AI 工具结合,进一步优化检索和生成的协作方式。例如,结合更先进的检索算法,提升系统对多模态数据的处理能力,使 RAG 不仅能处理文本,还能结合图像、音频等信息进行综合分析。
此外,个性化 RAG 也是未来的发展方向之一,让 AI 能够根据用户的使用习惯和历史查询记录,提供更加精准和个性化的回答。
总的来说,DeepSeek R1 和 Ollama 的结合为 RAG 系统的构建提供了强大支持,让开发者可以更高效地实现智能 AI 解决方案。通过合理的架构设计、优化的检索策略和高质量的数据管理,RAG 系统能够在各种应用场景中发挥出色的作用。
无论是企业级 AI 方案,还是个人开发者的创新应用,RAG 都将成为推动 AI 交互智能化的重要技术。
参考:https://medium.com/ai-agent-insider/developing-rag-systems-with-deepseek-r1-ollama-66a520bf0b88
(文:AI技术研习社)