

DeepSeek 在 2025 年 3 月 24 日发布了一次细微而深远的更新:V3‑0324。此次更新对基础模型进行了优化,同时保持了经济高效的训练与推理成本。它基于强大的混合专家(Mixture‑of‑Experts, MoE)设计和先进的解码策略,使其在性能上与 GPT‑4o、Claude 3.5 Sonnet 等封闭源系统竞争中处于有利位置。

技术架构
模型核心与设计
-
混合专家(MoE)架构:
DeepSeek V3‑0324 构建于 MoE 架构之上,总参数量为 6710 亿,但每个 token 只激活 370 亿参数。模型包含 61 层 Transformer,每层动态地将 token 路由到 256 个专家(其中始终激活 1 个“共享”专家)。这种稀疏激活大幅提高了计算效率,同时不牺牲性能。 -
多头潜在注意力(Multi‑head Latent Attention, MLA):
模型集成了 MLA 技术,以增强对长序列文本中长距离依赖关系的理解,确保在长达 128K token 的上下文中依然能保持关键信息。 -
多 token 预测(Multi‑Token Prediction, MTP):
创新的 MTP 目标使模型能够在一次推理步骤中预测多个 token,从而显著加快解码速度(据称吞吐量提高多达 3 倍)。
效率创新
-
FP8 混合精度训练:
这是首次在如此大规模的开源语言模型中采用 FP8 训练。该方法大幅降低内存使用并提升矩阵乘法吞吐量——通过定制的 GEMM 例程和细粒度量化策略(基于 1×128 瓦片的缩放)来减小量化误差。 -
无辅助损失的负载均衡:
与传统辅助损失方法(可能干扰 token 与专家之间的亲和性)不同,此次更新在门控机制中引入了偏置项,用于平衡负载而不影响优化目标。这种方法在专家数量增加时,仍能保持路由效率的提升。
下面是专家路由机制的简化伪代码示例:
def route_token(token_embedding, expert_weights, gating_bias):# 计算 token 与各专家之间的亲和度logits = token_embedding @ expert_weights.T + gating_bias# 选择前 K 个专家(例如,在 256 个专家中选择 2 个)topk_indices = logits.topk(k=2).indicesreturn topk_indices
这种高效的路由机制与选择性激活相结合,是模型在每个 token 上以有限计算量提供高性能的关键所在。
训练过程与数据
数据与预训练
-
数据集:
模型在一个多语言语料库上进行了预训练,该语料库包含 14.8 万亿高质量 token。数据集中特别强调数学和编程内容,这为模型在推理和编程任务上表现出色奠定了基础。 -
训练成本与效率:
DeepSeek V3‑0324 使用约 2788 千 GPU 小时在 Nvidia H800 芯片上完成训练,最终训练成本约为 560 万美元——这一数字与竞争对手相比极为经济
训练流程
-
预训练阶段:
模型采用 FP8 混合精度算术进行全量无监督预训练。关键优化包括计算与通信的重叠,以及采用细粒度(基于 1×128 切片)的量化策略,以平衡分辨率误差与截断误差。 -
监督微调(SFT):
预训练后,模型在大约 150 万条经过精心筛选的数据样本上进行了监督微调,覆盖了推理任务(数学、编程、逻辑问题解决)和非推理任务(创意写作、对话任务)。 -
强化学习蒸馏:
为进一步提升推理能力,DeepSeek 采用了强化学习技术,将专用 R1 模型的链式思考(Chain‑of‑Thought)蒸馏到 V3 基础模型中。该强化学习流程改善了输出质量——尤其在需要复杂推理的任务上,而无需大量迭代的人类标注。
下面是训练过程的高级概述:
# 高级训练循环for epoch in range(num_epochs):for batch in data_loader:# 使用 FP8 混合精度进行预训练outputs = model.forward(batch.input, precision='fp8')loss = compute_loss(outputs, batch.targets)optimizer.zero_grad()loss.backward()optimizer.step()# 使用人工验证的推理数据进行监督微调fine_tune(model, fine_tune_data)# 最后,应用强化学习进行推理蒸馏apply_rl_distillation(model, rl_data)
这一精心设计的训练流程确保 DeepSeek V3‑0324 在保持稳定性(无不可恢复的损失峰值)的同时,实现了最先进的性能。
性能评估与基准测试
关键指标
独立评估和早期用户基准测试表明,DeepSeek V3‑0324 在以下任务上表现卓越:
-
数学推理:
在 MMLU(5‑shot)测试中,准确率约为 87.1%,并且在 GSM8K 和 MATH 等基准测试中表现优异。 -
编程能力:
在 HumanEval Pass@1 测试中得分约为 65.2%,且有用户提供的实例证明其能够生成长达 700 行且语法正确的代码。 -
通用语言理解:
相较于开源模型如 LLaMA 3.1 和 Qwen 2.5,DeepSeek V3‑0324 在多项基准测试中表现更优,并且与封闭源模型如 GPT‑4o 和 Claude 3.5 Sonnet 的性能相当。
对比基准
下表简要总结了部分基准测试性能:
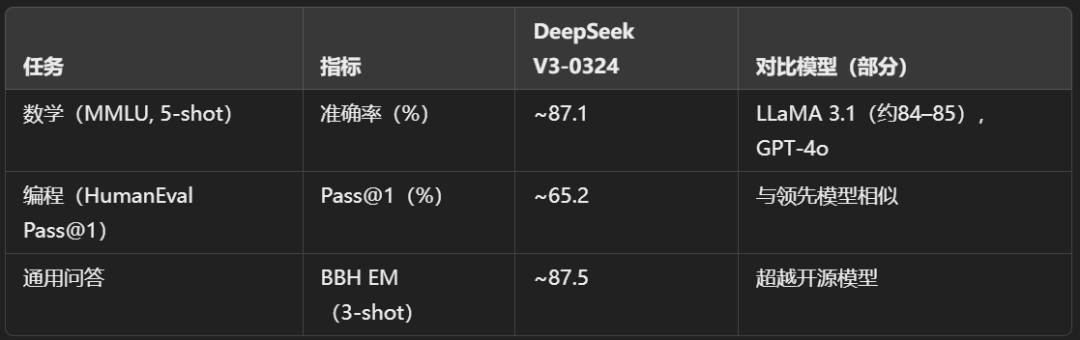
这些结果,加上模型在超长上下文(最高 128K token)处理能力,充分表明了其在复杂、高价值应用中的实用性。
应用场景与使用案例
DeepSeek V3‑0324 集高推理、编程和语言理解能力于一身,适用于广泛的应用场景:
-
企业聊天机器人与虚拟助理:
得益于其高效推理和对话上下文管理能力,该模型非常适合用于客户支持、技术协助和自动化问答系统。 -
代码生成与调试:
模型在代码生成方面的出色表现使其成为开发者在自动生成代码、调试及软件文档编写中的得力工具。 -
教育工具:
强大的数学推理能力可支持辅导、问题解决应用和互动教育平台。 -
内容创作:
模型生成连贯、上下文相关文本的能力适用于创意写作、数字营销及内容摘要等应用。 -
研发与学术研究:
作为一款 MIT 许可证下的开源模型,DeepSeek V3‑0324 为进一步探索自然语言处理、强化学习和高效模型扩展提供了优秀的研究平台。
DeepSeek 的部署可通过其官方网站、移动应用、Hugging Face 上的模型权重以及云服务平台(如 OpenRouter)进行。
挑战与未来方向
当前挑战
-
负载均衡与专家路由:
尽管采用了基于偏置的负载均衡机制提升了性能,但如何在面对多样化输入分布时在越来越多的专家之间最优地分配 token,仍然是一大挑战。 -
FP8 训练中的数值稳定性:
使用 FP8 混合精度训练虽然效率高,但需要严格控制量化误差。未来需持续改进动态范围量化和误差最小化策略。 -
上下文管理:
当上下文窗口扩展到 128K token 时,如何在极长文本中保持连贯性依然具有挑战性,这需要进一步研究内存管理与注意力机制的优化。 -
审查与数据隐私:
与早期版本类似,在某些地区的部署会受到监管审查——在确保高性能的同时平衡敏感话题处理与合规要求仍需持续努力。
未来发展方向
-
更强推理模型(R2 及后续版本):
基于 V3 的基础,DeepSeek 有望推出更为强大的推理模型(如 DeepSeek‑R2),整合更多强化学习与链式思考蒸馏的新进展。 -
多模态扩展:
未来工作可能探索将视觉、音频甚至交互式输入整合进模型,扩展其纯文本处理之外的应用领域。 -
先进量化技术:
进一步研究细粒度量化、改进的缩放因子以及动态在线量化,有望在保持或提升精度的同时进一步降低推理成本。 -
扩展高效性:
探索更大规模的 MoE 配置——在保持激活稀疏性的前提下增加专家数量,可能在不显著增加计算需求的情况下突破性能极限。 -
生态系统与定制化:
依托其开源许可证,积极培养社区以定制、扩展和针对特定应用场景优化模型,是未来战略中的重要方向。
总结
DeepSeek V3‑0324 展现了如何通过深思熟虑的架构创新——如稀疏激活的 MoE、先进的 FP8 训练以及高效的多 token 预测——在大幅降低成本的同时达到最先进的性能。尽管在专家路由和数值精度控制上仍存在挑战,但模型卓越的基准测试成绩和广泛的应用潜力标志着其在普及 AI 研究和实际应用方面迈出了重要一步。随着 DeepSeek 继续迭代,并有望推出下一代推理模型,其对全球 AI 生态系统以及商业应用的影响必将进一步扩大。
下载地址:
https://huggingface.co/deepseek-ai/DeepSeek-V3-0324
文章来源:PyTorch研习社

(文:PyTorch研习社)