

中午刷推时
看到个劲爆消息
差点没把我手机抖掉地上

ARC Prize公布了全新AGI测试基准!
当前行业TOP模型成绩不到5%!
要知道,在先前的ARC-AGI-1测试里
也是直到2024年底,才被OpenAI的o3系统
终于攻破了纯记忆范畴的壁垒
拿到87.5分
似乎就要轻松拿下了?
可事实上
这边ARC Prize丝毫不给AI面子
马上就提出了全新的ARC-AGI-2基准

我仔细看了下通报的战绩:
纯LLM大模型,表现如何?
0分,妥妥打回原形
专业AI推理系统表现更好?
R1和o3-mini不到4%成绩
就连号称适应性拉满的o1 pro和o3
也就个位数分数
不到5%

可相同的题目,换成人类呢?
ARC直接做了活体测试:
400名真人,轻松搞定全部题目
简直就是降维打击啊!
看到这里,我就纳闷了:
这考的啥啊?
AI怎么集体扑街了?
往下看了ARC-AGI-2的详细介绍
这才明白,这套测试真是瞄准了
当前AI模型的三大软肋狠狠出击:

第一个软肋:符号解释能力
现在的AI推理系统
看到符号时只会分析视觉模式
会检查对称性、镜像、变换
甚至能认出连接元素
但就是死活不理解符号本身的语义意义

第二个软肋:组合推理能力
当需要同时应用多条规则时
或者要应用相互影响的多条规则
AI推理系统就开始翻车了
反倒是任务只有一两条全局规则时
系统还能稳定发现并应用
第三个软肋:上下文规则应用
AI推理系统最怕的就是
根据不同上下文灵活应用规则的任务
系统总是盯着表面模式死磕
而不是理解底层的选择原则

怪不得现有AI 全军覆没
这不就是把AI 的短板全揪出来暴打了?
而且ARC-AGI-2 也不是什么
需要超人类技能的变态题目
它考的恰恰就是AI 最缺的关键能力:
高效获取新技能的能力
说人话就是:
人能举一反三,AI只会死记硬背
人类做题五分钟,AI 狂烧token 两小时
更关键的是,ARC 比赛还首次引入了
费用效率这个核心指标
不再是单纯比谁分数高了
而是看谁能用最少的成本达到目标
这怎么有点薅羊毛党内卷的味道?
ARC 官方也给出了超强挑战目标:
准确率85%,且每题成本不超过0.42美元
这水平,感觉就像是让AI 去参加个
高考奥数竞赛还得用最便宜的铅笔做题
为了鼓励全球研究人员突破这一挑战
ARC Prize 2025大赛奖金丰厚得很:
总奖金池超100万美元
大奖直接70万美元
其中「概念贡献奖」7.5万美元
「最高分奖」5万美元
我算了下,换成人民币超700万啊!
怪不得去年比赛就吸引了
1500多支队伍参与,40篇论文发表
今年更是加码升级:
计算资源翻倍
开源要求更严格
评分规则也调整为激励概念突破
就是要引导大家不只是刷榜
而是要搞出真正的创新解法
这操作,我悟了:
ARC Prize 不是在办比赛
是在用重金集全球之力
薅全球最强AI 人才羊毛啊!
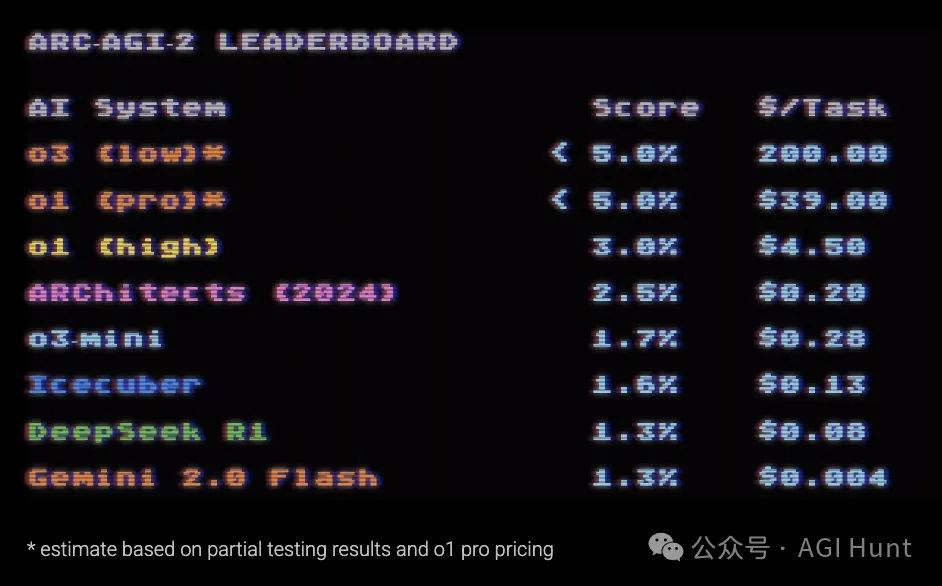
对比了一下,现在ARC-AGI-2 榜单排行
o3(low)预估成绩不到5%,每题200刀
o1-pro预估成绩不到5%,每题39刀
o1(high)成绩3%,每题4.5刀
ARChitects(2024优胜团队)成绩2.5%,每题0.2刀
o3-mini成绩1.7%,每题0.28刀
Icecuber成绩1.6%,每题0.13刀
DeepSeek R1成绩1.3%,每题0.08刀
Gemini 2.0 Flash成绩1.3%,每题0.004刀
卧槽,连OpenAI、DeepSeek这种顶流
都被打回了百分之个位数?
你可能好奇了,
这比赛到底咋玩?
好在ARC Prize官方已经透露
今年比赛继续在Kaggle 平台举办
就在本周上线
现在网上就能报名了
(文:AGI Hunt)