
UniME团队 投稿
量子位 | 公众号 QbitAI
告别CLIP痛点,更懂语义关联的跨模态理解新SOTA来了!
格灵深瞳、阿里ModelScope团队,以及通义实验室机器智能团队联合发布通用多模态嵌入新框架UniME,一经推出就刷新MMEB训练榜纪录。

△图片于2025年5月6日08:00 UTC+8截取
UniME作为一个创新性的两阶段框架,所展现的卓越的组合理解力,帮助MLLMs具备学习适用于各种下游任务的判别性表征的能力,并在多个任务中达到了新的SOTA。
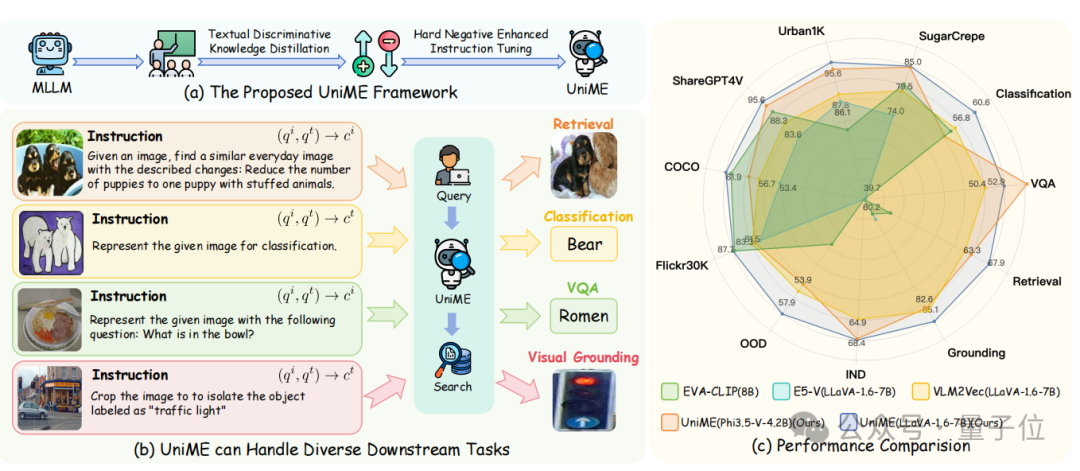
目前,该项目已开源,可点击文末链接一键获取~

以下是UniME的更多相关细节。
UniME训练框架拆解
第一阶段:文本判别知识蒸馏
- 训练
受E5V等之前研究的启发,研究团队第一阶段选择使用纯文本数据来增强了MLLM中LLM语言组件的嵌入能力。
由于LLM采用自回归解码器架构,因果掩码机制会从本质上限制了它们的判别能力。
为了解决这一限制,团队引入了如图所示的文本判别知识蒸馏。
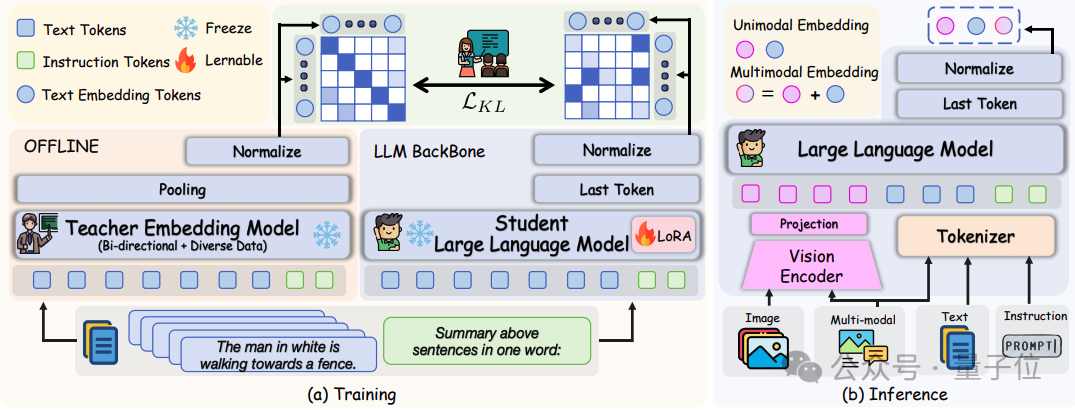
△文本判别知识蒸馏阶段的框架
从最先进的基于LLM的嵌入模型NV-Embed V2(该模型在对比训练中移除了因果注意力掩码并使用多个多样化的数据集进行训练)中转移知识。
具体来说,团队首先将LLM组件从MLLM架构中分离出来,并使用嵌入提示处理仅文本输入:“ Summary the above sentences in one word: \n”。
然后,从最终令牌的隐藏状态获得规范化的学生文本嵌入和离线提取的教师文本嵌入,其中是批量大小,是嵌入的维度。
随后,通过最小化教师模型和学生模型嵌入之间的Kullback-Leibler(KL)散度来实施判别性分布对齐:
其中是用来软化分布表示的温度超参数。
通过在一个批次内不同样本之间的关系蒸馏,该方法在相同数据和训练条件下相较于直接使用对比学习在下游任务中展示出显著的性能提升。
- 推理
在训练阶段,此方法仅使用纯文本输入,并单独优化多模态语言模型架构中的语言模型组件,同时保持其他参数不变。
在推理时,恢复原始的视觉编码器和投影层,以启用多模态处理。
对于单模态输入(文本或图像),使用特定于模态的标准化提示。
对于图文交错的输入,独立处理每种模态及其相应的提示,并通过元素级求和聚合嵌入从而得到最终的多模态表示。
第二阶段:困难负样本增强指令微调
在完成文本判别知识蒸馏截断的训练后,UniME已经具备了初步的判别能力但表现出较弱的视觉敏感性,这种不敏感导致图文对齐出现偏差,并限制了判别性能。
此外,第一阶段使用的通用指令提示限制了UniME在复杂检索任务中的效果。
为了解决这些限制,研究人员引入了一个额外的困难负例增强指令调整阶段,该阶段目的在于:
1. 进一步增强模型判别能力。
2. 改善模型跨模态对齐。
3. 加强下游任务中的指令跟随能力。
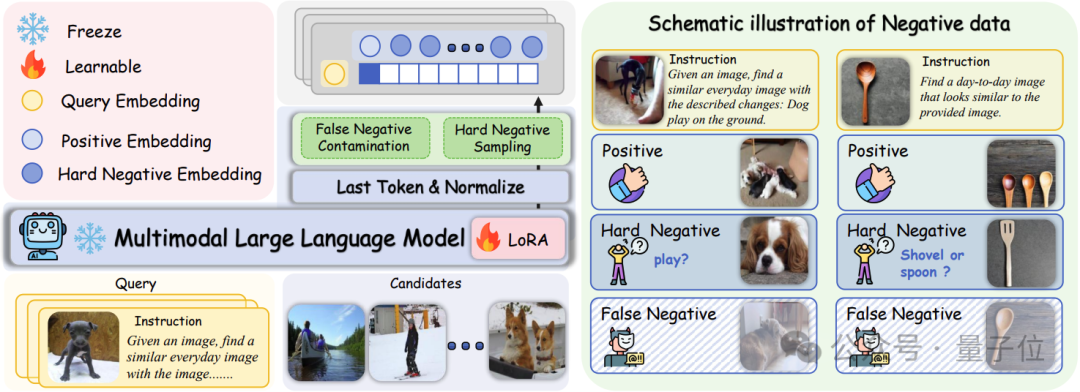
△困难负样本增强指令微调阶段的框架
- 错误负样本污染
训练批次中错误负样本的存在妨碍了在标准InfoNCE损失下有效区分困难负样本。
为了缓解这一问题,团队引入了一个基于Query和正样本相似度阈值的过滤机制,定义为:,其中是用来控制阈值边界的超参数。
在训练期间,排除所有与Query相似度超过的负样本来过滤错误负样本同时保留具有挑战性的困难负样本。
- 困难负样本采样
困难负样本在标签上与正样本不同但在向量空间中非常接近,这类具有挑战性的样本能够在对比学习过程中显著增强模型的判别能力。
相比之下,简单负样本产生的梯度微不足道,对学习过程的贡献极小。
因此团队提出一种困难负样本采样策略,旨在优化训练效率和判别性能。
由于文本判别知识蒸馏阶段之后UniME已经具备了初步的判别能力,在此能力基础上,研究人员在每个训练批次中抽样个对应的困难负样本,如下所示:
其中和分别表示经过筛选的错误负样本候选和正样本候选,是查询嵌入,表示所有候选嵌入,函数计算成对相似度得分,选择得分最高的前个候选作为困难负例。
- 训练目标
在获取了查询的嵌入()、正样本候选()和困难负样本候选()后,我们使用噪声对比估计(InfoNCE)损失对批次内采样的困难负样本进行如下处理:
其中表示所有困难负例的集合,是一个温度超参数。
训练食谱
- 第一阶段:文本判别知识蒸馏
团队采用QLoRA对大型语言模型组件进行参数高效的微调。
这一阶段仅使用纯文本输入并仅训练极少的参数(通常不超过总数的5%),完整训练Phi3.5-V和LLaVA-1.6分别需要大约1小时和2小时。
- 第二阶段:困难负样本增强指令微调
为了克服较大批量MLLM训练时的GPU内存限制,研究人员采用了两种策略:
-
参照VLM2Vec,使用了GradCache梯度缓存技术将对比损失计算和编码器更新的反向传播分离; -
采用QLoRA对MLLM内所有参数进行参数高效的微调。
将这两种策略进行组合有效地促进了训练效率同时显著降低训练时的内存开销。
实战性能全验证
训练数据
研究人员在第一阶段的文本判别知识蒸馏中使用了Natural Language Inference(NLI)数据集,该数据集包含约273k个句子对。
对于困难负例增强指令调优阶段,使用了MMEB基准提供的训练数据集,涵盖了四个核心多模态任务:分类、视觉问答、多模态检索和视觉定位。
这一全面的训练语料库,结合了单模态和多模态输入数据,共计662k经过精心策划的训练对,确保了模型在多样化的多模态任务中的稳健适应。
下游评测
团队评估了MMEB中的分布内(20个测试集)和分布外(16个测试集)基准,以评估UniME在多样化检索任务中的多模态嵌入能力。
为了进一步检验UniME的单模态嵌入性能,研究人员在多个跨模态检索任务上进行了实验,包括短标题图文检索(Flickr30K和COCO2014),长标题图文检索(ShareGPT4V和Urban1K),以及组合式检索(SugarCrepe)。
实验结果
- 多模态检索
在表1中,展示了UniME与现有基线模型的性能对比,其中IND代表分布内数据集,OOD代表分布外数据集,报告的分数是相应数据集上平均精确度,最佳结果用粗体标出,†表示仅文本判别蒸馏的UniME,‡表示文本判别蒸馏和困难负样本增强指令调优的UniME。
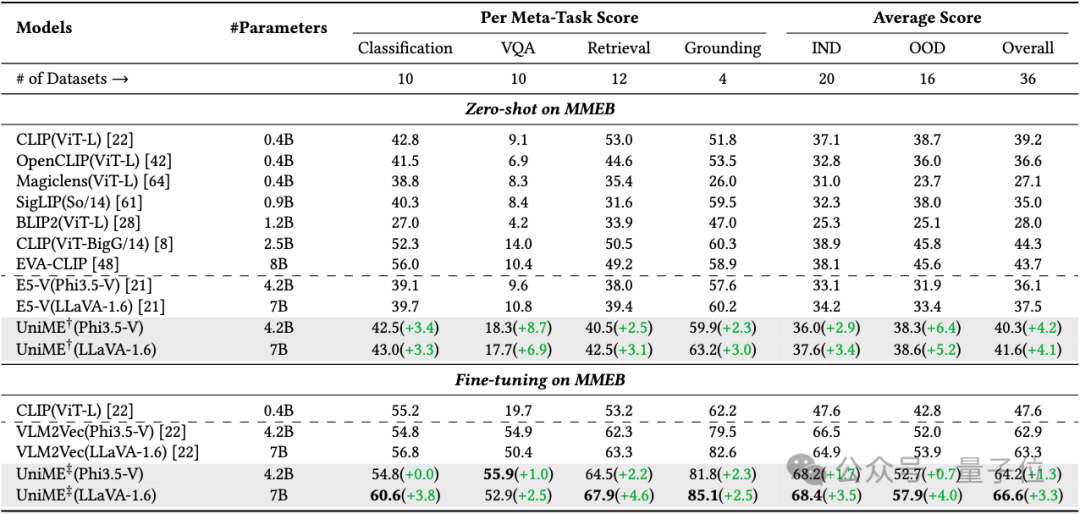
△表1:MMEB基准测试结果
在相同的训练数据和配置设置下,UniME相比E5-V在不同的基础模型上始终展示出显著的性能提升。
使用Phi3.5-V模型时,UniME的平均性能提高了4.2%;采用LLaVA-1.6作为基础模型时,UniME的平均性能进一步提高了4.1%。
这些显著的性能提升主要归功于团队提出的文本判别知识蒸馏方法可以更有效地增强MLLM中LLM语言组件的判别能力。
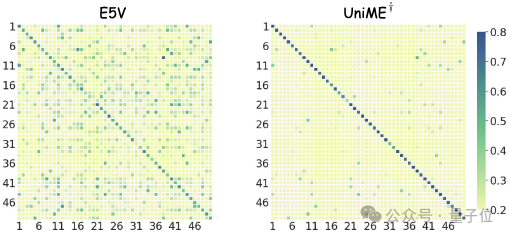
如图所示,团队随机从COCO中选择50个样本,并可视化跨模态余弦相似度矩阵。
与E5-V相比,UniME矩阵的对角线清晰度显著增强,表明UniME学习到了更具判别性的表征。
在困难负样本增强指令微调之后,UniME的嵌入判别能力进一步提高。
与VLM2Vec相比,UniME在Phi3.5-V和LLaVA-1.6基础模型上分别实现了1.3%和10.3%的性能提升。
- 短-长标题跨模态检索
如表2所示,团队在零样本跨模态检索任务上评估了UniME。
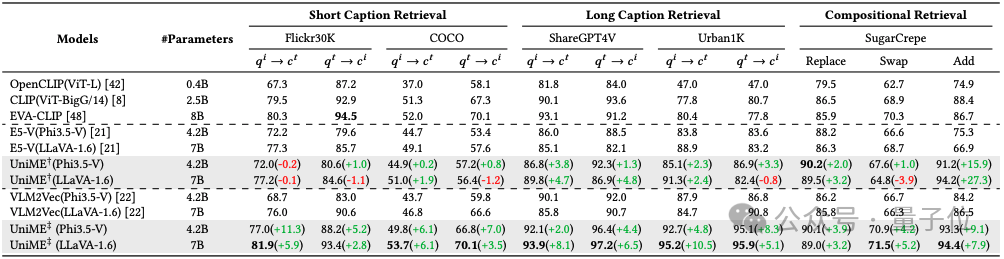
△表2:零样本文本-图像检索的结果
首先,在短标题数据集Flickr30K和MSCOCO上进行实验。
在文本判别知识蒸馏阶段之后,UniME的检索性能与E5-V相当。
随后的困难负例增强指令调优进一步提升了UniME的表现,相较于VLM2Vec提高了5.2%-11.3%。
对于在ShareGPT4V和Urban1K数据集上的长标题检索任务,UniME在所有指标上均表现出优越性能。
在文本判别蒸馏阶段后,基于Phi3.5-V模型UniME展示了1.3%-3.8%的性能提升。
随后通过困难负例增强指令调优的进一步增强,UniME相较于VLM2Vec提高了2.0%-8.3%。
值得注意的是,与EVA-CLIP(8B)相比,UniME在Urban1K数据集上的长标题检索中,性能提升了14.8%和18.1%。
这一显著增强主要源于EVA-CLIP(8B)受77文本输入令牌长度的限制,从而严重阻碍了其传达长标题完整语义信息的能力。
- 跨模态组合检索
团队在组合理解基准SugarCrepe上评估了UniME模型区分困难负样本的能力。
如表2所示,UniME在所有评估指标上均展示出最佳结果。
在文本判别知识蒸馏后,基于Phi3.5-V的UniME在关系替换、对象交换和属性添加任务中分别比E5-V表现出2.0%、1.0%和15.9%的性能提升。
在第二阶段困难负例增强指令微调后,UniME的组合理解能力得到进一步增强,与VLM2Vec相比分别实现了3.9%、4.2%和9.1%的性能提升。
此外,与EVA-CLIP(8B)相比,UniME在这些任务上也显示出了4.2%、0.6%和6.6%的提升,凸显了其在区分困难负例方面的强大能力。
消融实验
- 困难负样本分析
在下图中,展示了三种类型负样本的训练损失和裁剪前梯度范数:简单负样本(批次中最不相似的样本),随机负样本(批次中随机采样的负样本),以及困难负样本(在移除正例和假负例后批次中最相似的负样本)。
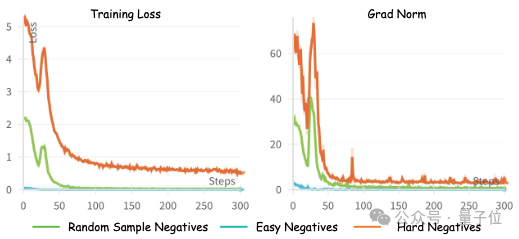
由于就简单负样本容易区分,模型通过学习这类数据很难增强其判别能力,因此训练损失迅速收敛到接近零。
使用随机负样本,训练损失比简单负样本收敛更慢,但最终接近零。
相比之下,困难负样本带来更大的挑战,使得训练损失始终保持在较高水平。
相应地,简单负样本的梯度范数最小,而困难负样本的梯度范数明显更高,相差数个数量级。
- 训练阶段的消融
团队基于Phi3.5-V来对不同训练阶段进行了消融研究。
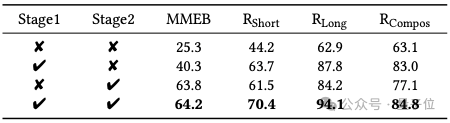
△表3:不同训练阶段的消融研究
如表3所示,Phi3.5-V的初始嵌入判别能力很弱。
在经过文本判别知识蒸馏后,模型在MMEB基准、短长标题跨模态检索和组合检索任务上分别获得了15%、19.5%、24.9%和19.9%的性能提升。
如果仅进行第二阶段负样本增强指令微调,同一任务的性能提升分别为38.5%、17.3%、21.3%和14.0%。
值得注意的是,第二阶段在MMEB基准的性能提升明显超过第一阶段,主要是由于模型在遵循下游任务复杂指令方面的能力得到了改善。
通过整合两个训练阶段,UniME模型在所有评估的下游任务中实现了最佳性能。
- 输出分布的可视化
为了进一步探索UniME嵌入捕获的语义表达,使用此提示“<Image> Summary above image in one word: \n”,并在下图中展示了不同训练阶段之前和之后,top-k下一个预测词汇的预测概率。

团队观察到,在训练之前,预测的词汇更抽象,如“Pastoral”和“Peaceful”。
经过文本判别知识蒸馏后,词汇转向更具体的语义,包括“cow”、“waterfront”和“house”,尽管概率分布仍主要集中在“Farm”。
在第二阶段困难负样本增强指令微调后,概率分布在与图像语义一致的多个词汇上变得更加均匀,从而使嵌入能够更准确地表达图像的语义内容,并增强其判别能力。
论文链接:https://arxiv.org/pdf/2504.17432
代码链接:https://github.com/deepglint/UniME
项目链接:https://garygutc.github.io/UniME
模型链接:https://huggingface.co/DeepGlint-AI/UniME-LLaVA-OneVision-7B
魔搭社区:https://www.modelscope.cn/models/deepglint/UniME
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
(文:量子位)