
今天是2025年4月17日,星期四,北京,晴。
社区近日完成社区分享《老刘说NLP社区第42讲-RAG的花式变体及落地建议》,回放链接见社区群。
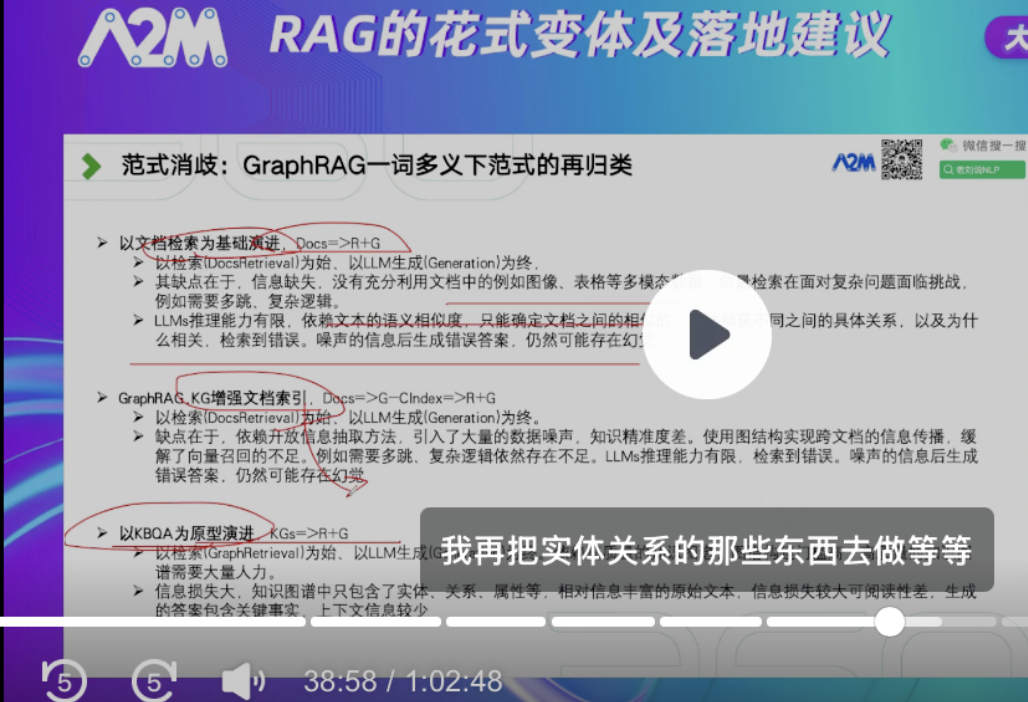
在本次分享中,尝试回答了以下问题:目前RAG都有哪些玩法?有哪些变体?目前RAG在真实落地中的问题坑点;目前RAG各个变体的特点和适用场景;目前RAG的落地建议以及RAG的未来趋势及挑战。
本文将其中的重点分享出来,供各位参考。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、RAG问答在实际落地中存在的问题及应对策略
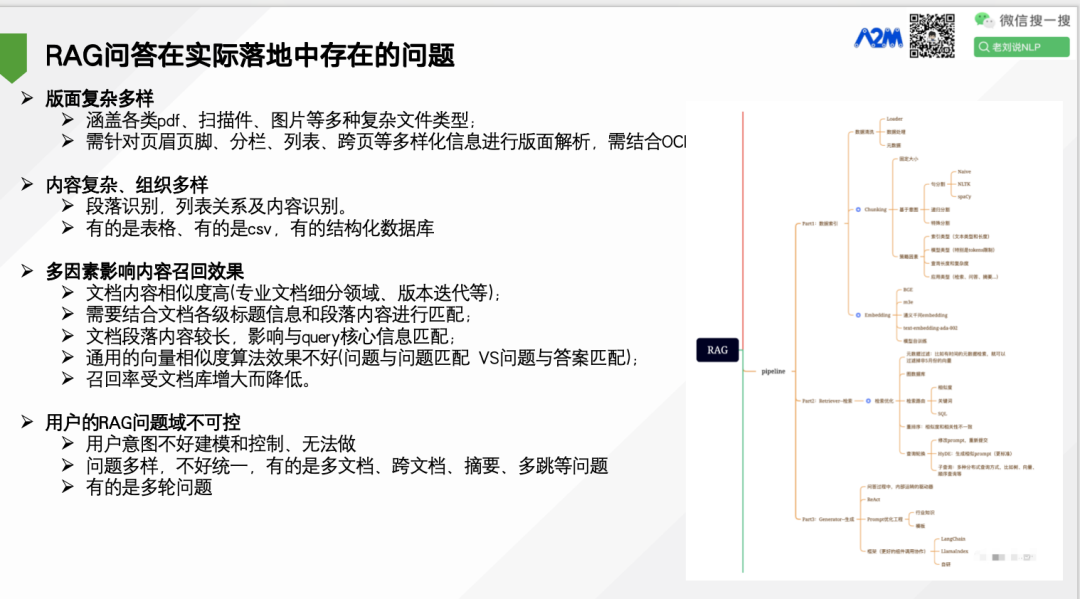
版面复杂多样,涵盖各类pdf、扫描件、图片等多种复杂文件类型; 需针对页眉页脚、分栏、列表、跨页等多样化信息进行版面解析,需结婚合OCR能力。
内容复杂、组织多样,段落识别,列表关系及内容识别。有的是表格、有的是csv,有的结构化数据库
多因素影响内容召回效果。文档内容相似度高(专业文档细分领域、版本迭代等);需要结合文档各级标题信息和段落内容进行匹配;文档段落内容较长,影响与query核心信息匹配;通用的向量相似度算法效果不好(问题与问题匹配 VS问题与答案匹配);召回率受文档库增大而降低。
用户的RAG问题域不可控。用户意图不好建模和控制、无法做问题多样,不好统一,有的是多文档、跨文档、摘要、多跳等问题有的是多轮问题。
很多优化方案ROI很低。为了照顾某些长尾的case做了很多低回报的优化,如GraphRAG吃力不讨好,很费token
评估与优化很难做,测试集局限性,企业自建测试集常遗漏长尾问题,自动评估比人工更悲观;参数调优复杂,chunk_size、embedding维度等超参数需反复实验,微调成本高
RAG的能力项不封闭。RAG的能力需要很多,有拒绝回答,有问题生成,有追问,引文生成等多个能力,需要微调,能力还不一定有迁移性。
有监督样本构造困难。需要较强的业务知识;技术理想(高精度、低延迟、低成本)vs 工程现实(数据异构、算力限制、领域特异性)
RAG的现实是,RAG多环节分块做优化,方案人手一份。

所以,RAG的现实是,补丁策略集大成,分阶段地提升准确性,处处是路由器。
例如,预处理侧补丁策略解决文档预处理问题,打标签、关键词问题;向量化侧补丁策略解决领域文档的向量化问题;召回侧补丁策略解决文本的召回相关性问题;模型侧补丁策略缓解大模型的幻觉解码问题。
二、为什么以及如何做文档解析?
文档解析是RAG的“数据清洗”环节,直接影响系统的知识覆盖率和答案可靠性。其核心目标是将人类友好但机器混乱的原始数据,转化为机器可理解、检索和生成的标准化信息。
1、为什么要做?
1)解决非结构化数据的可用性问题。 专业领域文档(如PDF、Word)通常以非结构化格式存储,包含标题、段落、表格等人类易读但机器难处理的内容。文档解析通过提取文本、恢复版面结构(如表格识别、段落划分),将其转换为半结构化数据(如Markdown/HTML),便于后续向量化和检索。
2)提升检索精度。 解析时需合理分割文档(如按语义块分块),避免检索时因截断丢失上下文。例如,将长文档按章节或逻辑段落分割,确保每个分块包含完整语义单元。解析需提取图文混合内容(如PDF中的文字和OCR识别图片),为多模态RAG提供统一输入。
3)优化生成质量。 解析错误(如表格误识别为纯文本)会导致检索噪声,进而影响生成答案的准确性。高质量解析能过滤无关元素(如页眉页脚),保留核心内容。解析后的结构化数据可精准嵌入Prompt,为大模型提供清晰上下文,减少幻觉(如虚构事实)。
4)适配技术流程。文本需解析为干净格式后才能编码为向量。例如,PDF解析工具(如PDFPlumber)提取文本位置信息,辅助语义分块。
5)领域适应性。 专业领域(如医疗、法律)文档有独特格式(如病例表格、法律条款)。解析需定制化处理(如术语保留、条款关联),确保领域知识被准确检索。
2、如何做?
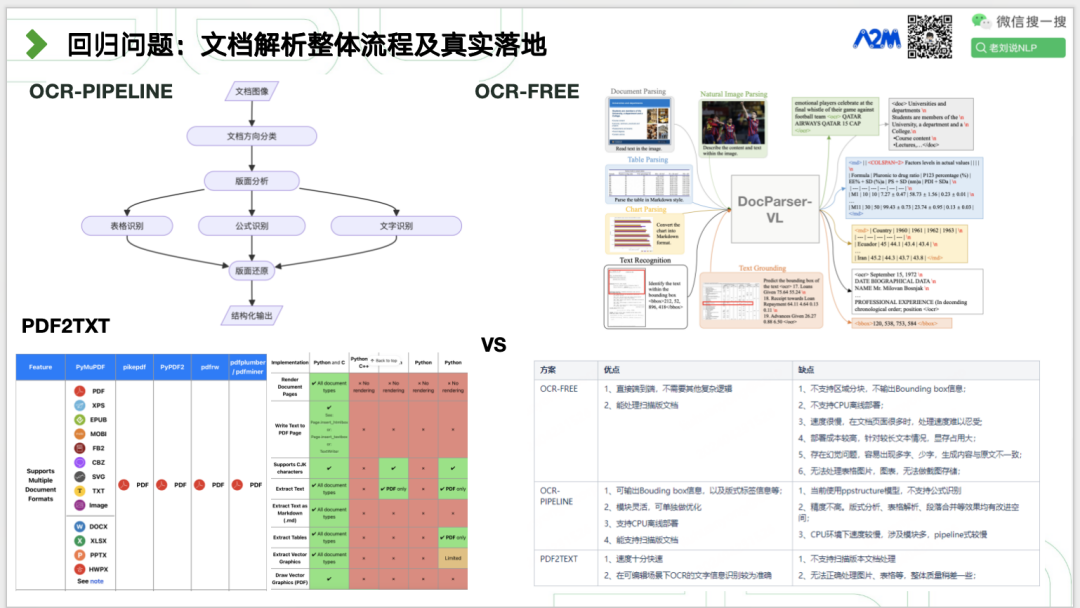
具体如何做,有多种方式。
三、多模态RAG怎么做?
1、为什么要做多模态RAG?
多模态RAG通过整合多种模态的信息,能够更准确地检索到与用户查询相关的知识。**同时,在生成答案时,也能够利用多种模态的信息来增强生成内容的准确性和丰富性。
1)突破单一模态限制,提升理解深度,传统RAG仅处理文本,而多模态RAG能同时解析文档中的视觉布局、图表、手写内容等非文本信息。例如,医疗领域结合病历文本和医学影像,辅助诊断。教育领域通过图文、视频混合检索生成更生动的教学材料。
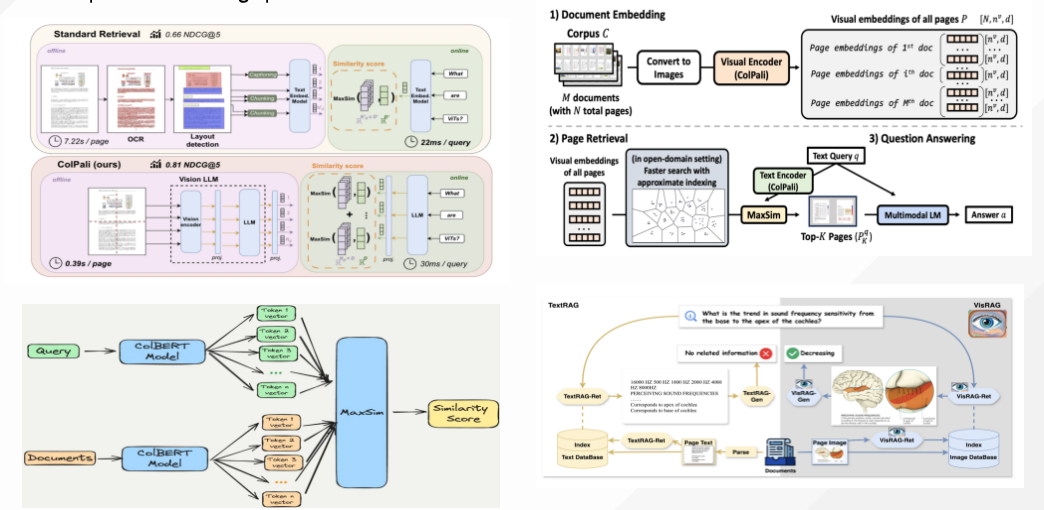
2)减少信息丢失,增强生成准确性。传统方法将图像转为文本时可能丢失细节(如颜色、空间关系),而多模态RAG直接处理原始图像或音频,保留完整信息。例如电商搜索中用户上传商品图片,系统直接匹配视觉特征而非依赖文本描述;文档处理中跳过OCR步骤,直接从图像生成嵌入向量(如ColPali框架)。
3)适应复杂场景,扩展应用边界。 多模态RAG支持跨模态检索和动态推理。例如跨页/跨文档任务中M3DOCRAG框架处理多页PDF的技术文档;实时交互中,结合语音和图像提问(如智能客服或虚拟助手)。
2、如何做?
可以使用解析式文档多模态RAG或者VQA式进行。

例如:
解析式文档多模态RAG的思想为,将文档切分为页面,然后再用版式识别的方式对文档进行各种模态元素进行分割、解析、提取,然后再嵌入、检索。
有三种路线:
一种是对图像和文本直接做Embedding,使用多模态嵌入模型来嵌入图像和文本,然后使用相似性搜索检索两者,最后将原始图像和文本块传递多模态模型以进行答案合成,注意,这个用到的大模型是多模态模型;
一种是使用多模态大模型对图像生成摘要,将非文本模态转化为纯文本模态,并使用textembedding的方案进行嵌入,最后将文本块传递给文本生成模型以进行答案合成,注意,这个用到的大模型是文本语言模型;
一种是使用多模态大模型对图像生成文本摘要,再对图像文本摘要经过text-embedding进行嵌入表示,但是同时使用参考原始图像嵌入和检索图像摘要,最后将原始图像和文本块传递给多模态模型以进行答案合,注意,这里用到的大模型是多模态模型;
DocVQA式文档多模态RAG的思想为将文档切分为页面图像,不再细分,然后根据页面图像级别进行检索,类似于docvqa。
四、为什么且如何做GraphRAG?
1、为什么要做?
传统RAG中的chunk方式会召回一些噪声的片段,涉及到聚合、过滤、统计时:向量召回准确性低;LLM数学计算能力有限;
传统RAG中Chunk之间彼此是孤立的,缺乏关联,在跨文档问答任务上表现不太好;对于答案涉及多文本块/多文档的问题,普通的向量召回/ES召回能力有限;
用大模型进行任务规划不确定性较高,在特定可控生成任务上表现并不好;大模型进行改写、推荐等任务中,很发散。
领域语料并不多,大模型跳出回答,需要学会拒答,RAG整体理解受限制,文本 Embedding 后可解释性低。
RAG在拼接文本片段时可能导致上下文过长,产生“中间迷失”现象。RAG只能检索部分文档,难以全面把握全局信息,影响查询重点摘要(QFS)等任务的表现。
2、如何做?
有多种方案,例如:
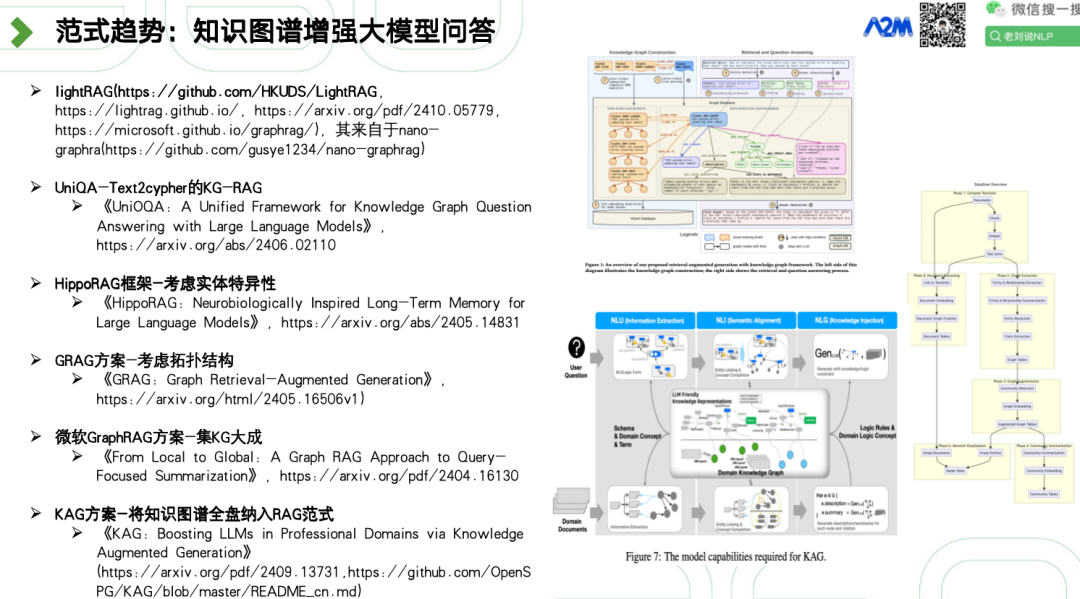
GraphRAG(by Microsoft,https://github.com/microsoft/graphrag) 利用LLMs构建基于实体的知识图谱,增强查询重点摘要(QFS)任务。该系统通过预生成相关实体群体的社区摘要,捕获文档集合内的局部和全局关系;
GraphRAG(by NebulaGraph,https://www.nebula-graph.io/posts/graph-RAG) 将LLMs集成到NebulaGraph数据库中,提供更智能和精确的搜索结果。该系统通过将查询嵌入到图结构中,利用LLMs进行更复杂的推理和信息检索;
GraphRAG(by Antgroup,https://github.com/eosphoros-ai/DB-GPT) 在文档检索阶段,使用LLMs提取三元组并存储在图数据库中。在检索阶段,识别查询中的关键词,定位图数据库中的对应节点,并使用广度优先搜索(BFS)或深度优先搜索(DFS)遍历子图。生成阶段将检索到的子图数据格式化为文本,并提交给LLMs进行处理;
NallM(by Neo4j,https://github.com/neo4j/NaLLM) 将Neo4j图数据库技术与LLMs结合,探索Neo4j与LLMs的协同作用,主要应用于自然语言接口到知识图谱、从非结构化数据创建知识图谱以及使用静态数据和LLM数据生成报告;
LLM Graph Builder(by Neo4j,https://github.com/neo4j-labs/llm-graph-builder) 自动构建知识图谱,适用于GraphRAG的图数据库构建和索引阶段。该系统主要利用LLMs从非结构化数据中提取节点、关系和它们的属性,并使用LangChain框架创建结构化知识图谱。
五、为什么且如何做Deepresearch
1、为什么简单RAG之外,还需要Deepresearch
RAG(检索增强生成)和Deep Research(深度研究)虽然都结合了检索与生成技术,但定位和能力存在显著差异。
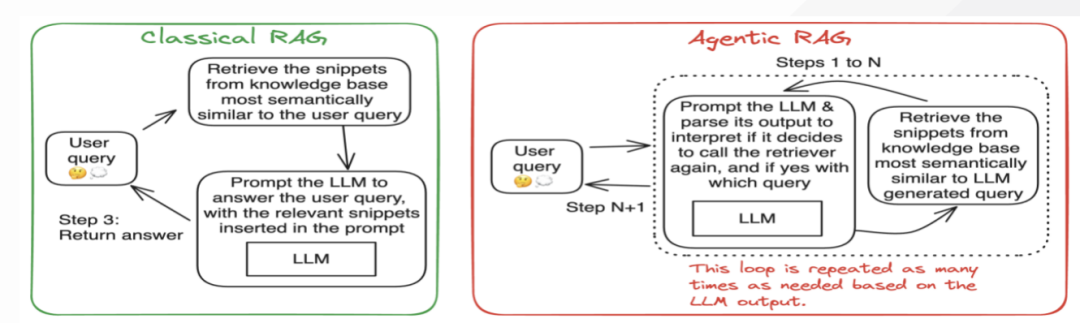
首先,核心目标不同,RAG主要用于实时检索与简单生成,解决大模型的知识时效性、事实准确性和领域适配问题。例如,快速回答“哪吒的性格特点是什么”这类事实性问题。Deep Research专注于深度分析与复杂推理,能生成系统性报告(如市场分析、学术综述),通过多轮检索、逻辑推演和动态验证实现知识创造。
其次,在实现技术上,RAG采用扁平化检索,依赖向量相似度匹配,适合单跳查询。生成依赖检索内容直接基于检索片段生成答案,易受噪声干扰。但是,部署简单,适合轻量级数据,难以处理复杂关联。而Deep Research利用多轮动态检索,通过Agent机制拆解复杂问题,循环优化检索策略(如调整关键词、切换数据源),需要深度整合与推理,输出带引用和逻辑链的长篇报告,但是算力成本高(生成耗时5-30分钟),适合高价值场景。
最后,在适用场景上,RAG适合简单问答、低延迟场景(如客服FAQ)。Deep Research适合需多跳推理的任务(如“量化龙族形象从《山海经》到《哪吒》的演变”)以及专业报告生成(如金融分析、科研综述),需结构化输出和可信引用。
当然,两者并不冲突,可以这么粗暴的认为,RAG是“搜索+生成”的基础工具,而Deep Research是“研究助理+分析师”的高级形态。两者互补:RAG解决“是什么”,Deep Research回答“为什么”和“怎么办”。企业可根据需求分层使用,例如用RAG过滤简单问题,Deep Research处理复杂分析,也就是需要加一个路由。
2、如何做?
当前已有开源方案,如下:

总结起来,步骤如下:
步骤一,问题分析。大模型分析用户输入问题,确定回答该问题所需的角度和步骤。目前许多大模型(如DeepSeek、ChatGPT、Gemini等)只需勾选推理选项即可生成这一过程。
步骤二,在线搜索。根据生成的问题逐一进行在线搜索,并获取搜索结果的前k项,将其内容反馈给大模型。
步骤三,内容总结。大模型根据在线内容总结出简洁答案。
步骤四,答案判定。将所有内容汇总后,由大模型判断答案是否完整、准确。如果完整准确,则输出最终答案。如果达到设定的循环次数或token上限,也输出最终答案。否则,生成新的问题,重新进入第一步,同时将历史解决信息带入下一次循环。
但是,我们需要注意的是,Deepresearch的核心依赖大模型能力本身,其需要进行规划能力,这个需要微调或者强化。
总结
本文主要回顾了老刘说NLP社区第42讲-RAG的花式变体及落地建议的一些分享内容,供大家批评指正,技术总是变化的,要用发展的眼光来评价他。不存在最好的方案,只有最合适的方案。
(文:老刘说NLP)