


极市导读
本文通过两个重要观察及理论分析提出了新的观点:一致性的损失是个性化概念语义偏移导致的, 并据此提出了一个简单有效的方法ClassDiffusion来提升个性化生成的一致性。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

TL;DR:
通过两组重要的可视化观察和理论分析, 我们探索了基于微调个性化方法的过拟合背后的本质: 语义空间中的语义偏移。根据这个理论我们提出了ClassDiffusion。ClassDiffusion可以在微调模型定制相关物体的同时, 使其保留遵循复杂文本提示词的能力。

文章主页: https://classdiffusion.github.io/
论文地址: https://arxiv.org/abs/2405.17532
代码地址: https://github.com/Rbrq03/ClassDiffusion
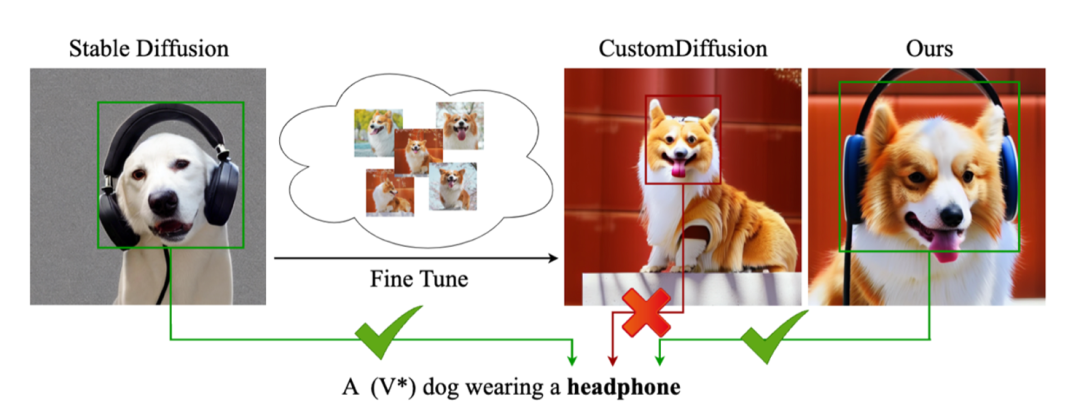
研究背景
个性化生成领域最近取得了飞速的发展, 但基于微调的个性化生成方法都不可避免得引入过拟合, 这导致模型仅能生成定制化物体, 而丧失遵循复杂提示词的能力, 本文通过两个重要观察(CLIP语义空间的语义距离增加和cross-attention在定制化物体区域的可视化强度)及从熵变角度的理论分析提出了对个性化生成任务下过拟合本质的新观点: 遵循复杂提示词能力的损失是个性化概念在语义空间的语义偏移导致的, 并据此提出了一个简单有效的方法ClassDiffusion来提升个性化生成的一致性。文章还表明这个方法可以在无需训练的情况下, 拓展至个性化视频生成。
实验观察
文章对之前方法微调后的模型进行了两个观测:
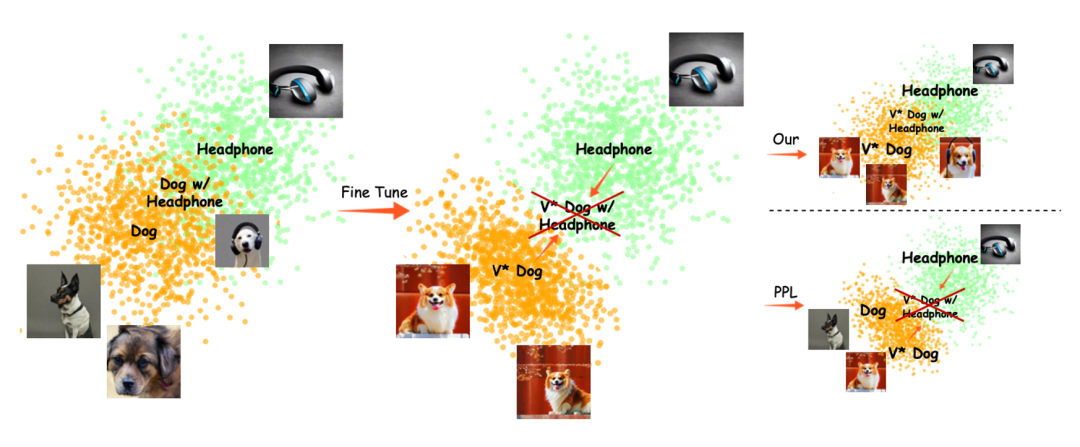
1.对文本空间进行观测, 本文可视化了CLIP文本编码器的语义空间.通过对比, 发现个性化概念的语义(e.g. “a photo of a sks dog”)和类别分布中心(e.g. “a photo of a dog”)的距离在个性化微调后显著增大, 这表明模型逐渐不认为个性化物体属于其对应类别, 这导致了在预训练过程中学习到的与类别相关的能力直接减弱,导致了遵循复杂提示词的能力丧失。
2.发现随着优化步数和学习率的增加, 模型中交叉注意力在个性化物体区域的激活程度呈现明显的下降趋势。这与第一个实验中的结论是一致的,进一步说明了丧失遵循复杂提示词的能力的本质是语义空间中的语义偏移。

因此文章提出了一个理论: 遵循复杂提示词能力的损失是个性化概念在语义空间的语义偏移导致的。
理论分析
由EBM[1]的结论可以得出:
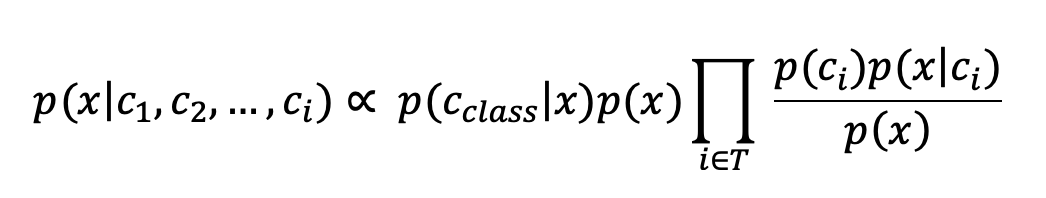
其中 为类别对应条件, 为模型隐式分类器,将 , 分别记为 .条件概率 的熵可以被计算为:
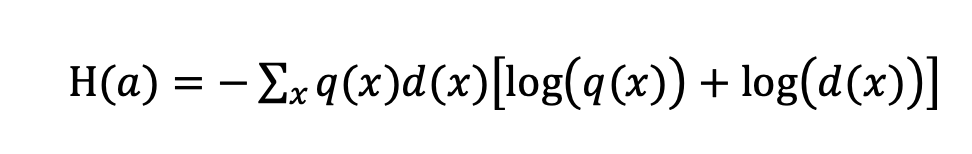
微调前后熵的变化可以被计算为:
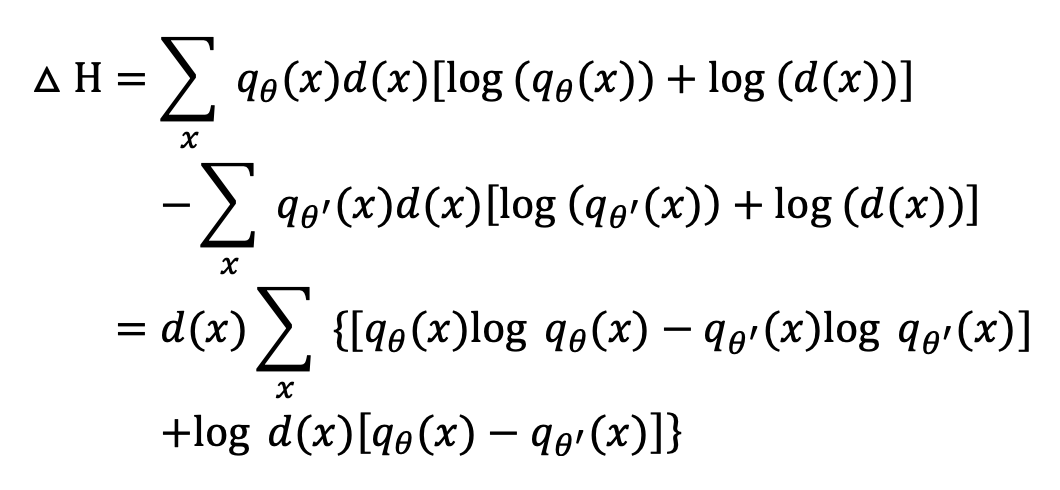
结合文章的实验观测和概率论的性质, 有
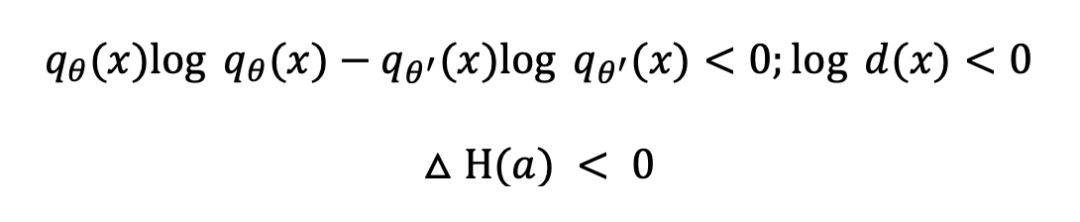
熵的降低导致了在条件下进行采样的难度增加, 从而导致了一致性的降低。
方法介绍
根据前文提出的理论,我们希望在个性化微调过程中尽量缩小个性化概念与文本空间中超类分布中心之间的语义距离, 因此我们将语义距离的度量引入损失函数中, 以在训练过程中最小化该距离。用 和 分别表示个性化短语和类短语的 CLIP 编码器输出的嵌入,语义保留损失可以用下式表示:
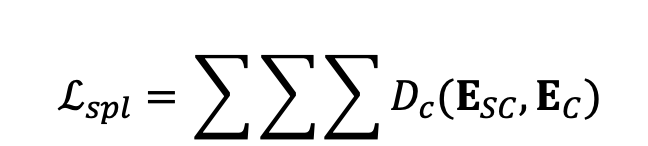
结合Diffusion原生训练的重构损失, 则最后完整的损失函数为:
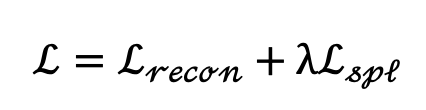
实验结果
核心实验
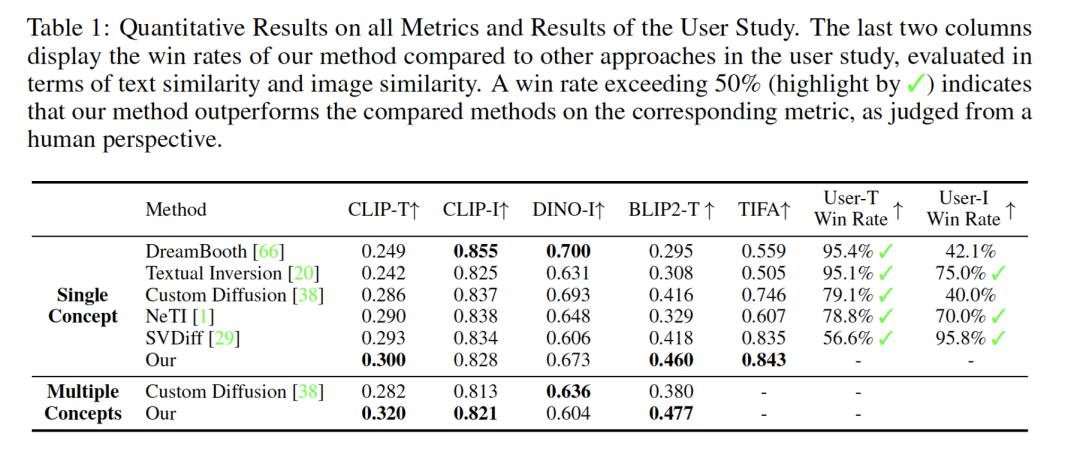
我们从定性和定量的角度分别验证了ClassDiffusion的有效性 从定性上,我们分别验证了在单个主体和多个主体下ClassDiffusion的生成效果。结果显示ClassDiffusion可以生成比现有方法更好一致性的结果


量化对在沿用了当前工作使用的CLIP-T, CLIP-I, DINO-I指标外, 还引入了BLIP2-T以获得更公平有效的评价, 结果表明ClassDiffusion在与提示词的一致性上优于现有方法。
个性化视频生成
我们说明了在经过ClassDiffusion方法下微调的权重, 可以在无需任何后微调的情况下, 在AnimateDiff的支持下直接应用到个性化视频生成上。这说明了ClassDiffusion方法的适用和灵活。


(文:极市干货)