



Main Conference
论文介绍
论文题目:Towards Effective and Efficient Continual Pre-training of Large Language Models
作者:陈杰,陈志朋,王家鹏,周昆,朱余韬,蒋锦昊,闵映乾,赵鑫,窦志成,毛佳昕,林衍凯,宋睿华,徐君,陈旭,严睿,魏哲巍,胡迪,黄文炳,文继荣
通讯作者:赵鑫
论文概述:本研究通过继续预训练显著增强了Llama-3的中文语言能力和科学推理能力。为了在增强新能力的同时保持原有能力,我们设计了特定的数据混合和数据课程策略,并利用现有数据合成高质量数据集。我们将预训练后的模型命名为Llama-3-SynE。此外,我们还进行了相对较小模型——TinyLlama的调优实验,并将得出的结论用于对Llama-3的继续预训练。我们在十五项评估基准上多维度测试了Llama-3-SynE的性能,结果表明我们的方法在不损害原有能力的情况下,大大提高了Llama-3的性能。包括通用能力(C-Eval 提升了 8.81,CMMLU 提升了 6.31)和科学推理能力(MATH 提升了 12.00,SciEval 提升了 4.13)。
论文介绍
论文题目:GUICourse: From General Vision Language Model to Versatile GUI Agent
作者:陈文通*,崔竣博*,胡锦毅*,秦禹嘉,方俊杰,赵越,王崇屹,刘俊,陈桂荣,霍宇鹏,姚远,林衍凯,刘知远,孙茂松
通讯作者:姚远,林衍凯
论文概述:利用图形用户界面(GUI)进行人机交互是使用各类数字工具的关键途径。近期视觉语言模型(VLM)的突破性进展表明,这类模型具备开发多功能智能体的巨大潜力,可协助人类操作GUI界面。然而当前VLM在基础能力(如文字识别与视觉定位)方面仍存在不足,同时缺乏对GUI元素功能及控制方法的认知,这些局限阻碍了其成为实用的GUI操作智能体。为解决这些问题,我们推出GUICourse系列数据集,用于基于通用VLM训练视觉GUI智能体:首先通过GUIEnv数据集增强VLM的文字识别与视觉定位能力;继而利用GUIAct和GUIChat数据集扩展其对GUI的专业知识。实验表明,即便是小型GUI智能体(3.1B)也能在单步和多步GUI任务中表现优异。我们进一步将智能体微调应用于不同动作空间的其他GUI任务(AITW和Mind2Web),结果显示其性能均优于基线VLM模型。此外,通过消融实验我们验证了文字识别与视觉定位能力与GUI导航效能呈正相关。
论文介绍
论文题目:DNASpeech: A Contextualized and Situated Text-to-Speech Dataset with Dialogues, Narratives and Actions
作者:程传奇,孙宏达,杜博,商烁,胡新荣,严睿
通讯作者:严睿
论文概述:本文提出情境化文本转语音(CS-TTS)这一创新任务,通过结合对话(Dialogues)、叙述(Narratives)与动作描写(Actions)实现更精准、可定制的语音生成。虽然基于提示的TTS方法已能实现可控语音合成,但现有数据集普遍缺乏与语音数据匹配的情境描述性提示。针对这一数据短缺问题,我们开发了自动化标注流程,实现语音片段、文本内容及其情境描述的多维度对齐。基于该流程,我们构建了DNASpeech数据集——首个包含DNA提示标注的高质量CS-TTS数据集,涵盖2,395个独特角色、4,452个场景和22,975条对话语句,以及超过18小时的高质量语音数据。为适应更细分的任务场景,我们建立了包含两项新型子任务的评估体系:基于叙述的CS-TTS和基于对话的CS-TTS。同时设计了一种直观的基线模型,用于与现有前沿TTS方法在评估体系中进行对比。全面实验结果表明,DNASpeech在质量与效用方面表现卓越。
论文介绍
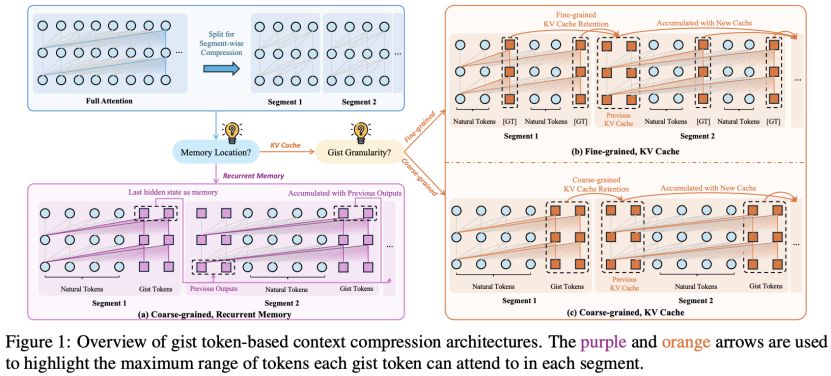
论文题目:A Silver Bullet or a Compromise for Full Attention? A Comprehensive Study of Gist Token-based Context Compression
作者:邓琛龙,张智松,毛科龙,李帅谊,黄昕庭,俞栋,窦志成
通讯作者:张智松,窦志成
论文概述:在这项工作中,我们对基于gist token的上下文压缩方法进行了实证研究,以改进大型语言模型中的上下文处理。我们重点关注两个关键问题:(1)这些方法在多大程度上能够替代全注意力模型?(2)由于压缩会产生哪些潜在的失败模式?通过大量实验,我们表明,尽管基于要点的压缩在检索增强生成和长文档问答等任务上仅造成轻微的性能损失,但在合成召回等任务上却面临挑战。此外,我们还确定了三种关键的失败模式:边界丢失、意外丢失和途中丢失。为了缓解这些问题,我们提出了两种有效的策略:细粒度自动编码,它增强了原始标记信息的重建;以及分段标记重要性估计,它根据标记依赖关系调整优化。我们的工作为理解基于gist token的上下文压缩提供了有价值的见解,并提供了提高压缩能力的实用策略。
论文介绍
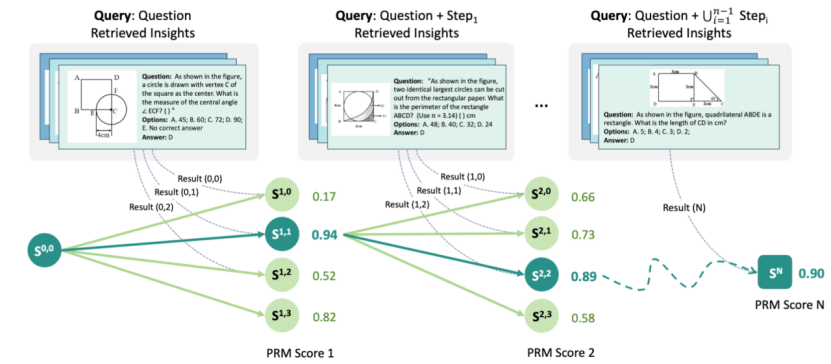
论文题目:Progressive Multimodal Reasoning via Active Retrieval
作者:董冠霆,张宬浩,邓梦洁,朱余韬,窦志成,文继荣
通讯作者:窦志成
论文概述:多步骤级的多模态推理任务对多模态大模型来说一直是重大的挑战,如何在该场景下找到针对性提升性能的有效方法仍是一个未解决的问题。在本文中,我们提出了 AR-MCTS,这是一种旨在通过主动检索和蒙特卡洛树搜索相结合,来逐步增强多模态大模型推理能力的通用框架。AR-MCTS遵循蒙特卡洛树搜索算法,并在该算法的扩展阶段启发式地集成主动检索机制,以自动化,动态地获取高质量的步骤级推理标注数据。基于这些高质量数据,我们进一步引入了课程训练目标以逐步对齐一个过程奖励模型,最终实现可信的多模态步骤级推理校验。在三个公开的复杂多模态推理基准上的实验结果证实了AR-MCTS 的有效性。进一步分析表明该框架能够同时优化采样空间的多样性与准确性,从进而产生可靠的多模态推理结果。
论文介绍
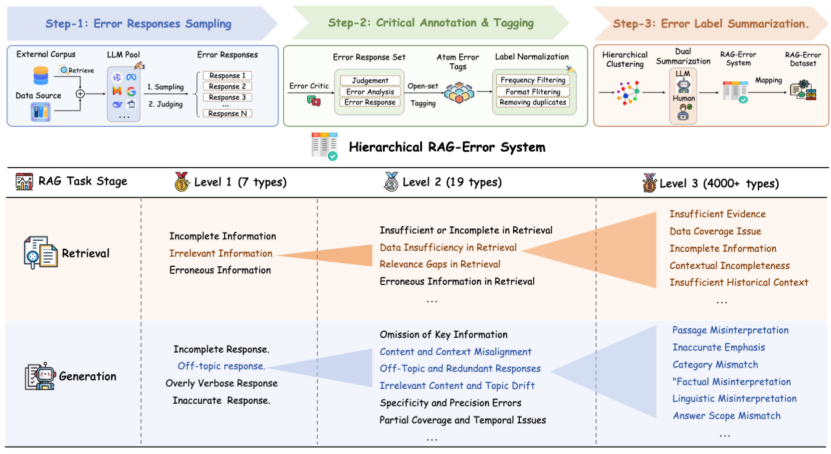
论文题目:RAG-Critic: Leveraging Automated Critic-Guided Agentic Workflow for Retrieval Augmented Generation
作者:董冠霆,金佳杰,李晓熙,朱余韬,窦志成,文继荣
通讯作者:窦志成
论文概述:检索增强生成(RAG)因其在生成事实性内容方面的有效性,已成为自然语言处理领域的关键技术。然而,其信息输入的复杂性以及范式的多样性往往导致更多样化错误的产生。因此,实现 RAG 的在线性能评估与错误驱动的自校正流程仍是待解难题。在本文中,我们提出了 RAG-Critic,通过自动评估引导的工作流来自主提升RAG 能力的框架。具体而言,我们首先引入了一个底层数据驱动,顶层人为总结的RAG错误挖掘流程,以建立全面的错误分类系统。基于该系统,我们设计由粗到细的训练目标来逐步对齐一个RAG错误评估模型,该模型可自动提供细粒度的错误反馈。最后,我们提出了一个错误驱动的RAG自我纠正工作流,该工作流根据错误评价模型的反馈,自主定制出错误纠正方案流程的代码,通过运行代码来自动化完成RAG的错误自纠正。在七个 RAG 相关数据集上的实验结果证实了 RAG-Critic 的有效性,进一步的定性分析则为实现可靠的RAG 系统提供了实际见解。
论文介绍
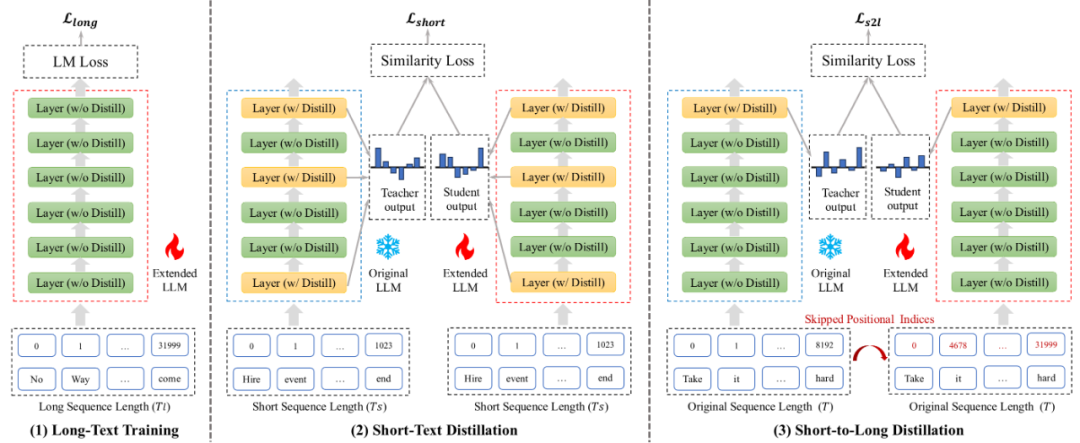
论文题目:LongReD: Mitigating Short-Text Degradation of Long-Context Large Language Models via Restoration Distillation
作者:董梓灿,李军毅,蒋锦昊,徐名宇,赵鑫,王炳宁,陈炜鹏
通讯作者:赵鑫
论文概述:大语言模型通过扩展位置编码和轻量级继续预训练获得了更长的上下文窗口。然而,这往往导致模型在短文本任务上的性能下降,而当前对这种性能下降的原因探究尚不充分。在本研究中,我们确定了导致该问题的两个主要因素:隐藏状态和注意力分数的分布偏移,以及持续预训练过程中的灾难性遗忘。为解决这些挑战,我们提出了基于恢复蒸馏的长上下文预训练方法(LongReD),一种通过最小化长文本模型与原始模型之间的分布差异来缓解短文本性能下降的方法。除了在长文本上进行训练外,LongReD 还从原始模型中提取选定层对短文本上的隐藏状态进行蒸馏。此外,LongReD 还引入了短到长蒸馏机制,通过利用跳跃位置索引,使模型在短文本上的输出分布与长文本上的输出分布保持一致。在常见文本基准上的实验表明,LongReD 在保持模型处理长文本能力的同时,有效保留了其在短文本任务上的性能。
论文介绍
论文题目:YuLan-Mini: Pushing the Limits of Open Data-efficient Language Model
作者:胡译文、宋华彤、陈杰、邓佳、王家鹏、周昆、朱余韬、蒋锦昊、董梓灿、陆洋、缪旭、赵鑫、文继荣
通讯作者:赵鑫
论文概述:由于大型语言模型(LLMs)的预训练需要极高的资源投入和复杂的技术手段,实现具备先进性能的预训练仍面临诸多挑战。本文针对预训练过程中存在的关键瓶颈与设计难点进行了探索,并做出以下贡献:1. 全面分析导致训练不稳定的因素;2. 提出一种稳健的优化方法,有效缓解训练不稳定问题;3. 构建了一套精细的数据处理流程,融合了数据合成、数据课程与数据筛选机制。通过整合上述技术,我们设计出一套成本较低的训练方案,并基于此方案预训练了 YuLan-Mini —— 一个完全开源的基础模型,拥有 24 亿参数,训练数据量达 1.08 万亿词元。值得注意的是,YuLan-Mini 在同参数规模模型中表现优异,性能可媲美使用更多数据训练的业界领先模型。为便于复现,我们公开了完整的训练方案与数据组成。项目详情请访问以下链接:https://github.com/RUC-GSAI/YuLan-Mini
论文介绍
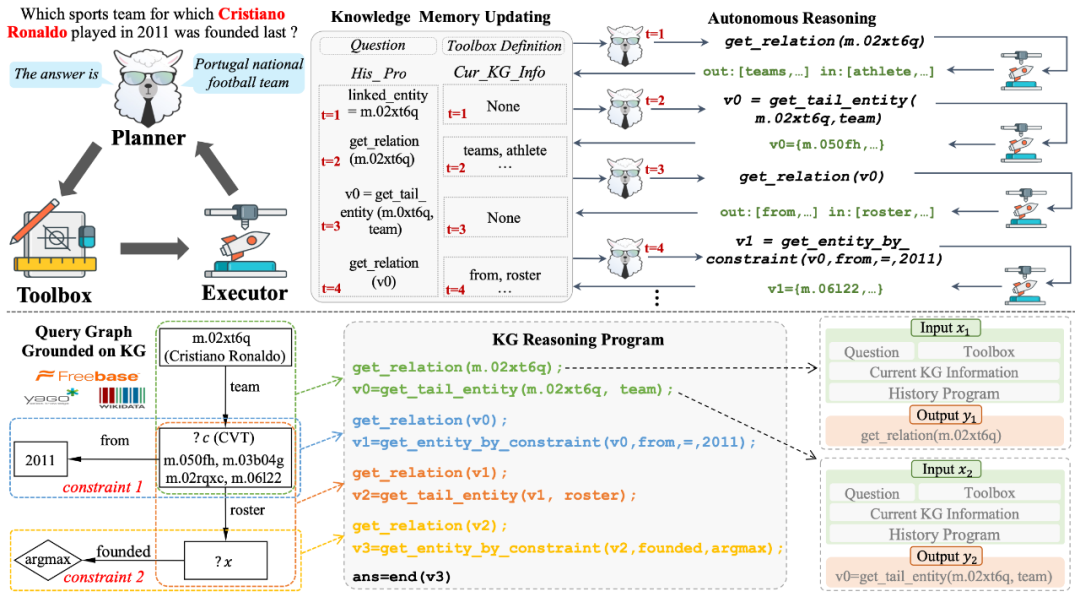
论文题目:KG-Agent: An Efficient Autonomous Agent Framework for Complex Reasoning over Knowledge Graph
作者:蒋锦昊, 周昆, 赵鑫 ,宋洋,朱琛,祝恒书,文继荣
通讯作者:赵鑫,宋洋
论文概述:在本文中,我们旨在提升大语言模型(LLMs)基于知识图谱(KGs)的推理能力,以回答复杂问题。受现有设计大语言模型与知识图谱交互策略的方法启发,我们提出了一个基于大语言模型的自主智能体框架,称为KG-Agent,它使小型大语言模型能够主动做出决策,直至完成基于知识图谱的推理过程。在KG-Agent中,我们整合了大语言模型、多功能工具箱、基于知识图谱的执行器以及知识记忆,并开发了一种迭代机制,该机制可自主选择工具,然后更新用于基于知识图谱推理的记忆。为确保有效性,我们利用编程语言来构建基于知识图谱的多跳推理过程,并合成一个基于代码的指令数据集来微调基础大语言模型。大量实验表明,仅使用10K个样本对LLaMA-7B进行微调,无论是在域内还是域外数据集上,都能超越使用更大规模大语言模型或更多数据的当前最优方法。我们的代码和数据将公开发布。
论文介绍
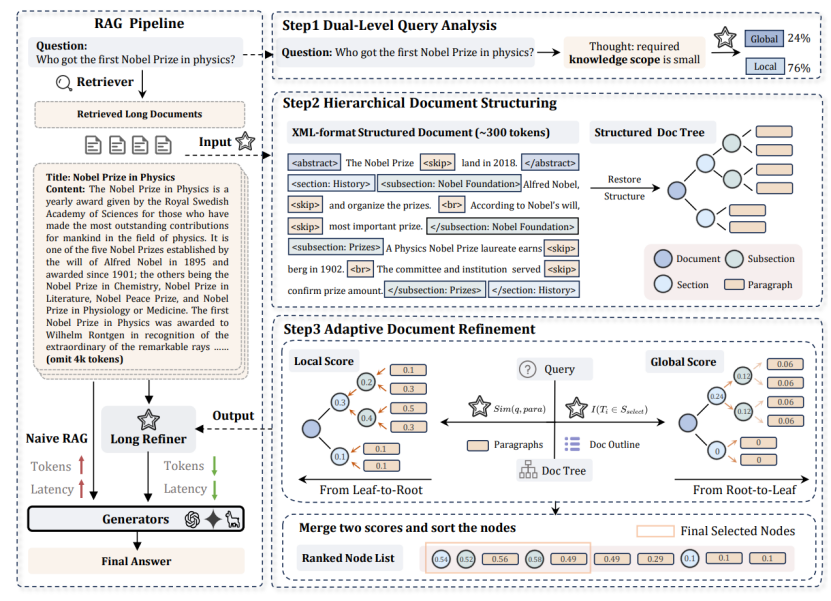
论文题目:Hierarchical Document Refinement for Long-context Retrieval-augmented Generation
作者:金佳杰,李晓熙,董冠霆,张宇尧,朱余韬,伍永康,李中华,叶琪,窦志成
通讯作者:朱余韬,窦志成
论文概述:实际场景的RAG应用通常会遇到长上下文输入的场景,在这类场景中,检索文档中的冗余信息和噪声会导致推理成本增加和性能下降。为了解决这些挑战,我们提出了LongRefiner,一种即插即用的长文本精炼器,其通过提取长文本的内在结构高效捕捉有益信息。LongRefiner基于单一基座模型进行了多任务学习,包括双层查询分析、层次化文档结构化建模等多个任务,能够对长文档进行自适应精炼。通过在七个知识密集型问答数据集上的实验,我们证明了LongRefiner在各种场景下能够实现具有竞争力的性能,同时计算成本和延迟比最优基线低10倍。进一步的分析验证了LongRefiner的可扩展性、效率和有效性。
论文介绍
论文题目:Optimal Transport-Based Token Weighting scheme for Enhanced Preference Optimization
作者:李萌,胡张广达,张海波,王希廷,曾安祥
通讯作者:王希廷,曾安祥
论文概述:直接偏好优化(Direct Preference Optimization, DPO)作为一种新兴算法,通过直接优化优选与次优选回答之间的对数似然差异,使大语言模型(LLMs)更好地对齐人类偏好。然而,现有方法对回答中的所有标记(token)赋予相同的重要性,忽略了人类在判断偏好时更关注语义上更关键的部分。这种不匹配导致了次优的偏好优化效果,因为那些无关或噪声较大的标记对 DPO 损失函数产生了过大的影响。为了解决这一问题,本文提出了基于最优传输理论的标记加权策略,以增强直接偏好优化的效果(Optimal Transport-based token weighting for Preference Optimization, OTPO)。通过强调语义上更相关的标记对,并降低相关性较低的标记的权重,本文引入了一种具备上下文感知能力的标记加权机制,从而获得更加对比鲜明的奖励差异估计。这种自适应加权机制不仅提升了奖励估计和可解释性,还能使偏好优化聚焦于回答之间更重要的差异。大量实验证实,OTPO在多个场景下均显著提升了模型的指令遵循能力。

论文介绍
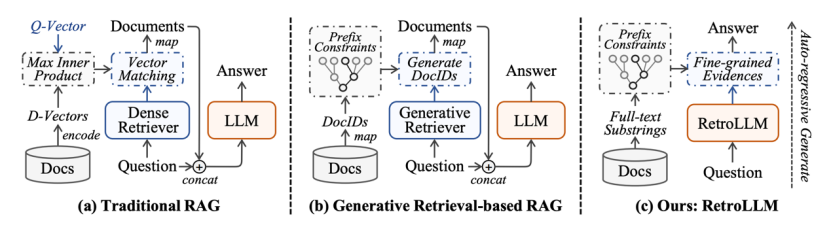
论文题目:RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
作者:李晓熙,金佳杰,周雨佳,伍永康,李中华,叶琪,窦志成
通讯作者:窦志成
论文概述:大型语言模型(llm)表现出非凡的生成能力,但往往会产生幻觉。检索增强生成(RAG)通过合并外部知识提供了一种有效的解决方案,但是现有方法仍然面临一些限制:单独检索器的额外部署成本、来自检索文本块的冗余输入令牌,以及缺乏检索和生成的联合优化。为了解决这些问题,我们提出了RetroLLM,这是一个统一的框架,将检索和生成集成到一个单一的内聚过程中,使llm能够直接从具有约束解码的语料库中生成细粒度的证据。此外,为了减少约束证据生成过程中的错误修剪,我们引入了(1)分层的FM-Index约束,该约束生成语料库约束线索,在证据生成之前识别相关文档子集,减少不相关的解码空间;(2)前瞻性约束解码策略,该策略考虑了未来序列的相关性,以提高证据准确性。在五个开放域QA数据集上进行的大量实验表明,RetroLLM在域内和域外任务上都具有卓越的性能。
论文介绍
论文题目:Do not Abstain! Identify and Solve the Uncertainty
作者:刘敬宇*,彭景权*,邬小鹏,李旭斌,葛铁铮,郑波,刘勇
通讯作者:郑波,刘勇
论文概述:大模型在面对不确定情境时常常表现出过度自信的问题。然而,目前的解决方案主要依赖于回避性回应。为了系统地研究和提升大语言模型识别与处理不确定性来源的能力,我们聚焦于三种类型的不确定性:文档稀缺、能力局限和问题歧义。通过实验发现,当前的大语言模型难以准确识别不确定性的原因并加以解决。为了解决这一问题,我们首先生成基于上下文的追问,以突出原始问题中的模糊之处;接着根据追问答案是否唯一来判断不确定性的来源;进一步地,我们采用一种on policy的学习方法——InteractDPO来生成更有效的追问。实验结果表明,我们的方法具有良好的效果。
论文介绍
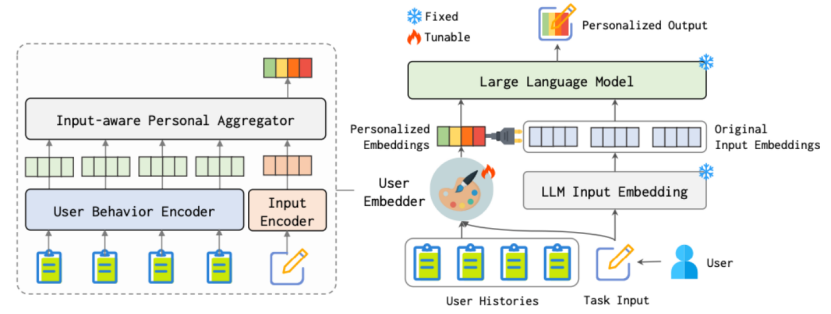
论文题目:LLMs + Persona-Plug = Personalized LLMs
作者:刘炯楠,朱余韬,王淑婷,魏骁驰,闵尔学,卢彧,王帅强,殷大伟,窦志成
通讯作者:朱余韬, 窦志成
论文概述:个性化在众多语言任务和应用中起着关键作用。为此,研究者提出了多种个性化方法,旨在使大语言模型(LLMs)能够生成符合用户偏好的定制化内容。其中一些方法通过为每个用户微调一个专属的个性化模型来实现,但这种方式成本高昂,难以大规模推广。为了解决这一问题,另一些方法采用了“即插即用”的策略,通过检索用户相关历史文本作为示例,引导模型生成个性化内容。然而,基于检索的策略可能破坏用户历史的连续性,难以充分捕捉用户的整体风格和行为模式,从而导致生成效果不佳。针对上述挑战,本文提出了一种新的个性化大语言模型方法PPlug。该方法设计了一个轻量级的用户嵌入模块,建模用户完整的历史上下文,为每位用户生成专属的嵌入表示。通过将该嵌入附加到任务输入中,LLMs无需调整自身参数即可更好地理解和捕捉用户的习惯与偏好,从而生成更具个性化的输出。在语言模型个性化基准(LaMP)中的多个任务上,实验结果表明该方法在性能上显著优于现有的个性化大语言模型方法。
论文介绍
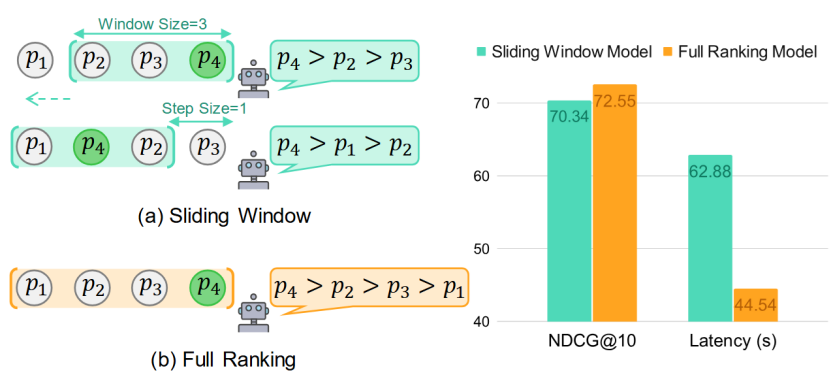
论文题目:Sliding Windows Are Not the End: Exploring Full Ranking with Long-Context Large Language Models
作者:刘文涵,马新宇,朱余韬,赵梓良,王帅强,殷大伟,窦志成
通讯作者:窦志成
论文概述:大语言模型(LLMs)在listwise文档排序任务中展现出优越的效果。 由于输入长度限制,现有方法通常采用滑动窗口策略。该策略虽有效,但效率低下——其重复且串行的处理机制会导致相关文档被多次重复评估,进而产生冗余的API开销。 随着长上下文LLMs的发展,现已能通过单次推理完成所有段落的完整排序(full ranking),从而避免冗余成本。本文针对排序任务的效率与效果,对长上下文LLMs进行了全面研究。实验发现:在监督微调场景下,长上下文LLMs的完整排序不仅能显著提升效率,更能实现更优效果。 进一步地,我们指出基于现有方法训练full reranker存在两大局限: (1) 滑动窗口策略无法生成full ranking list作为训练标签; (2) 语言建模损失函数难以强调标签中排名靠前的文档ID。 为此,我们提出一个完备的listwise标签构建方法以及一个新颖的重要性感知的优化损失函数。实验表明,该方法性能显著超越基线模型。 相关代码和模型均已开源。
论文介绍
论文题目:Towards Reward Fairness in RLHF: From a Resource Allocation Perspective
作者:欧阳晟,胡羽蓝,陈戈,李卿阳,张富峥,刘勇
通讯作者:刘勇
论文概述:在基于人类反馈的强化学习(RLHF)中,奖励机制作为人类偏好的代理发挥着关键作用。但是,如果这些奖励本身存在偏差,可能会影响大语言模型(LLMs)的对齐效果。本文将奖励中存在的各种偏差统称为”奖励不公平性问题”,并提出了一种不依赖于特定偏见的通用解决方案。具体来说,本文将偏好学习建模为资源分配问题,将奖励视为需要分配的资源,并在分配中考虑效用和公平之间的权衡。论文提出了两种方法以实现奖励的公平性。这些方法在验证和强化学习场景中应用,分别获得了公平的奖励模型和策略模型。实验结果表明该方法能够以更公平的方式实现大语言模型与人类偏好的对齐。
论文介绍
论文题目:MathFusion: Enhancing Mathematic Problem-solving of LLM through Instruction Fusion
作者:裴启智,吴郦军,盘卓实,李宇,林泓霖,明成林,高鑫,何聪辉,严睿
通讯作者:吴郦军,何聪辉,严睿
论文概述:大型语言模型 (LLM) 在数学推理方面取得了令人瞩目的进展。虽然数据增强有望提升数学问题解决能力,但目前的方法主要局限于实例级别的修改,例如问题的重新表述或生成问题变体,而这些修改无法捕捉和利用数学知识中固有的内在关系结构。受人类学习过程的启发,数学能力是通过系统地接触相互关联的概念而发展起来的。我们提出了 MathFusion,这是一个通过跨问题指令合成来增强数学推理能力的全新框架。MathFusion 通过三种融合策略来实现这一点:(1) 顺序融合,将相关问题与模型解决方案的依赖关系联系起来;(2) 并行融合,将类似问题结合起来以强化概念理解;(3) 条件融合,创建上下文感知的选择性问题以增强推理灵活性。通过应用这些策略,我们生成了一个新的数据集MathFusionQA,并在其上构建了微调模型(DeepSeekMath-7B、Mistral-7B 和 Llama3-8B)。实验结果表明,MathFusion 在保持高数据效率的同时,在数学推理方面取得了显著提升,在多个基准测试中准确率提升了 18.0 个百分点,而仅需额外添加 45,000 条合成指令,相比传统的单指令方法实现了显著提升。
论文介绍
论文题目:The Tug of War Within: Mitigating the Fairness-Privacy Conflicts in Large Language Models
作者:钱辰*,刘东瑞*,张杰,刘勇,邵婧
通讯作者:刘勇,邵婧
论文概述:确保大型语言模型(LLMs)具备公平性与隐私意识至关重要。有趣的是,我们发现了一个反直觉的权衡现象:通过监督微调(SFT)方法增强LLM的隐私意识时,即便使用数千个样本,其公平性意识也会显著下降。受信息论启发,我们提出了一种免训练的解决方案——抑制隐私与公平耦合神经元(SPIN),该方法从理论与实证层面降低了公平意识与隐私意识之间的互信息。大量实验表明,SPIN能有效消除这种权衡现象,在不损害模型通用能力的前提下,同步显著提升LLM的公平性与隐私意识(例如将Qwen-2-7B-Instruct的公平性意识提升12.2%,隐私意识提升14.0%)。更重要的是,在标注数据有限或仅能获取恶意微调数据的极端场景下,SPIN仍能保持稳健的有效性,而传统SFT方法在这些情况下可能完全失效。本研究为同步解决LLM的公平性与隐私问题提供了新思路,未来可融入综合框架以开发更符合伦理的负责任AI系统。

论文介绍
论文题目:Internal Value Alignment in Large Language Models through Controlled Value Vector Activation
作者:靳浩然,李萌,王希廷,许志豪,黄民烈,贾岩涛,连德富
通讯作者:王希廷,连德富
论文概述:大型语言模型 (LLMs) 与人类价值观的对齐正受到越来越多的关注,因为它能提供清晰度、透明度及适应未知场景的能力。本文提出一种名为 ConVA 的内部价值观对齐方法,通过定位LLMs隐层激活值空间中价值观的编码方向并修改其激活状态以实现模型的价值观对齐。我们设计了一种上下文受控的价值向量识别方法以实现精准无偏的内部价值观定位。为在不损害模型通用性能的前提下实现稳定的价值观对齐,我们引入门控式价值向量激活机制,通过求解带约束的优化问题来达成最小强度的有效价值干预。实验表明,ConVA在10项基础价值观上均取得最高控制成功率,并且不影响LLMs的原始性能与流畅度,即使在面对相反价值观提示输入时仍能确保模型遵循目标价值观。

论文介绍
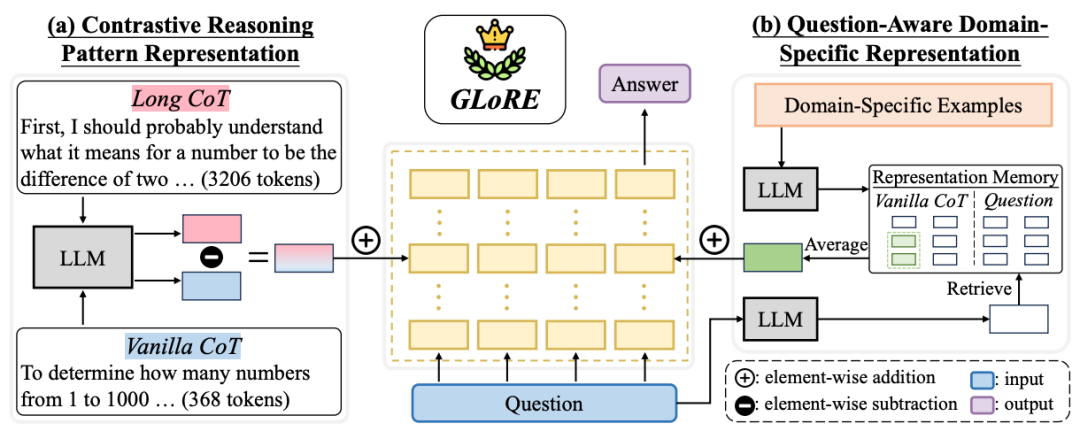
论文题目:Unlocking General Long Chain-of-Thought Reasoning Capabilities of Large Language Models via Representation Engineering
作者:汤昕宇,王晓磊,吕智昊,闵映乾,赵鑫,胡斌斌,刘子奇,张志强
通讯作者:赵鑫
论文概述:在这个工作中,我们探索如何解锁大语言模型中潜在的通用长链思考推理能力。现有研究表明,通过少量样本的微调,大语言模型可以展现出长链思考(long CoT)推理的能力,并且这种能力可以迁移到其他任务上。这引起了新的猜测:长链思考推理是否是大语言模型内在的一种通用能力,而不仅仅是在特定任务上通过训练获得的。本文首先从大模型中提取表征并发现:(1)大语言模型确实将long CoT推理编码为一种通用能力:通过可视化和定量分析,我们发现long CoT的表征集中在模型参数空间中的特定区域,并且与vanilla CoT的表征有明显区分。(2)Long CoT推理的可迁移性:不同领域(如数学、物理、化学、生物)的long CoT和vanilla CoT之间存在相似的对比表征。基于上述发现,我们提出了GLoRE,一种基于表征工程的新方法,用于解锁大语言模型通用的long CoT推理能力。实验证明了该方法在领域内(数学领域)和跨领域(物理、化学和生物领域)两种场景下的有效性、高效性与可扩展性。
论文介绍
论文题目:Investigating and Extending Homans’ Social Exchange Theory with Large Language Model based Agents
作者:王磊,张哲卿,陈旭
通讯作者:陈旭
论文概述:霍曼斯的社会交换论被广泛认为是理解人类文明和社会结构形成与出现的基本框架。在社会科学中,这一理论通常基于简单的模拟实验或真实世界的人类研究进行研究,但这两种方法要么缺乏现实性,要么成本过高难以控制。在人工智能领域,大型语言模型(LLMs)的最新进展在模拟人类行为方面展现出了令人期待的能力。受这些见解启发,我们采用跨学科研究视角,提出使用基于LLM的智能体来研究霍曼斯的社会交换理论。具体而言,我们构建了一个由三个LLM智能体组成的虚拟社会,并让它们参与社会交换实验以观察其行为。通过大量实验,我们发现霍曼斯的社会交换论在我们的智能体社会中得到了很好的验证,证明了智能体与人类行为之间的一致性。在这一基础上,我们通过改变智能体社会的设置,在传统霍曼斯社会交换论的基础上进行了扩展。
论文介绍
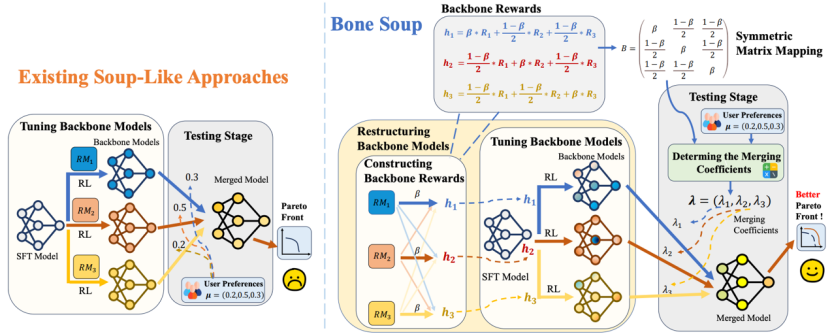
论文题目:Bone Soups: A Seek-and-Soup Model Merging Approach for Controllable Multi-Objective Generation(Main Conference)
作者:谢国富,张骁,姚婷,施云生
通讯作者:张骁
论文概述:在大语言模型(LLM)的使用中用户需求常是高度多样化且可变的,这使得如何在测试时依据用户需求快速实现“可控生成”备受关注。本文关注LLM的多目标可控生成问题,理论上分析了现有基于单目标的模型融合方法的缺陷,即:现有LLM融合忽略了多个目标间的复杂关联,导致无法到达帕累托最优性。为解决这一问题,本文提出了面向多目标可控生成的LLM模型融合方法Bone Soups。Bone Soups包含两个步骤:1.“骨干模型构建(Backbone Seeking)”通过多目标强化学习训练一系列考虑了多目标相互作用的“骨干模型”,以确保其在帕累托前沿上的最优性。2.“模型融合(Soup)”利用对称循环矩阵生成合并系数,根据用户在测试时的偏好动态融合骨干模型。实验结果表明,Bone Soups在可控多目标生成任务中展示出较强的可控性和帕累托最优性,为满足测试时用户的多样化需求提供了有效且高效的途径。
论文介绍
论文题目:AgentRM: Enhancing Agent Generalization with Reward Modeling
作者:夏宇,范静如,陈纬泽,颜思宇,从鑫,张众,卢雅西,林衍凯,刘知远,孙茂松
通讯作者:林衍凯、刘知远
论文概述:现有基于大语言模型的智能体虽然在预设任务上表现出色,但在处理未见任务时的泛化能力仍有不足。为此,近期研究通过引入更多样化的任务对策略模型进行微调以提升其泛化性。本研究发现,相比于直接微调策略模型,通过微调奖励模型来引导策略模型更具鲁棒性。基于这一发现,我们提出了AgentRM——一种可泛化的奖励模型,用于指导策略模型在测试阶段进行高效搜索。本工作系统探索了三种构建奖励模型的方法:显式奖励建模、隐式奖励建模以及基于大语言模型的自动评估。AgentRM通过Best-of-N采样和层级Beam Search机制优化答案生成。在九个智能体任务上的实验表明,AgentRM将基准策略模型的平均性能提升了8.8个百分点,超越现有最佳通用型智能体4.0个百分点。此外,使用专用策略模型时,AgentRM在预设任务上的性能比当前最专业的智能体模型再提升11.4个百分点。
论文介绍
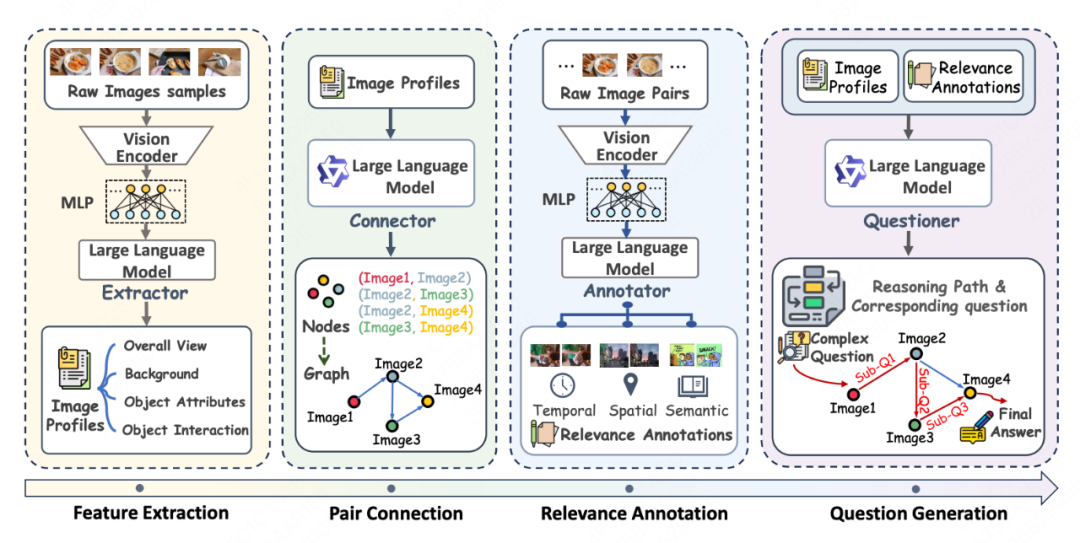
论文题目:Weaving Context Across Images: Improving Vision-Language Models through Focus-Centric Visual Chains
作者:张钧天,程传奇,刘雨涵,刘伟,栾剑,严睿
通讯作者:刘雨涵,严睿
论文概述:视觉-语言模型(VLM)在单图像任务中取得了显著成功。然而,现实世界场景通常涉及复杂的多图像输入,导致模型性能明显下降,因为模型难以从复杂的视觉特征中解析分散的关键信息。在本研究中,我们提出了聚焦式视觉链(Focus-Centric Visual Chain),这是一种新颖的范式,能够增强VLM在多图像场景中的感知、理解和推理能力。为了实现这一范式,我们提出了聚焦式数据合成(Focus-Centric Data Synthesis),这是一种可扩展的自下而上方法,用于合成具有精细推理路径的高质量数据。通过这种方法,我们构建了VISC-150K,这是一个大规模数据集,包含以聚焦式视觉链形式呈现的推理数据,专为多图像任务设计。在七个多图像基准测试上的实验结果表明,我们的方法在两种不同的模型架构上分别实现了平均3.16%和2.24%的性能提升,同时不影响通用视觉-语言能力。我们的研究使VLM向更加强大和高效的视觉语言系统迈出重要一步,提升了其处理复杂视觉场景的能力。
论文介绍
论文题目:More is not always better? Enhancing Many-Shot In-Context Learning with Differentiated and Reweighting Objectives
作者:张晓庆,吕昂,刘雨涵,Flood Sung,刘伟,栾剑,商烁,陈秀颖,严睿
通讯作者:陈秀颖,严睿
论文概述:针对多示例上下文学习(In-Context Learning, ICL)中性能随示例数量增加而下降这一大语言模型(LLMs)核心难题,现有方法在优化目标和数据利用方面仍存在显著瓶颈。传统以负对数似然(NLL)为主的目标函数往往无法有效区分不同示例的贡献,而随着示例数量增加,训练数据中的噪声也会被放大,进一步限制了模型的多示例学习能力。为此,我们提出了一种创新优化范式——DrICL(Differentiated and Reweighted In-Context Learning),以“差分优化 + 加权学习”双机制系统性解决上述问题。DrICL的核心包括:(1)全局差分优化:通过重构NLL目标函数,使得多示例场景下的性能显著优于零示例学习;(2)局部加权机制:受强化学习启发,引入累计优势(cumulative advantage)策略,对示例进行动态加权,抑制噪声数据的负面影响。为验证DrICL的广泛适应性,我们构建了多任务多示例评估基准——ICL-50,覆盖50项任务与最多350-shot的上下文配置,支持长达8,000 token序列的训练与评估。实验结果表明,DrICL在多个任务上均显著优于基线模型,特别是在in-domain与out-of-domain场景下表现出稳定的多示例泛化能力。我们公开了全部代码与数据集,以期推动多示例ICL方向的进一步研究与发展。
论文介绍
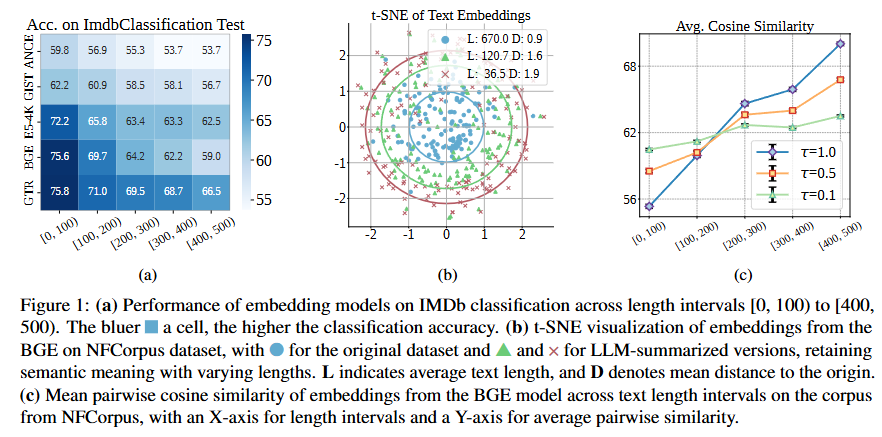
论文题目:Length-Induced Embedding Collapse in PLM-based Models
作者:周雨琦,戴孙浩,曹展硕,张骁,徐君
通讯作者:徐君
论文概述:文章研究了预训练语言模型(PLM)在处理长文本时表现退化的问题,并发现了一个新的现象:“长度坍缩(Length Collapse)”。该现象指的是随着文本长度的增加,模型生成的文本表示逐渐趋于相似,导致在分类、检索和语义匹配等任务中性能下降。文章通过频域分析发现,自注意力机制在处理长文本时会加强低通滤波效应,使得表示中过多保留低频信息,压缩了表示的多样性。为了解决这一问题,文章提出了一个无需重新训练的轻量级方法——温度缩放(TempScale),通过统一不同长度文本的注意力温度,缓解了表示坍缩现象。实验证明,该方法在MTEB和LongEmbed等基准任务中显著提升了长文本的处理效果。
论文介绍
论文题目:Uncovering the Impact of Chain-of-Thought Reasoning for Direct Preference Optimization: Lessons from Text-to-SQL
作者:刘涵冰*,李好洋*,张晓康,陈若彤,徐海勇,田天,祁琦,张静
论文概述:直接偏好优化(DPO)在数学应用题和代码生成等复杂推理任务中已被证实有效,但当应用于Text-to-SQL数据集时,其性能往往无法提升甚至会出现下降。我们的研究发现其根本原因在于:与数学和代码任务不同(这类任务天然适合将思维链推理与DPO结合),Text-to-SQL数据集通常仅包含最终答案(标准SQL查询),而缺乏详细的思维链解答步骤。通过为Text-to-SQL数据集注入合成的思维链解答步骤,我们首次实现了使用DPO在该任务上带来持续且显著的性能提升。我们还发现,思维链推理对于释放DPO潜力具有关键作用:它能有效缓解奖励破解(Reward hacking)现象、增强奖励模型判别能力并提升生成模型扩展性。这些发现为构建更稳健的Text-to-SQL模型提供了有效的启示。
论文介绍
论文题目:Learning to Generate Structured Output with Schema Reinforcement Learning
作者:卢雅西*,李昊伦*,从鑫,张众,林衍凯,刘知远,刘方明,孙茂松
论文概述:本研究调查了大型语言模型(LLMs)在生成结构化内容方面的能力,特别是生成有效JSON输出的能力。尽管JSON在语言模型与传统编程语言的集成中被广泛使用,但对这些能力的全面分析和基准测试仍然不足。我们探讨并分析了模型生成JSON的各个方面,包括严格遵守JSON模式以及基于模式的推理能力。随后,我们引入了一个包含复杂模式的基准,用于评估模型在三个关键类别中生成有效JSON的能力:使用标准模式生成有效JSON、翻译特殊标记,以及理解模式的限制。此外,我们结合了一种细粒度模式验证器的强化学习方法,以增强模型对JSON模式的理解,从而提高其性能。我们的模型在生成JSON输出方面取得了显著进步,并在诸如BFCL和IoA等下游任务中表现出色。
论文介绍
论文题目:Enhancing Large Language Model’s Capabilities in Open Domains via Autonomous Tool Integration from GitHub
作者:吕博涵*, 从鑫*, 俞鹤扬, 杨攀, 钱成, 王子和, 秦禹嘉, 叶奕宁, 卢雅西, 钱忱, 张众, 闫宇坤, 林衍凯, 刘知远, 孙茂松
论文概述:大语言模型在处理需要复杂领域计算的问题时仍显不足。尽管通过接入外部工具构建基于LLM的智能体可以增强其能力,但现有方法在应对开放领域中多样且不断变化的用户查询方面缺乏灵活性。为此,我们结合GitHub上的代码仓库基础上构建了OpenAct数据集。该数据集包含来自7个不同领域的339个问题,这些问题都需要使用特定领域的方法才能解决。实验表明,即使是当前最先进的LLM和基于LLM的智能体在OpenAct上的成功率也十分有限,凸显了对新方法的迫切需求。基于这一任务的特点,我们提出了OpenAgent,其能够通过自主集成来自GitHub的专业工具来应对开放领域中不断演化的查询。其采用:1)层次化框架,让专门智能体负责具体任务,并可向下分配子任务;2)双层经验学习机制,既能从人类经验中学习,也能从自身经验中迭代优化以克服工具缺陷。实验结果表明,OpenAgent在效果与效率上均显著优于现有方法。
论文介绍
论文题目:MAPS: Motivation-Aware Personalized Search via LLM-Driven Consultation Alignment
作者:秦维聪*,徐熠*,俞蔚捷,沈承磊,何明,范建平,张骁,徐君
论文概述:个性化商品搜索旨在检索并排序符合用户偏好和搜索意图的商品。尽管现有方法有效,但通常假设用户的搜索query完全反映了其真实动机。然而,我们对真实电商平台的分析表明,用户在搜索前常进行相关咨询,表明他们会基于动机和需求通过咨询细化意图。咨询中隐含的动机是个性化搜索的关键增强因素。
这一未探索领域带来了新挑战,包括将上下文动机与简洁查询对齐、弥合类别-文本差距,以及过滤序列历史中的噪声。为此,我们提出动机感知个性化搜索(MAPS)方法:该方法通过大语言模型(LLMs)将查询和咨询嵌入统一语义空间,利用注意力专家混合模型(MoAE)对关键语义进行加权,并引入双重对齐机制:(1)对比学习对齐咨询、评论和商品特征;(2)双向注意力将动机感知嵌入与用户偏好结合。在真实和合成数据集上的大量实验表明,MAPS 在检索和排序任务中均优于现有方法。
论文介绍
论文题目:Boosting Long-Context Information Seeking via Query-Guided Activation Refilling
作者:钱泓锦,刘政,张配天,窦志成,连德富
论文概述:随着大语言模型(LLMs)应用场景的拓展,如何高效处理超长文本上下文成为亟需解决的关键问题。受限于上下文窗口大小及键-值(Key-Value, KV)激活的计算开销,现有模型在处理长文本信息检索任务时面临显著效率瓶颈。值得注意的是,对于此类任务,用户查询所需的信息范围往往具有动态性——有时聚焦于细节,有时又需全局理解。然而,现有方法难以根据查询的复杂度自适应地感知并处理这些动态的信息需求。为此,本文提出一种基于查询引导的激活填充方法(Activation Refilling, ACRE),以高效支持长文本中的信息检索任务。ACRE设计了一种双层KV缓存结构,其中第一层缓存(L1)紧凑地存储全局信息,第二层缓存(L2)则保留更精细的局部细节。通过构建L1与L2之间的代理机制,模型可根据当前查询,从L2中动态填充L1,以实现全局语义感知与局部细节的融合解码。在多个长文本信息检索数据集上的实验证明,ACRE在保持推理效率的同时,显著提升了回答质量。
Findings of ACL 2025
论文介绍
论文题目:mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data
作者:陈浩楠,王亮,杨南,朱余韬,赵梓良,韦福如,窦志成
通讯作者:窦志成
论文概述:多模态嵌入模型因其能够将文本、图像等不同模态的数据映射到统一的表示空间而受到广泛关注。然而,有限的标注多模态数据常常限制了模型的嵌入性能。近期研究尝试通过合成数据缓解这一问题,但合成数据的质量仍是关键瓶颈。在本研究中,我们提出高质量合成多模态数据应满足三项关键标准。第一,范围广泛:生成的数据应覆盖多种任务和模态类型,具备良好的通用性。第二,稳健的跨模态对齐:不同模态之间应具有一致的语义表示。第三,高保真度:每种模态自身应具备真实、可靠的细节特征。在上述原则的指导下,我们构建的合成数据集具备以下特点:(1) 覆盖多种任务类型、模态组合及语言,(2) 通过多模态大语言模型的一次性深度思考流程生成,(3) 融合真实图像与语义准确、相关性强的文本内容,并通过自评与迭代优化机制确保其高保真度。依托高质量的合成与标注数据集,我们训练了一个多模态多语言嵌入模型——mmE5。大量实验结果表明,mmE5在MMEB基准测试中实现了当前最优性能,并在XTD多语言评估中表现出显著优势。我们已开源代码、数据集与模型。
论文介绍
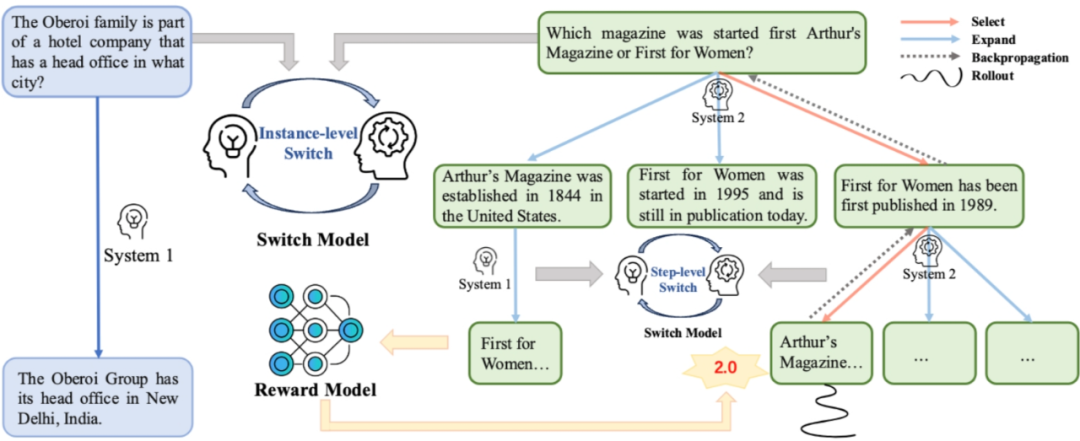
论文题目:Think More, Hallucinate Less: Mitigating Hallucinations via Dual Process of Fast and Slow Thinking
作者:成晓雪、李军毅、赵鑫、文继荣
通讯作者:赵鑫
论文概述:大语言模型在文本生成任务中展现出强大的能力,但仍普遍面临“幻觉”问题,即生成内容存在不可信或事实错误的情况。本文提出了一种新颖的框架 HaluSearch,通过引入基于树搜索的推理算法,引导模型在生成过程中进行显式的“慢思考”,以缓解幻觉现象。HaluSearch 将文本生成建模为逐步推理过程,并引入自评估奖励模型对每一步生成结果进行打分,引导搜索过程朝向更可信的生成路径。为在保证生成质量的同时提升推理效率,本文设计了层次化的系统切换机制,可在实例级和步骤级动态切换“快思考”与“慢思考”模式,以适应不同问题的复杂度和推理状态。在多个中英文数据集上的实验证明,HaluSearch 相较现有方法在准确性和可靠性方面均取得了显著提升。
论文介绍
论文题目:Expectation Confirmation Preference Optimization for Multi-Turn Conversational Recommendation Agent
作者:冯雪扬,张景森,唐嘉凯,李薇,蔡国豪,陈旭,戴全宇,朱越,董振华
通讯作者:陈旭,戴全宇
论文概述:近年来,大语言模型(LLMs)的进步极大推动了对话推荐智能体的发展。然而,现有代理常常生成短视的回复,难以持续引导用户、满足其期望。尽管偏好优化在对齐用户期望方面取得了一定成效,但在多轮对话中的效果仍然有限,且成本较高。为了解决这一问题,本文提出了一种新颖的基于期望确认理论的多轮偏好优化范式 ECPO,通过建模用户满意度在对话过程中的演变,揭示导致用户不满的深层原因。ECPO利用这些原因对不满意的回复进行有针对性的优化,从而实现轮次级别的偏好优化。同时,ECPO 避免了现有方法中高昂的采样开销,并确保优化过程带来实质性提升。为支持 ECPO 的实现,我们还引入了一个基于 LLM 的用户模拟器 AILO,用于模拟用户反馈并在推荐过程中执行期望确认机制。实验结果表明,ECPO 显著提升了 CRA 的交互能力,在效率和效果方面均优于现有 MTPO 方法。
论文介绍
论文题目:Select, Read, and Write: A Multi-Agent Framework of Full-Text-based Related Work Generation
作者:刘小川,宋睿华,王希廷,陈旭
通讯作者:宋睿华,王希廷
论文概述:自动化相关工作生成(Related Work Generation, RWG)能够在撰写相关工作部分(Related Work Section, RWS)的初稿时节省人们的时间和精力,便于后续修订。然而,现有的RWG方法通常面临两个问题:一是由于仅将参考文献的有限部分作为输入,导致对文献的理解较为浅显;二是由于未能有效捕捉参考文献之间的关系,导致对每篇文献的解释是孤立的。为了解决这些问题,我们关注于基于全文的RWG任务,并提出了一种新颖的多智能体框架。我们的框架由三个智能体组成:一个选择器(selector),它决定下一步阅读文献的哪个部分;一个阅读器(reader),它阅读所选部分并更新共享的工作记忆;以及一个写作者(writer),它基于最终整理的记忆生成RWS。为了更好地捕捉参考文献之间的关系,我们还为选择器提出了两种图感知(graph-aware)策略,使其能够在图结构约束下优化阅读顺序。大量实验表明,我们的框架在三种基础模型(Llama3-8B, GPT-4o, Claude-3-Haiku)和多种输入配置下始终提升了性能。采用图感知选择器的效果优于其他选择器,达到了最佳的性能水平。

论文题目:LLM-Based Multi-Agent Systems are Scalable Graph Generative Models
作者:季嘉蕊,雷润林,毕嘉伶,魏哲巍,陈旭,林衍凯,潘旭辰,李雅亮,丁博麟
通讯作者:魏哲巍
论文概述:自然生成的社交图演变过程的结构特性被广泛研究。以往的网络动态建模方法通常依赖于基于规则的模型,这些模型缺乏现实性和通用性;或依赖于深度学习模型,这些模型需要大规模的训练数据集,同时欠缺图扩展的能力。社交图作为实体交互的抽象表示,模拟社会人交互可用于探索网络演化机制。
借助大规模语言模型的预训练知识,我们提出了GraphAgent-Generator(GAG),这是一种基于模拟的动态文本属性社交图生成框架。GAG模拟了节点生成和交互边的动态演化过程,以实现zero-shot社交图生成。生成的图符合七个网络科学中的宏观网络属性,并在微观图结构指标上提高了11%。通过节点分类基准任务,我们验证了GAG能够超过现有图生成模型,有效捕捉图生成中的复杂文本-结构关联。此外,GAG支持生成包含近十万节点或一千万边的大规模图,通过基于LLM的大规模代理模拟和并行加速,相比单进程达到了90.4%的加速效果。
论文介绍
论文题目:Enhancing Medical Dialogue Generation through Knowledge Refinement and Dynamic Prompt Adjustment
作者:孙宏达,彭佳仁,杨文忠,何亮,杜博,严睿
通讯作者:严睿
论文概述:医疗对话系统 (MDS) 已成为重要的在线平台,通过实现与患者的多轮对话和情境感知对话来提升医疗保健水平。然而,当前的 MDS 通常面临两大挑战:(1) 难以在多轮对话中准确追踪患者不断变化的健康状况;(2) 难以根据每位患者不断变化的病情生成符合情境且个性化的回复。为了突破这些限制,我们提出了一种具有知识精炼和动态调整功能的新型医疗对话系统 (MedRef)。首先,我们设计了一种知识润色机制,用于从检索到的医疗数据中过滤掉不相关或噪声信息,从而更准确地预测关键医疗实体,例如症状、诊断和治疗。此外,我们设计了一个全面的提示结构,不仅融合了对话历史和检索到的知识,还融合了预测未来可能的实体,以指导后续回复。为了进一步增强适应性,我们开发了一种动态调整方法,可以根据患者的病情和知识实时持续调整提示内容,确保生成的回复在对话过程中始终保持情境感知和医学准确性。我们在两个广泛使用的基准数据集 MedDG 和 KaMed 上进行了全面的评估实验,结果表明 MedRef 的回复在文本质量和医学实体准确率方面均优于各种最先进的基准数据集, 验证了MedRef 显著提升 MDS 有效性和可靠性的潜力。
论文介绍
论文题目:MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents
作者:谭浩然*,张泽宇*,马辰,陈旭,戴全宇,董振华
通讯作者:陈旭,戴全宇
论文概述:近期的研究突出了记忆机制在基于大语言模型(LLM)代理中的重要性,这些机制使它们能够存储观察到的信息并适应动态环境。然而,评估其记忆能力仍然面临挑战。以往的评估通常受到记忆层级和交互场景多样性限制,且缺乏全面的指标来从多个方面反映记忆能力。为了解决这些问题,本文构建了一个更全面的数据集和基准测试,用于评估基于LLM的代理的记忆能力。我们的数据集将事实记忆和反思记忆作为不同的层级,并提出参与和观察作为多种交互场景。基于我们的数据集,我们提出了一个基准测试,命名为MemBench,用于从多个方面评估基于LLM的代理的记忆能力,包括其有效性、效率和容量。
论文介绍
论文题目:KAPA: A Deliberative Agent Framework with Tree-Structured Knowledge Base for Multi-Domain User Intent Understanding
作者:唐嘉凯,沈世奇,王智鹏,龚治,冯雪扬,孙泽旭,谭浩然,陈旭
通讯作者:陈旭
论文概述:针对通用领域中对话智能体助手难以精准预测用户模糊查询背后的隐式意图,提出了新型的数据集UIU,该数据集覆盖了多领域、多用户语气风格和多序列任务的个性化对话。在此基础上,我们设计了一套知识增强的主动式对话智能体 KAPA。具体地,我们引入多智能体协作的四阶段对话模拟过程(感知、分析、反思、知识积累)来构造高层次的意图理解经验知识,并构造树形层次化结构的多域知识库帮助推理阶段时智能体对相关域知识的快速检索。我们在 UIU 数据集上的实验验证了方法 KAPA 的有效性。
论文介绍
论文题目:Distance between Relevant Information Pieces Causes Bias in Long-Context LLMs
作者:田润初, 李阳昊, 傅岳朋, 邓思阳, 罗钦雨, 钱成, 王硕, 从鑫, 张众, 吴叶赛, 林衍凯, 汪华东,刘晓江
通讯作者:从鑫,林衍凯
论文概述:在大语言模型(LLMs)中,位置偏差会影响其有效处理长输入的能力。其中一个显著的例子是“中间遗忘”(Lost in the Middle)现象,即 LLMs 难以利用位于输入中间的相关信息。尽管现有研究主要关注单一的相关信息,但现实应用往往涉及多个相关信息片段。为弥合这一差距,我们提出 LongPiBench,一个用于评估涉及多个相关信息片段的位置偏差的基准测试。该基准涵盖多种任务和不同的输入长度。我们对三种商用模型和六种开源模型进行了全面实验。实验结果表明,尽管当前大多数模型在应对“中间遗忘”问题上表现更为稳健,但仍然存在明显的与相关信息片段间距相关的偏差。这些发现强调了在长上下文 LLM 评估和优化中,降低位置偏差的重要性。
论文介绍
论文题目:Revisiting Weak-to-Strong Generalization in Theory and Practice: Reverse KL vs. Forward KL
作者:姚巍*,杨文恺*,汪子乔,林衍凯,刘勇
通讯作者:刘勇
论文概述:随着大语言模型逐步逼近超人类性能,确保其与人类价值观及能力保持对齐的复杂性显著增加。基于弱模型预测来指导强系统的“弱到强泛化”(weak-to-strong generalization)方法虽前景广阔,但其效果往往受限于弱预测中固有的噪声与偏差。针对这一难题,我们提出一种基于理论推导的解决方案:采用逆向KL散度替代前向KL散度。得益于”零强迫效应”,逆向KL散度能聚焦高置信度预测,从而有效抑制不可靠弱监督的干扰。在理论层面,我们拓展了现有理论分析,证明了当充分预训练的强模型仅在线性输出层进行微调时,逆向KL能确保其性能超越弱模型,且提升幅度严格大于等于二者的预测分歧度。实验结果表明,在绝大多数场景下,采用逆向KL散度与逆向交叉熵训练的强模型,其性能均稳定优于使用前向KL散度及标准交叉熵的基准模型,充分印证了逆向损失函数的实用价值。
论文介绍
论文题目:MotiveBench: How Far Are We From Human-Like Motivational Reasoning in Large Language Models?
作者:雍希贤,练建勋,矣晓沅,周骁,谢幸
通讯作者:周骁
论文概述:LLMs被广泛应用于如社交模拟和AI陪伴等各种场景,然而它们在多大程度上能够模仿人类动机与行为仍是一个尚未深入探索的问题。现有的评估基准往往受限于情境过于简单、缺乏角色身份设定,导致与现实世界存在信息不对称。为了解决这一问题,本文提出了MotiveBench——一个包含200个丰富上下文情境和600个涵盖多层次动机推理任务的评估基准。基于此,我们对七个主流模型家族进行了大规模实验,比较了各家族内部不同规模与版本的表现。实验结果揭示出多个重要发现,例如LLMs在处理“爱与归属”类动机方面存在较大困难,以及模型普遍倾向于过度理性与理想化。这些发现为未来提升LLMs拟人化能力提供了有价值的研究方向。

论文介绍
论文题目:Entropy-based Exploration Conduction for Multi-step Reasoning
作者:张静涵,王希廷,莫冯然,周烨阳,高万夫,刘鲲鹏
通讯作者:王希廷
论文概述:在大型语言模型(LLM)的推理过程中,多步推理已被证明在解决复杂任务中具有显著效果。然而,探索深度对推理性能有着重要影响。现有自动决定推理深度的方法往往成本高、灵活性差,从而削弱了模型的推理准确性。为解决这一问题,我们提出了一种基于熵的探索深度引导方法,该方法通过监测语言模型输出的熵值与方差熵,在多步推理中动态调整探索深度。我们利用这两个指标分别衡量模型当前的不确定性以及连续推理步骤中不确定性的波动情况。基于这些变化,模型以概率方式决定是加深、扩展还是终止推理路径,从而在推理准确性与探索效率之间实现平衡。我们在多个基准数据集上的实验结果验证了该方法的有效性。
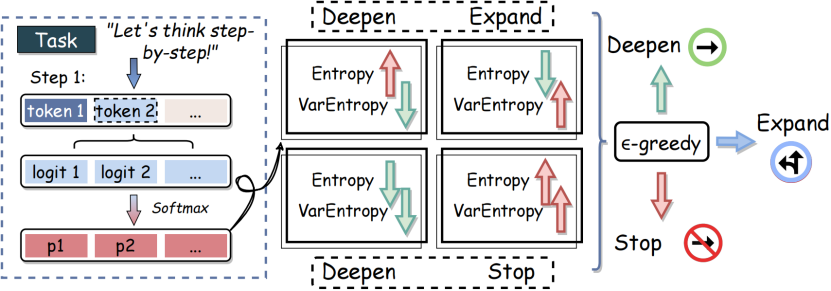
论文介绍
论文题目:Thinking Before Running! Efficient Code Generation with Thorough Exploration and Optimal Refinement
作者:张晓庆,刘雨涵,Flood Sung,陈秀颖,商烁,严睿
通讯作者:刘雨涵,严睿
论文概述:针对代码生成中测试时延迟高、计算开销大的关键挑战,现有多轮计算方法虽具备一定精度,但效率极低,限制了其实际应用。为此,我们提出了一种高效且可扩展的代码生成框架——ThinkCoder,通过“广泛探索 + 精准精修”的双阶段机制,有效提升了生成质量并显著降低计算成本。具体而言,ThinkCoder首先在探索阶段生成多样化解空间,覆盖潜在解答区域;随后在精修阶段对候选解进行深度优化,以实现最终选择前的精细考量,避免了过度的试错成本。为了进一步压缩推理成本,我们引入了偏好驱动优化机制——Reinforced Self-Training (ReST),该机制利用ThinkCoder的探索轨迹,通过偏好学习引导大模型进化,提升其内在探索效率,从而在保持准确性的同时大幅降低计算负担。实验结果表明,ThinkCoder在HumanEval和MBPP等主流代码生成基准上均显著优于现有方法:在仅使用6.4%计算资源的情况下,Pass@1精度比MapCoder提升3.0%;相较AgentCoder,ThinkCoder在2轮内即实现更高的0.5%精度,远优于其5轮计算表现。同时,结合ReST机制,LLaMA2-7B仅用20%资源即可达到与更大模型相当的性能,验证了方法的高效性与可扩展性。
论文介绍
论文题目:P3: Prompts Promote Prompting
作者:张鑫宇、胡元泉、刘方超、窦志成
通讯作者:窦志成
论文概述:本研究提出了一种新型的提示词自动优化框架P3,它通过迭代的方式同时优化系统提示词和用户提示词。P3框架具备了提示词优化的亲和性、多样性、高效率等优点,重点解决了传统在线提示词优化方法存在的用户与系统提示词不亲和、用户提示词优化过拟合、用户提示词在线优化效率低等问题,本框架在通用任务(如Arena-hard和Alpaca-eval)和推理任务(如GSM8K和GPQA)上的大量实验表明,P3在自动提示词优化领域可以取得明显优势。
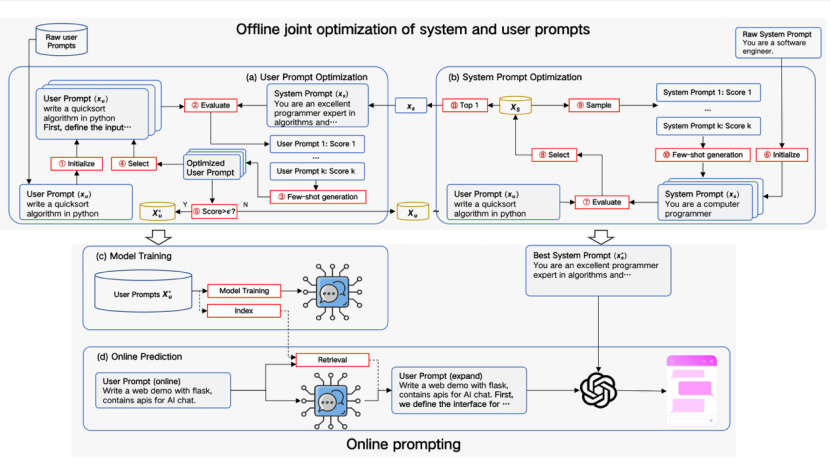
论文介绍
论文题目:Neuro-Symbolic Query Compiler
作者:张宇尧,窦志成,李晓熙,金佳杰,伍永康,李中华,叶琪,文继荣
通讯作者:窦志成
论文概述:在检索增强生成(Retrieval-Augmented Generation, RAG)系统中,对检索意图的精确识别仍然是一项具有挑战性的任务,尤其是在资源受限条件下以及面对具有嵌套结构和依赖关系的复杂查询时。本文提出了QCompiler,一种受语言学语法规则和编译器设计启发的神经-符号框架,旨在弥合这一空白。该方法在理论上设计了一种最小但充分的巴科斯-诺尔范式(Backus-Naur Form, BNF)语法 G[q],用于形式化复杂查询。与以往方法不同,该语法在保持完备性的同时尽量减少了冗余性。QCompiler由三个组件组成:查询表达式翻译器(Query Expression Translator)、词法语法解析器(Lexical Syntax Parser) 和递归下降处理器(Recursive Descent Processor),用于将查询编译为抽象语法树(Abstract Syntax Trees, ASTs)以供执行。叶节点中子查询的原子性确保了更为精确的文档检索与响应生成,显著提升了 RAG 系统处理复杂查询的能力。
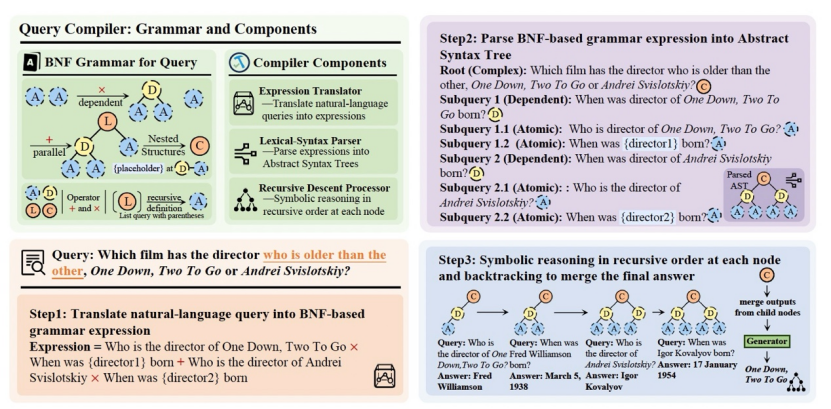
论文介绍
论文题目:CitaLaw: Enhancing LLM with Citations in Legal Domain
作者:张珂镨,俞蔚捷,戴孙浩,徐君
论文概述:在法律任务中,生成有引用支持的回复(例如相关的法律条款和判例)对于确保大语言模型(LLMs)的可信度至关重要。对于寻求法律建议的外行人士而言,具备引用的大语言模型回复提供了可验证的信息,提升了用户对系统的信任度;对于律师和法官等法律从业者来说,引用作为支持性证据,有助于分析复杂案件、验证法律论点,并确保裁决符合既定的法律原则。为此,我们提出了CitaLaw,评估LLMs的回复是否具备坚实的法律依据、准确无误的引用。CitaLaw通过提供多样化的法律问题和全面的法律参考语料库,使LLMs能够检索支持性引用并与回复对齐。同时,我们引入法律三段论式的评估方法来衡量LLMs回复的法律一致性以及其与用户问题的契合度。实验表明,融入法律引用显著提升了LLMs回复质量,所提评估方法与人类判断有较强的一致性。
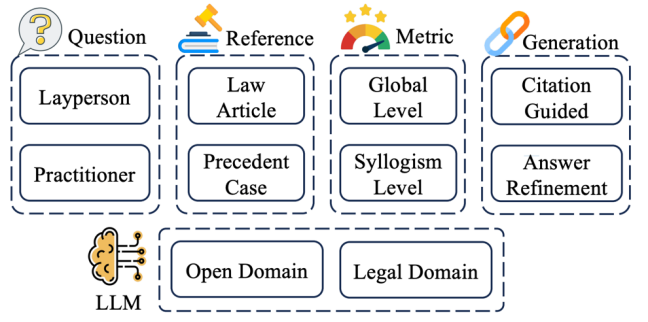
(文:机器学习算法与自然语言处理)