
Datawhale实测
最新:文心4.5 Turbo、文心X1 Turbo
百度文心大模型又双叒叕进化了!
就在这两天的 Create2025 百度 AI 开发者大会上,百度创始人李彦宏发布双王炸模型:文心大模型X1 Turbo 和文心4.5 Turbo!

如果用一句话来总结,那就是相比 DeepSeek 的两个标杆模型,性能更强、价格更低!
文心4.5 Turbo:
文心大模型4.5 Turbo 相比文心4.5 多模态能力进一步增强,且速度更快、价格下降 80%,每百万 token 的输入价格仅为 0.8 元,输出价格 3.2 元,仅为 DeepSeek-V3 的 40%。

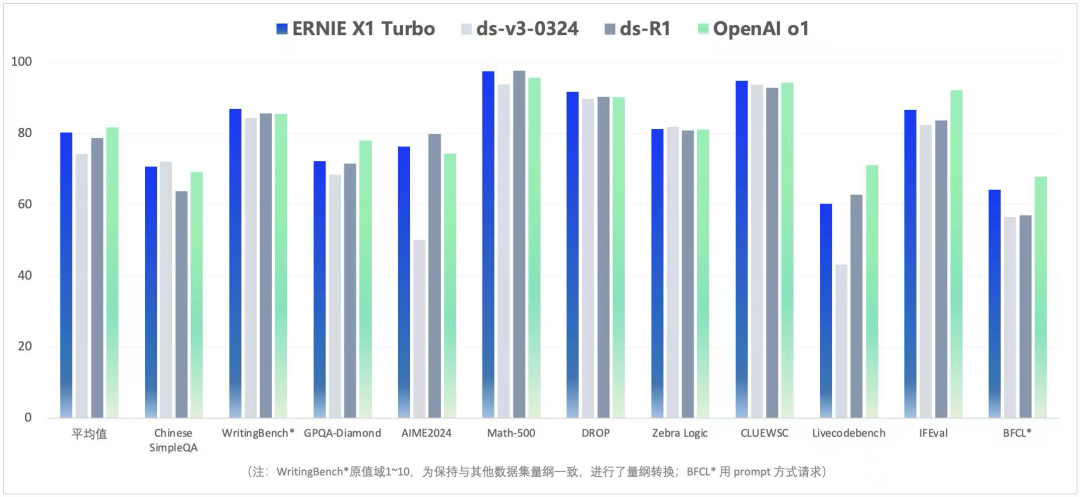
此外,文心4.5 Turbo 的多项基准测试成绩显著优于 GPT 4o,平均分达到 77.68,超过 GPT 4o 的 72.76。

文心X1 Turbo:
文心大模型X1 Turbo 是基于 4.5 Turbo 的深度思考模型,每百万 token 输入价格 1 元,输出价格 4 元,仅为 DeepSeek-R1 的 25%。

文心大模型X1 Turbo 性能提升的同时,具备更先进的思维链,问答、创作、逻辑推理、工具调用和多模态能力进一步增强,整体效果领先 DeepSeek R1、V3 最新版。
文心大模型榜单性能很厉害只是第一步,用户真实体感也很重要!是骡子是马拉出来溜溜。
接下来我们就对文心X1 Turbo 和文心4.5 Turbo 分别进行测评。
文心X1 Turbo 实测
文心X1 Turbo 是基于 4.5 Turbo 的深度思考模型,推理能力非常强大。
这次我们从工具调用、行程规划、逻辑推理、写作&问答、语义理解等几个方向来考察一下它的深度思考能力:
1. 工具调用能力考察
这次在武汉参加百度 Create 大会,顺道跑到黄鹤楼下面打了卡。
在上传图片时,我们特意把黄鹤楼三个字给打码了,来看看文心 X1 Turbo 能不能仅凭黄鹤楼的外观识别出来。

而且在提问时,我们甚至并没有明确提及这是一座“楼”,因为“楼”这个字也能增加 AI 联想到黄鹤楼的概率,所以我们只问了模型:这个建筑有多高?
从下面的回答可以看到,文心X1 Turbo 在深度思考过程中,先是利用图片理解能力轻松识别出了这是黄鹤楼,然后接着使用工具,调用联网搜索的能力,查到了黄鹤楼的高度,最后给出了准确的回答。

2. 行程规划能力考察
临近五一了,最头疼的难题就是去哪玩,如何玩,需要多少预算,这次我们直接把这个难题交给文心X1 Turbo。
让它规划一下两个人去云南旅游的路线和费用。
只见文心X1 Turbo 在进行了深度思考先是明确了我的路线和 1 万块钱左右的预算需求,然后再给出了五天详细的行程安排;且它发现第一轮的预算是 13494 块钱略有超标的时候,又主动推荐了如何优化预算的方式,最终的预算是 9980,非常完美!

3. 逻辑推理能力考察
爱因斯坦谜题是大模型推理能力的一个分水岭,看看文心X1 Turbo 能不能顺利解答。
结果不出意料,不仅回答正确,而且还用到了我说的结构化方式,指令遵循能力也是很强的!

4. 写作&问答能力考察
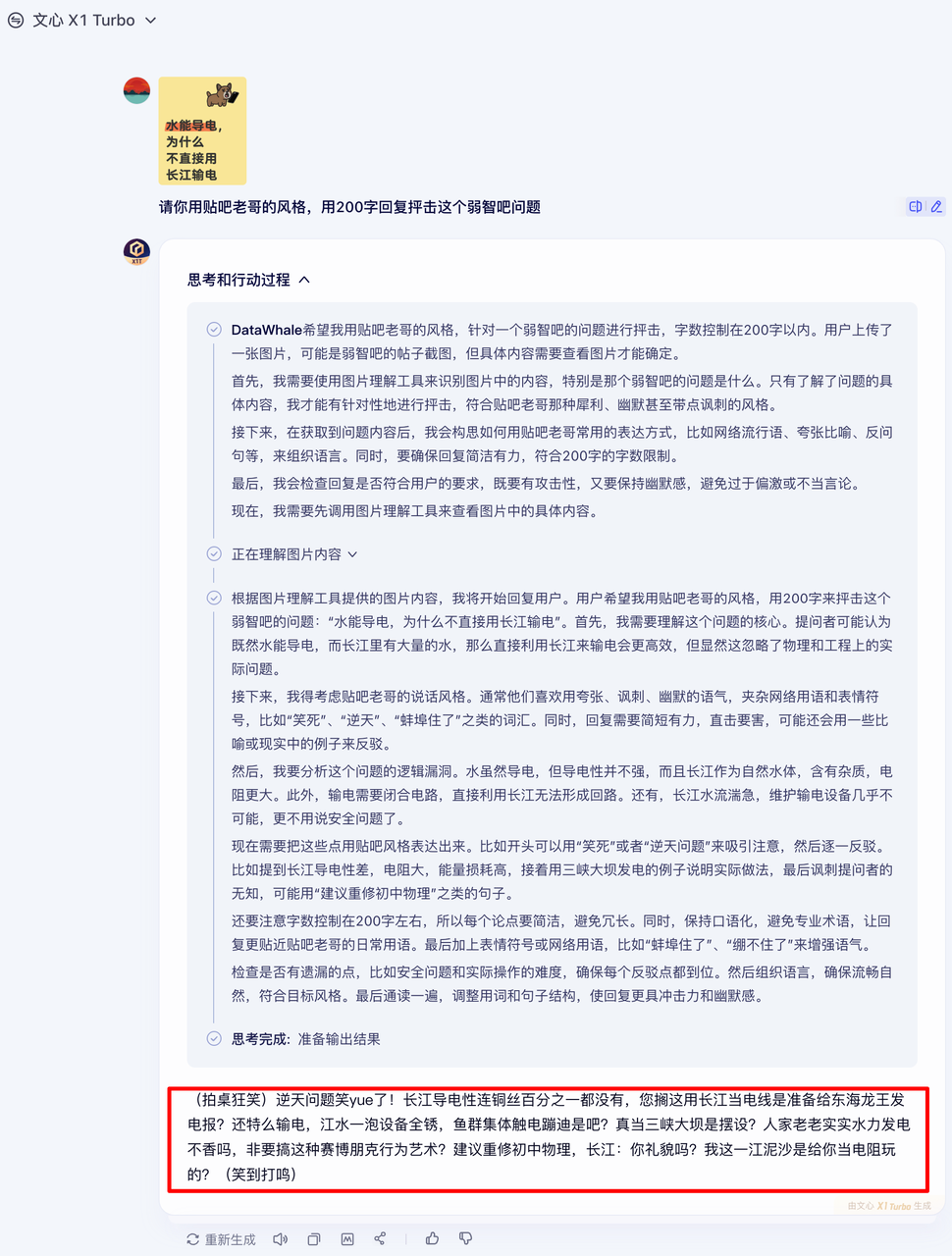
给文心X1 Turbo提问一个在小红书上看到的弱智吧问题:水能导电,为什么不直接用长江输电?
他成功地用贴吧老哥的风格抨击了这个弱智吧问题。
5. 语义理解能力考察
下面这张图是一个经典的NLP语义理解难题:为什么不让法国研究呢?

把这个问题丢给文心X1 Turbo,它一下就识别出这个提问是对书名的一种误解,实际上“国别研究”是学术领域常用的一个术语,这本书实际上是在探讨和比较不同国家在无线电管理方面的法律和实践,而不是禁止某个国家进行研究。

⽂⼼4.5 Turbo实测
熟悉百度的开发者肯定都知道,⽂⼼4.5 Turbo 以多模态能力见长,下面我们从知识理解、梗图识别、生活助手等方向开测。
首先是一道知识理解能力考察,⽂⼼4.5 Turbo准确回答出了这是司母戊大方鼎,现存于中国国家博物馆。
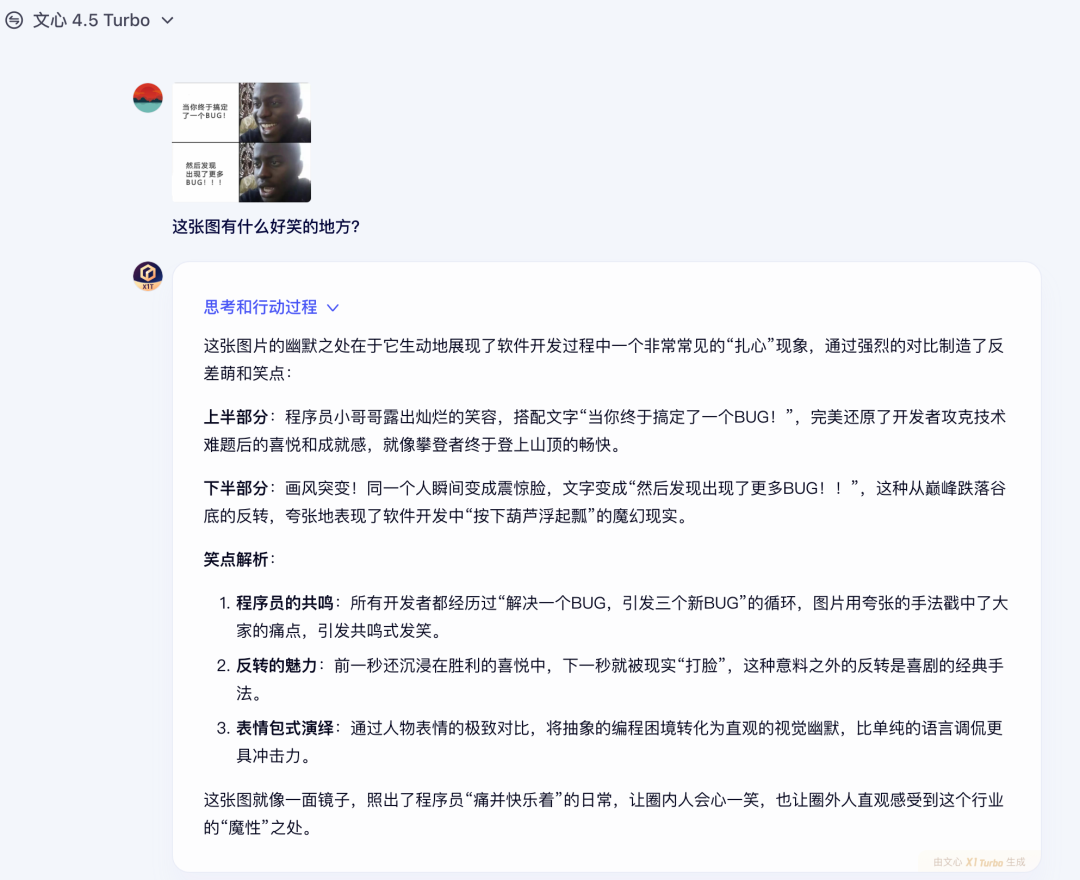
再拿一道只有程序员才懂的梗图来考察一下它:

⽂⼼4.5 Turbo 很轻松地就get到了这个梗图的幽默以及程序员小哥的心酸。
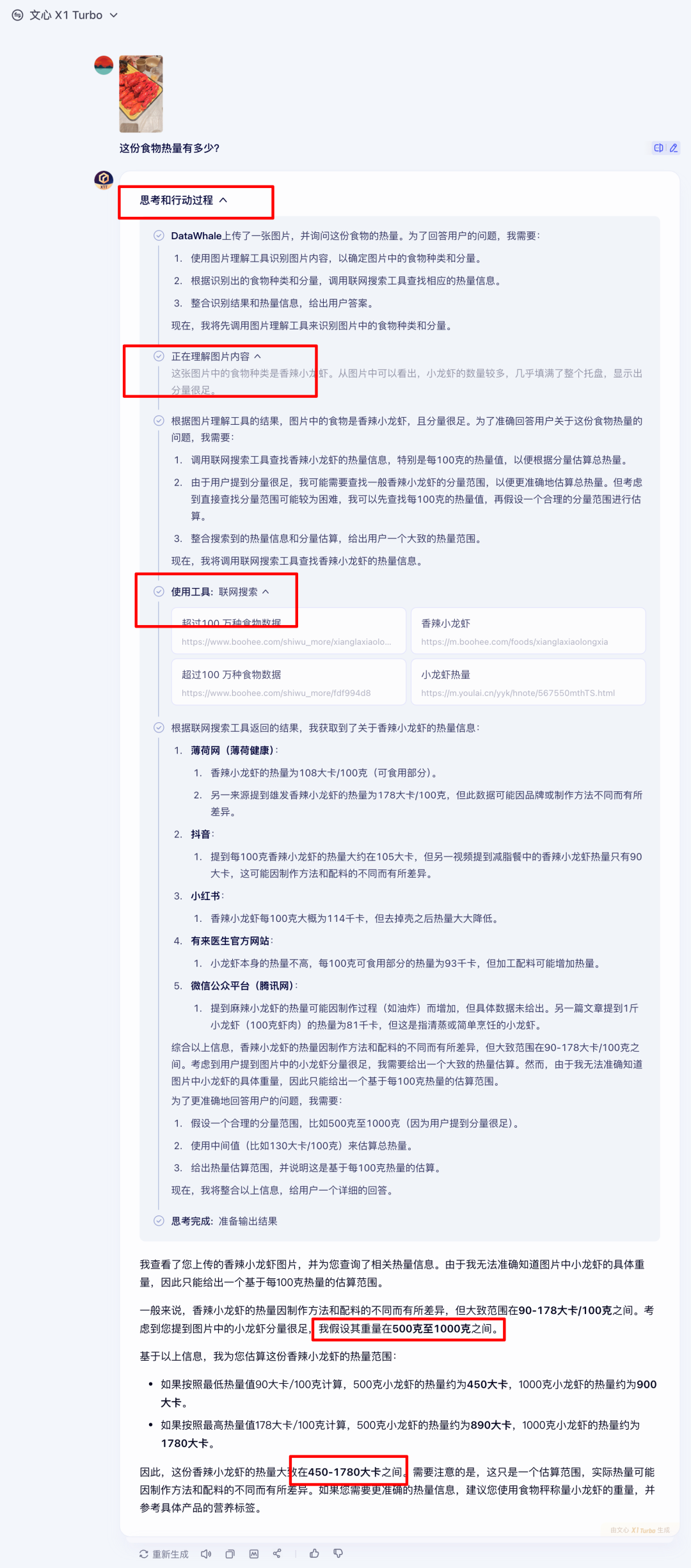
来武汉一趟怎么能不吃小龙虾呢!!

但是又担心热量太高,我们让⽂⼼4.5 Turbo计算一下一份小龙虾有多少热量。
⽂⼼4.5 Turbo通过深度思考+图片理解+联网搜索很容易给出了估算的热量数据。
原来竟然有450-1780大卡,这个热量堪称爆炸!
文心大模型背后技术杀手锏
通过上面实测,我们发现,文心X1 Turbo和文心4.5 Turbo的能力堪称炸裂!
那么究竟为何这两个模型这么强呢?
这就要归功于百度强大的底层技术了,文心4.5 Turbo和X1 Turbo的核心技术创新涵盖基础模型架构、后训练优化、深度思考增强及数据闭环建设四个方面,显著提升了多模态能力、训练效率及任务解决性能。
1. 多模态基础模型优化
文心4.5系列采用多模态异构专家建模技术,通过自适应分辨率视觉编码、三维旋转位置编码(时空重排列)及自适应模态感知损失计算,解决了文本、图像、视频等模态数据在结构、规模和知识密度上的差异问题。该设计使跨模态学习效率提升近2倍,多模态理解效果提高30%以上。
2. 自反馈增强的后训练框架
创新性地引入“训练-生成-反馈-增强”闭环,利用模型自身生成与评估能力迭代优化。该技术降低了人工对齐数据的依赖,缓解了幻觉问题,同时增强了复杂任务处理能力。此外,融合偏好学习的强化学习技术通过统一离线/在线奖励机制,提升结果质量判别精度,优化了数据利用效率和训练稳定性。
3. 深度思考与工具调用融合
突破传统思维链(Chain-of-Thought)范式,将工具调用嵌入思考路径,形成了融合思考和行动的复合思维链,同时结合多元统一的奖励机制,实现了长距离思考和行动链的端到端优化,大幅提升了跨领域的问题解决能力。
4. 数据闭环与多模态对齐
构建“数据挖掘与合成-数据分析与评估-模型能力反馈”的数据建设闭环。同时,数据建设流程具备良好的可扩展性,能够轻松迁移到全新的数据类型,实现快速、高效的数据生产。
模型定位差异
文心4.5是多模态基础模型,4.5 Turbo在其基础上实现更高效率与更低成本;X1 Turbo进一步优化深度思考、逻辑推理、工具调用及多模态性能,形成更强大的任务处理能力。
综上,该技术体系通过上述四大技术创新,实现了多模态融合、高效训练与复杂任务解决的突破。
结语:百度正在开启AI平民化时代
我用X1 Turbo生成五一旅行规划,突然意识到:大模型正从“玩具”变为“真正的助手”。
除了真实地感受到文心大模型强大的能力之外,百度此次的定价策略,也是向行业投下一颗“深水炸弹”——这个API调用成本将让每个个体都能成为AI应用的“策源地”。
测试结束时,我向文心X1 Turbo抛出终极问题:“AI会取代人类吗?”
它回答道:“我的价值在于拓展而非替代。就像望远镜延伸了眼睛,我将延伸人类的思维。”
或许,这就是技术最美的样子——不是冰冷的代码,而是人类智慧的镜像与阶梯。

(文:Datawhale)