

今天是2025年4月9日,星期三,北京,天气阴。
我们今天回到具体问题,看两个主要话题,一个是GPT4O引导追问以及Agent操作电脑、手机屏幕的思考,这是具体的落地问题。
另一个是大模型相关技术总结进展,可以看看数据侧,多模态的一些动向和索引。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、GPT4O引导追问以及Agent操作电脑、手机屏幕的思考
早上,社区有几个有趣的话题,引发出一些思考,很有趣。
1、关于GPT4O引导追问的功能原理及产品逻辑
这个是今天社区早上的一个小讨论,起因是成员发现,GPT4o那个会引出下N个问题保持持续对话的输出效果不错,是4o结尾会问用户一些问题。这个是如何做的?感觉也是为了问而问。
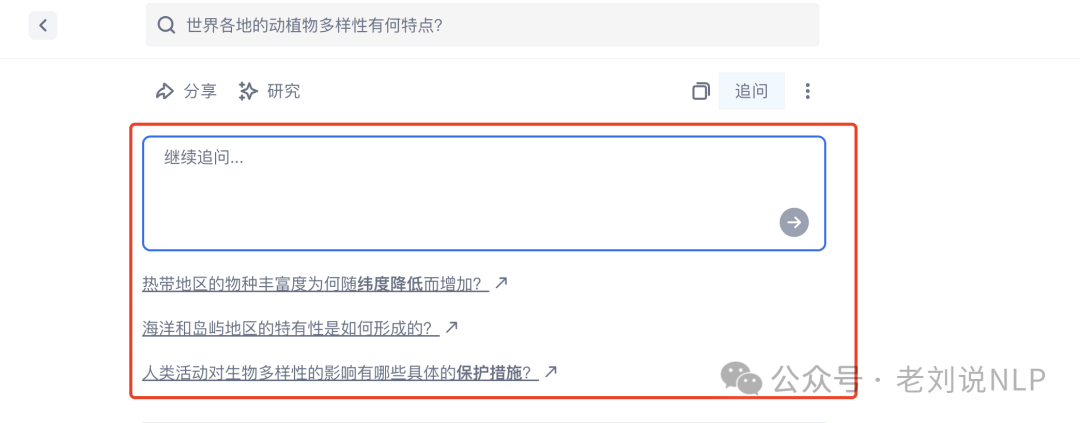
这个其实就是追问,比如Ai搜索里面的。追问是产品设计,跟传统搜索一样来的,为了二次引发点击,增加交互次数,假设后面开始有收益了,有广告了。每次追问新的点击,都能产生若干次点击,那就是新的流量,就能挣钱了。从技术上看,这是一种能力,会专门微调的。之前试过还试过基于KG做追问。需要人工构造一些追问的样本,做SFT。现在用户的角度,怎么追问会更好,更高质量,用户会更爱点。
所以,这其实就是为了问而问,只是差别不一样而已。但是,追问其实还有体验兜底的作用,就是用户意图澄清,通过追问的方式把用户真实想问的东西牵出来。这是一石二鸟的打法。另外的,再扩展,这个追问的能力,还能用在别的地方,那就是query rewrite,quey expansion,就是输入侧控制。并不是只能打一个点。这就是技术的魅力。技术组产品结合的魅力。
再进一步的,GPT4O的追问至少有两类,一类是这为了让用户补充细节,这可以联想做客户系统时候的追问填槽,就是上边说的澄清类似。一类是进一步深入对话。不过4o他们现在搞了这个,其实就有很多样本了,可以实际看用户有没有按照这个追问去继续聊,就可以用这个去持续改善这方面能力。
但是,再扩展一个话题,你们觉得所谓靠用户点踩,做数据飞轮成立么?
个人观点是不成立的,因为太主观不可控,乱点,不点,恶意点的情况都会存在。所以,很多方案说在线自学习,其实都是很扯淡的,实时根据用户反馈,去丢模型在线终身学习。这个我们之前也讨论过,很扯淡,需要人工参与。这种假想只适用于人工标注平台,因为目标就是为了拿标注数据。但平台给用户,目标不一样,因此就不成立了。所以,更倾向于一个结论。这种点踩数据,价值在于做用户需求统计,假设是用户如果很在意这种问题,那么可能这个问题可能比较重要,会点,这种统计型数据相对来说比较好利用起来。而不是用来做微调训练。
那么,感觉对用户也要有一些分析,比如找出其中一向喜欢捣乱瞎点的筛掉,留下那些比较认真的是否可行? 答案是忙不过来,兔有百窟。
又如,根据用户对话行为可以基本评判用户的素质,低素质用户甚至要降权,技术上需要精确的session管理。但这个并不妥,因为一是难识别,二是降权反产品逻辑,杀容易自损,反留存率目标。如果用户量很少,即使记录页面停留时间、记录复制按钮点击、记录下一步操作。这些数据收集上来,不过几百条,根本看不出趋势。人都不用了,那就更难了。
所以,这些事情顺下来,你会觉得哪哪都是窟窿。
2、关于Agent操作手机、电脑屏幕的一个实现逻辑原理
文章(https://mp.weixin.qq.com/s/kSUu_eHayr9MQeab2ryJrw)中关于Agent的几个点看起来是挺有收获的。
其中有问题比较有趣,在处理搜集、整理、纯文本的任务还比较好用,但是带有复杂的浏览器操作的时候会卡住。是不是因为国内网页网站可能设计得并不够好,限制了AI的能力增长?
对应的回复是,首先第一个并不是因为网页本身设计不好,我们叫点儿背不能怪社会。大部分人都可以用,为什么Agent不能用呢?我们更多思考的是这个问题。大家仔细体会可以体会到一个问题,当前通用Agent的产品,想要落地,有一个“木桶原理”不能有明显的缺项。
为什么(Agent)会找不到输入框?有几个可能,第一个可能视觉理解能力不如人,如果有弹窗遮住这些问题,可能是处理意外情况的这种能力不够,再深度推理的话,泛化能力不够,最终归结为它基础能力上的某一个缺项。
Agent真正产生实用价值,文本处理、思考、操作、环境感知和理解、应用工具和调用工具、反复尝试等能力,不能有明显的短板。有明显的短板存在,就会导致应用成功率急剧下降。所以一直坚持所有的模型都会做,包括语言、多模态的Agent。
顺着这个,如果真的要去做电脑或者手机的操作,那么入口就是对屏幕的理解,这个理解的任务的本质是目标检测+后续的决断。实就如微软开源的ominparser,代码: https://github.com/microsoft/OmniParser/tree/master,模型: https://huggingface.co/microsoft/OmniParser-v2.0,Demo:https://huggingface.co/spaces/microsoft/OmniParser-v2。
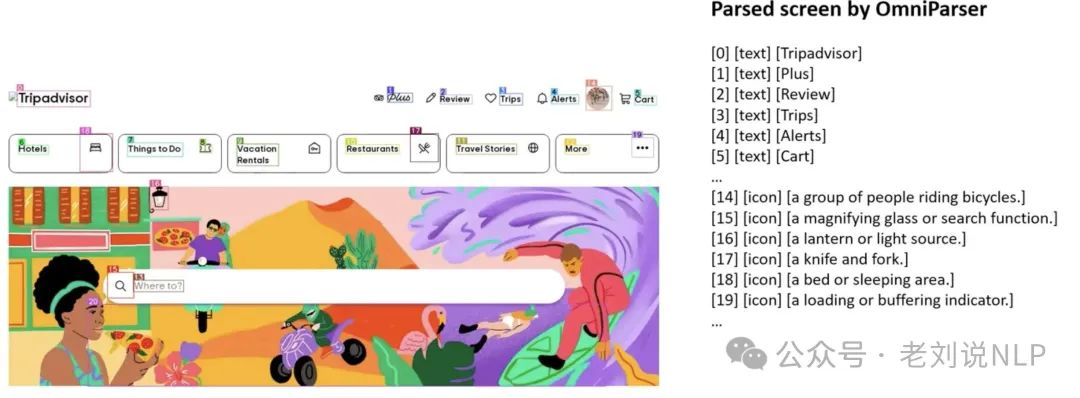
而就目标检测而言,挑战在于多样性,因为网页设计千变万化,并且还有是假链接。
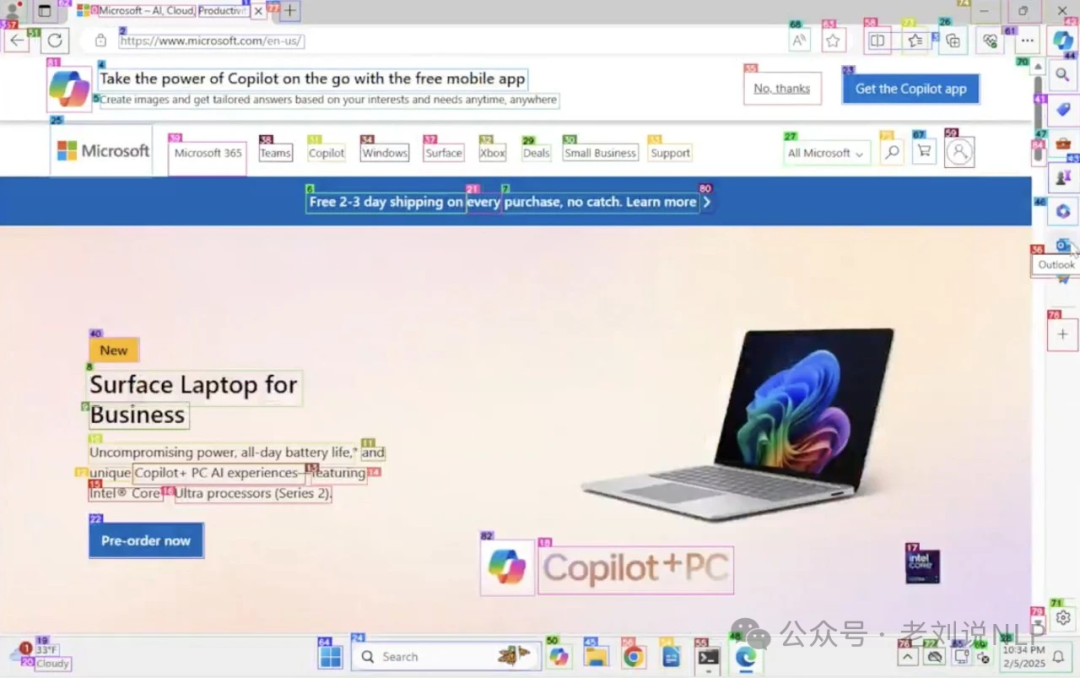
核心还是数据多样性如何保障,以及如何做网页交互,比如遇到假链接如何反馈出来。而进一步的,这个不单单是用于agent,很接近的就是当前的爬虫系统,其实也是很难做到统一性的,网页的内容组织各异。
而进一步的,去看如何操作电脑,其实有一一些开源项目,如下面这个例子:
代表性的,可以看看https://github.com/browser-use/browser-use
二、语音数据侧、多模态RAG及SQLRAG方案
1、数据侧进展
开源语音数据进展,《ChildMandarin: A Comprehensive Mandarin Speech Dataset for Young Children Aged 3-5》(https://arxiv.org/abs/2409.18584)发布,ChildMandarin和SeniorTalk两大语音数据集,覆盖3-5岁低幼儿童和75岁及以上的超高龄老年人,可以为面向儿童与老年人的语音识别、语音理解、语音分析等技术的发展提供宝贵资源。
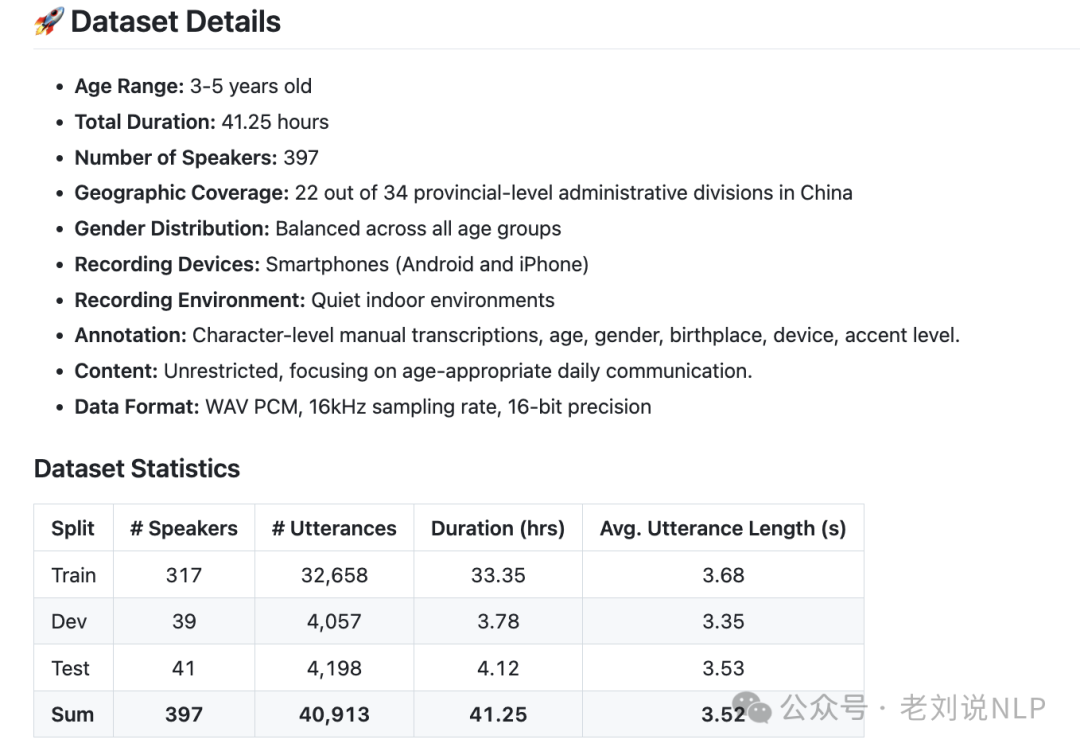
儿童数据集Github地址:https://github.com/flageval-baai/ChildMandarin,HuggingFace地址:https://huggingface.co/datasets/BAAI/ChildMandarin。老年人数据集,Github地址https://github.com/flageval-baai/SeniorTalk ,HuggingFace地址:https://huggingface.co/datasets/BAAI/SeniorTalk
2、RAG相关技术总结侧进展
首先,在多模态RAG方面,Awesome-RAG-Vision:计算机视觉领域中检索增强生成(RAG)总结,涵盖图像理解、视频理解、视觉生成等多领域应用的研究论文和教程资源: https://github.com/zhengxuJosh/Awesome-RAG-Vision,是很好的索引,包括面向图像的,视频的,以及混合多模态的。
同样的,关于RAG的技术汇总:Awesome-RAG:https://github.com/Danielskry/Awesome-RAG,指引的都不错,也可以备查。

也有SQLRAG方案,《Retrieval augmented text-to-SQL generation for epidemiological question answering using electronic health records》,https://arxiv.org/pdf/2403.09226,核心思路是将文本到SQL生成与检索增强生成(RAG)相结合,以使用EHR和索赔数据回答流行病学问题,通过在文本到SQL过程中集成医学编码步骤来提高性能。
可以看其中召回sql对的逻辑,重点看这个图:

核心逻辑在医疗编码步骤是如何集成到文本到SQL过程中的?
技术实现逻辑如下:
首先,使用大模型从自然语言问题中提取医疗实体。 接着,将这些医疗实体插入到SQL查询中作为占位符(例如,[condition@disphagia])。
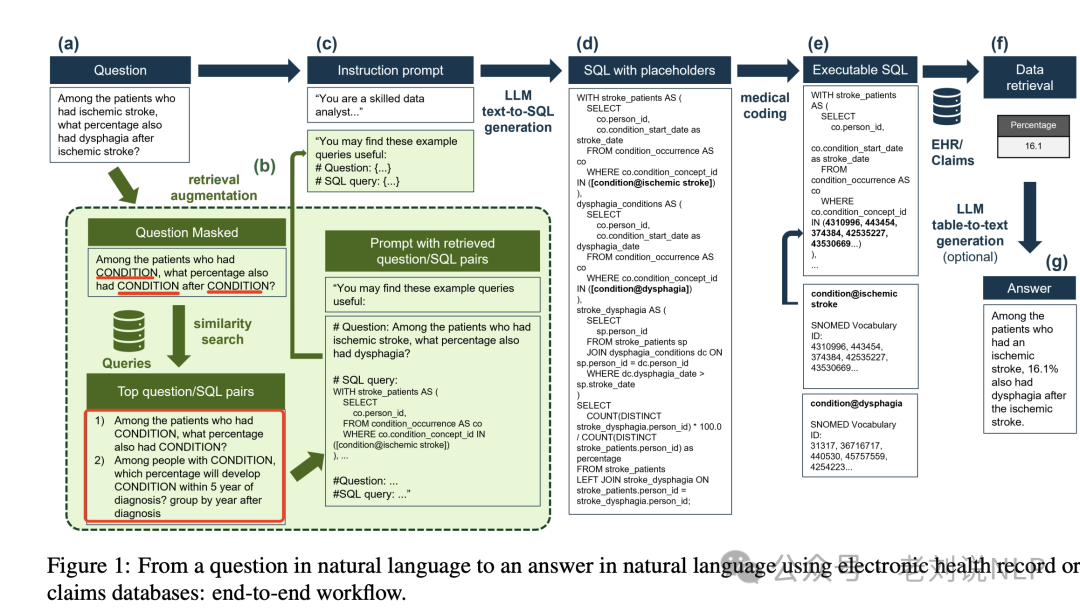
然后,使用SapBERT嵌入模型计算每个实体与SNOMED本体术语的余弦相似性,选择前50个匹配项。通过进一步的LLM提示验证是否应将该代码分配给输入实体,从而调整占位符。
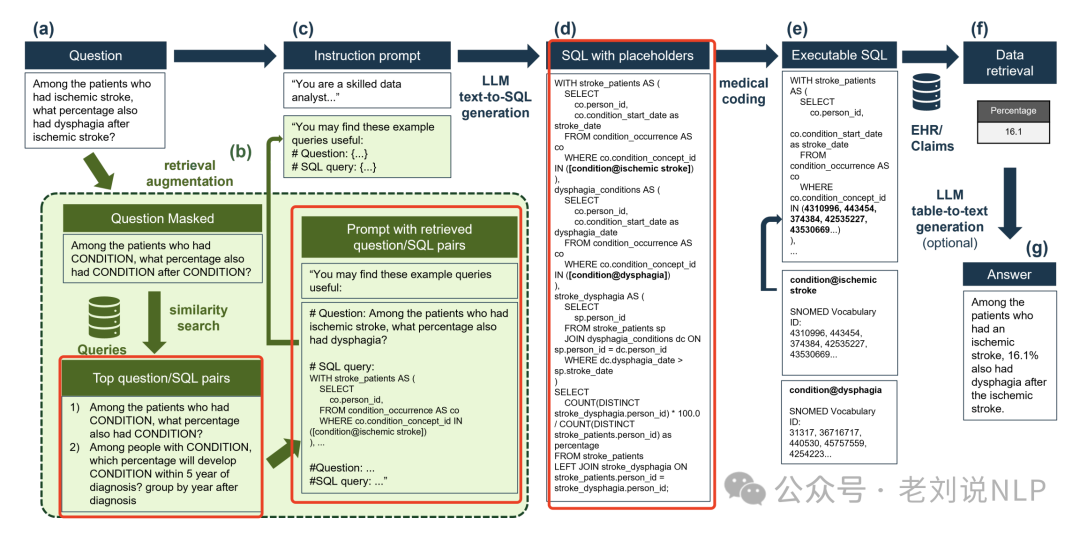
最终生成的SQL查询包含了归一化后的医疗代码,可以在符合OMOP CDM的数据库上正确执行,以检索所需的数据。
这种占位符其实就是符号化的方法,可以提高一定的泛化性。
参考文献
1、https://mp.weixin.qq.com/s/kSUu_eHayr9MQeab2ryJrw
(文:老刘说NLP)