

2025年,随着DeepSeek风靡全球,中国不断加强AI基础研究和产业体系布局。
4月27日晚,央视披露的最新数据显示,截至2025年4月9日,中国 AI 专利申请量达157.64万件,占全球申请量的38.58%,接近40%,位居全球首位。
同时,中国目前已累计培育400余家 AI 领域国家级专精特新“小巨人”企业,占据了全球1/10的 AI 产业规模,已形成覆盖基础层、框架层、模型层、应用层的完整 AI 产业体系。
另据斯坦福大学李飞飞团队(Stanford HAI)发布的《2025年人工智能指数报告》显示,全球 AI 相关专利申请数量正在上升。2010年至2023年期间,AI专利数量稳步大幅增长,从3833件激增至12.2511万件。仅2024年一年,AI 专利数量增长了29.6%,接近30%。
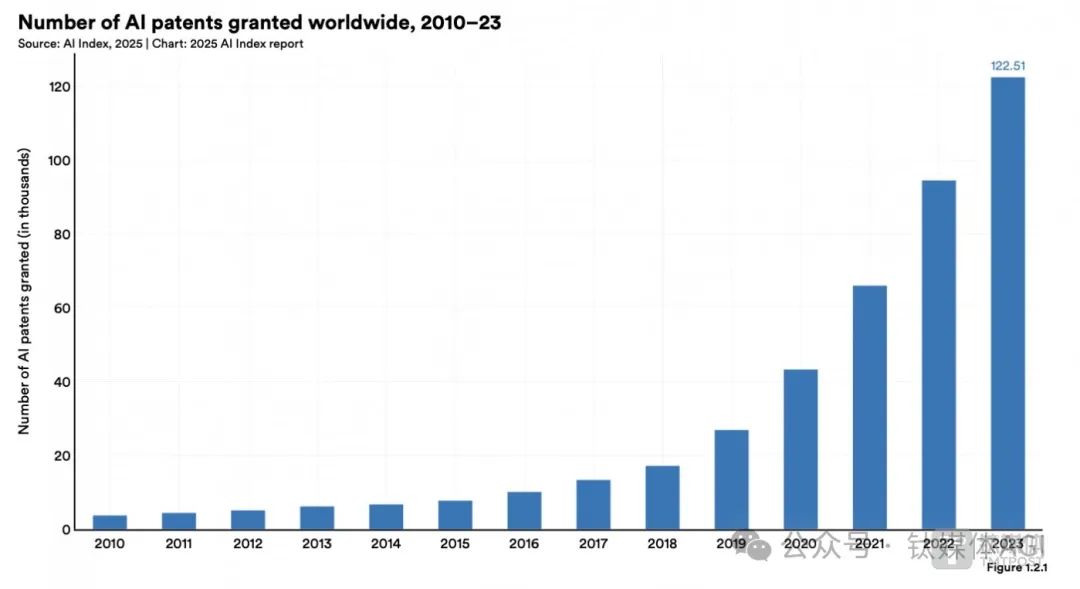
其中,截至2023年,中国在 AI 领域专利总量方面领先,相关专利占全球所有专利授权的69.7%。而按人均计算,韩国和卢森堡在 AI 生产方面表现突出。
如今,中国加速AI大模型和AI应用研发力度。就在4月底新加坡举行的深度学习顶会ICLR 2025上,阿里达摩院(湖畔实验室)、新加坡国立大学、清华大学等联合研究团队发表论文,提出全新开源视觉生成架构DyDiT,通过时间步长与空间区域的智能资源分配,将DiT模型的视觉生成任务中推理算力削减51%,生成速度提升1.73倍。
同时,在ICLR 2025上,谷歌DeepMind、微软、Meta、加利福尼亚大学伯克利分校(UC伯克利)、中国科学技术大学等研究团队,以及“AI教父”杰弗里·欣顿 (Geoffrey Hinton),ICLR发起者、“图灵奖得主”杨立昆(Yann Lecun)等AI学术大咖都参与其中,多份研究成果重要性不亚于ChatGPT。
很显然,大模型的世界依然风云变幻。
今年Q1超55个大模型“卷生卷死”,
全新DyDiT架构创新替代Sora

4月27日—28日,深度学习领域国际顶级会议ICLR(International Conference on Learning Representations) 2025在新加坡举行,成千上万人参加这一盛会。
据ICLR统计,研究人员向主办方提交了122份研讨会提案,比2024年的103个增加1.18倍,最终接受40份提案,比去年同期增加2倍(200%)。
ICLR 2025现场,包括清华“姚班”校友、美国斯坦福大学的陈丹琦,美国加州大学伯克利分校教授宋晓冬(Dawn Song),北京通用人工智能研究院院长朱松纯,香港大学计算机与数据科学学院马毅教授等人发表演讲。同时,“AI教父”、诺奖得主、加拿大多伦多大学教授杰弗里·辛顿(Geoffrey Hinton),ICLR发起者、“图灵奖得主”杨立昆(Yann Lecun),麻省理工学院电气工程与计算机科学系副教授何恺明(Kaiming He)等AI学术领域大佬也都在现场参与其中。

2025年,DeepSeek引发全球新一轮AI模型热潮,同时也意味着,世界依然需要除OpenAI GPT之外能够实现运算效率降低的基座模型。
如今,大模型研发人员依然在“卷生卷死”。公开数据显示,2024年第四季度,全球有49个大模型更新发布,今年一季度就有55个,最多的时候一周发8个模型。

作为国内 AI 领域最大研究团队之一,阿里达摩院今年持续发paper,共有13篇论文被ICLR 2025录用,涵盖了视频生成、自然语言处理、医疗AI、基因智能等领域,其中3篇被选为Spotlight。
其中,达摩院、新加坡国立大学、清华大学等联合研究团队提出了全新DyDiT架构,其中,达摩院的赵望博为通讯作者,新加坡国立大学校长青年教授、北京潞晨科技有限公司董事长尤洋也是本论文作者。
具体来说,过去一年来,由Sora模型开始推动的 Diffusion Transformer(DiT)架构在视觉生成领域展现出了强大的能力,得到了包括 Stable Diffusion 3、Flux、Sora、WanX、Movie Gen等众多视觉模型的应用。但 DiT 架构也面临一些重大挑战,其中最显著的就是运行效率问题。
业内提出了多种方法来解决这一问题,包括高效的Diffusion采样器、特征缓存、注意力机制以及模型压缩剪枝等。但这些方法都是针对静态不变模型,即图像生成过程使用的模型规模完全不变,导致了潜在的冗余浪费问题,尤其DiT架构在执行视觉生成任务容易造成极高的算力消耗,限制其往更广泛的场景落地。
达摩院团队提出全新DyDiT架构,能够根据时间步长和空间区域自适应调整计算分配,有效缓解视觉生成任务中的算力消耗问题。使用者更可根据自身的资源限制或者部署要求,灵活调整目标的计算量,DyDiT将自动适配模型参数,实现效果与效率的最佳平衡。
据论文显示,团队仅用不到3%的微调成本,将DiT-XL的浮点运算次数(FLOPs)减少了51%,生成速度提高了1.73倍,在ImageNet测得的FID得分与原模型几乎相当(2.27vs2.07)。
目前,DyDiT相关训练与推理代码已开源,并计划适配到更多的文生图、文生视频模型上,目前基于知名文生图模型FLUX调试的Dy-FLUX也在开源项目上架。
除了达摩院这篇论文外,ICLR 2025上阶跃星辰有 4 篇论文入选,包括《Unhackable Temporal Rewarding for Scalable Video MLLMs》,《DreamBench++: A Human-Aligned Benchmark for Personalized Image Generation》,《Discrete Distribution Networks》,《Reconstructive Visual Instruction Tunning》,覆盖图像生成模型质量评估、大模型视觉监督设计、大模型预训练等方向。
根据ICLR官网,本次ICLR 2025优秀论文委员会经过两阶段评选过程,最终确定了3篇优秀论文获奖者和3篇荣誉提名如下:
-
谷歌DeepMind和普林斯顿大学团队的《Safety Alignment Should be Made More Than Just a Few Tokens Deep.》 -
不列颠哥伦比亚大学等人的《Learning Dynamics of LLM Finetuning.》 -
新加坡国立大学和中国科学技术大学团队的《AlphaEdit: Null-Space Constrained Model Editing for Language Models.》 -
弗吉尼亚理工大学、UC伯克利、普林斯顿大学等团队发表的《Data Shapley in One Training Run.》 -
Meta Fair团队的《SAM 2: Segment Anything in Images and Videos.》 -
Mistral AI和Google DeepMind团队的《Faster Cascades via Speculative Decoding.》
朱松纯近期表示,OpenAI的创新主要是在模型(采用了Google发明的Transformer进行自回归生成式预训练),算法与执行层的优化,没有触及数理框架和哲学层面。所谓“全栈式”AI是指在模型、算法到执行层面软硬件一体化优化,他们在这方面做得很好。而DeepSeek在工程落地、API产品化、算力优化等方面取得了非常好的成绩。但主要集中在工程部署层面,没有触达人工智能的核心问题——比如模型、算法、认知架构、智能机理等。
朱松纯强调,对底层创新的认知不足,是一个全世界的普遍问题,不仅是 AI 领域。通用 AO 是一个大科学、大工程的问题,需要长期的、多层次的科技创新。大科学的问题需要有统一的理论框架解释各种智能现象,构建智能科学的基础理论与框架;大工程的问题是实现个体的和社会层级的智能体。
“AI教父”发联名信阻止OpenAI重组,
马斯克加装“弹药”瞄向AGI
OpenAI计划向营利性公司的转型受到阻碍。
近日,辛顿、Hugging Face首席伦理科学家玛格丽特·米切尔(Margaret Mitchell)和美国加州大学伯克利分校教授斯图尔特·拉塞尔(Stuart Russell)以及10名前OpenAI员工,近期向美国联邦检察长提交联名信,敦促美国当局阻止OpenAI从非营利组织转变为PBC公益公司。
公开信中,辛顿等人表示,OpenAI 独特的非营利法律结构是防止商业利益凌驾使命的保障,重组将削弱公众利益的保护机制,违反公司章程,构成对其非营利责任的威胁。
他们在公开信中要求,OpenAI解释为什么2023年OpenAI CEO奥尔特曼(Sam Altman)在国会作证时所强调的治理保障措施对OpenAI的使命至关重要,却在2024年却成为了其使命的障碍。信中呼吁,OpenAI需要停止重组,并保护治理保障措施(包括非营利组织的控制权),确保非营利组织保留控制权。
与“AI教父”辛顿步伐一致,马斯克也在对标OpenAI,不仅通过法律诉讼反对转型一事,而且准备加装更多“弹药”全面反击。
4月26日,据彭博报道,马斯克旗下的xAI与X合并后的XAI Holding公司,正与投资者计划筹集超过200亿美元资金,预计投后估值超过1200亿美元(约合8745亿元人民币),所得资金或可用于偿还马斯克将X平台私有化所产生的债务。本轮融资预计将在未来几个月内完成。
按照彭博说法,这次寻求融资的目的可能是偿还债务。当时马斯克以440亿美元把X平台(当时名为Twitter)私有化,需要从摩根士丹利获得的贷款,利率为14%,而如今摩根士丹利获推出一笔9.5%利率的固定利率新贷款,用于让马斯克偿还高息的旧债务。
有消息称,马斯克的X将计划偿还银行持有的最后12亿美元与收购X平台相关的银行债务。而在今年2月,摩根士丹利还和其他六家银行,共计出售了47.4亿美元与X相关的债权。
如今在产品层面,xAI的Grok大模型已经深入整合到X平台中,并且利用X平台数据进行模型训练,成为Grok的最大竞争力。
美国研究机构PitchBook-NVCA近日发布的全球风投交易市场报告显示,截至3月31日的2025年第一季度,AI和机器学习领域投融资交易数量2101件,交易价值(额)731亿美元,占全球风投总额比重为57.87%。
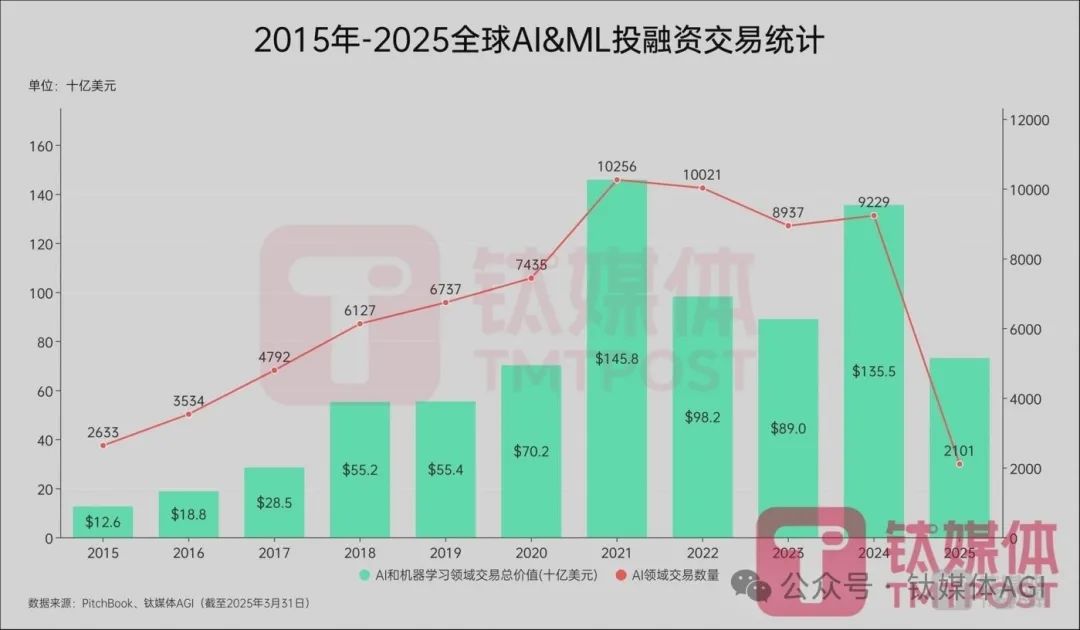
就在3月31日,美国OpenAI公司宣布完成软银领投的400亿美元融资,估值高达3000亿美元。这笔交易占美国风投资金50%以上,占全球总额的三分之一。
因此,不管是马斯克的 xAI,还是其他 AI 公司,都必须要有足够的资金和资源,才能在未来的竞争中占据一席之地。
据报道,硅谷风投Benchmark最近领投了Manus母公司蝴蝶效应新一轮融资,总额达7500万美元,使得投后估值大幅提升,增长约五倍(500%),达到近5亿美元(折合人民币37.5亿元)。
金沙江创投主管合伙人朱啸虎近期表示,大模型前两年火爆,今年热度有所下降,AI应用企业迎来爆发式增长,建议创业公司不要在底层模型训练上浪费资金,全力拥抱开源模型。而在商业层面,他认为,技术固然重要,但商业产品更为关键,产品能否让用户愿意付费使用是重点。
朱啸虎表示,过去6个月,中国有非常多的创业公司每周有近10%的环比增长,月环比增长20%以上,虽然这些数字还比较小,但是增长速度类似于当年团购行业早期增长速度,这是非常让人兴奋的。
4月27日,字节跳动基础架构团队宣布,ByteBrain利用大模型(LLM)优化火山引擎稳定性,重要oncall提效 26%,基于运筹优化算法对系统成本进行优化,近三年节省成本超10亿元人民币。
“学术论文仅仅是ByteBrain团队的副产出,工业界最重要的是业务收益。”字节跳动团队表示。
此外,作为国内AI独角兽之一,阶跃星辰4月27日发布图像编辑模型Step1X-Edit,性能开源最佳,这是最近一个月阶跃星辰上新的第三款多模态模型。除了模型,阶跃星辰还在汽车、智能手机、IoT、具身智能等四个关键赛道完成技术落地,与吉利汽车集团、千里科技、智元机器人、原力灵机、TCL等企业合作,2025上海车展上,吉利银河展示的“蛋舱”产品,其中就内置阶跃的多模态大模型技术。
当下,AI行业竞争激烈,朱啸虎建议创业公司积极拥抱生成式AI,不拥抱AI的企业肯定会被淘汰,但也不要迷信Al,聚焦尖刀场景尽快落地,同时也考虑尽快出海。
目前,OpenAI每周活跃用户已超过5亿,较去年12月的3亿有所增长。
有消息指,OpenAI将从明年开始通过免费用户和其他产品获得显著收入。OpenAI向部分现有及潜在投资者透露,预计到2030年前后,其智能体(AI agents)及其他新产品的合计销售额将超越ChatGPT这款热门聊天机器人。根据预测,2029年OpenAI总营收将达到1250亿美元(约合人民币9120亿元),2030年更将攀升至1740亿美元(约合1.27万亿元)。
研究公司LightShed Partners的联合创始人兼分析师Rich Greenfield表示:“广告商一直追随用户的眼球,如果OpenAI能获得大量用户使用时间,广告商将争相入驻。”
据高成投资创始合伙人洪婧透露,全球百亿美元估值的ToB软件企业中,中国企业仅占4%。意味着中国AI软件的商业化距离OpenAI依然有较大距离。
“星辰大海最后都是红海,脏活累活最后才是护城河。”朱啸虎称。
(文:钛媒体AGI)