

作者:李宝珠
编辑:椰椰
转载请联系本公众号获得授权,并标明来源
在刚刚结束的 Google I/O 2025 的主题演讲中,Google 发布了多项重要更新,进一步展示其在 AI 竞速赛中的实力。
北京时间 5 月 21 日凌晨,Google I/O 2025 大会如约而至,公司 CEO Sundar Pichai 在主题演讲中接连宣布多项重要更新,全面展示了 Google 在 AI 领域的强劲能力与增长速度。
「通常,在 I/O 大会的前几周,我们不会透露太多信息,因为我们会把最重磅的模型留到大会上发布。但在 Gemini 时代,我们很可能在三月某个周二已经推出最智能的模型,或者提前一周公布像 AlphaEvolve 这样令人振奋的突破」,Sundar Pichai 介绍道。的确,关注 Google 的读者应该知道,就在大会前夕,其才发布了 AlphaEvolve 这样具有里程碑意义的新模型,将人们对 I/O 大会的期待值拉满。
而就在刚刚结束的主题演讲中,「劈柴哥」果然不负众望,除了 Gemini 的一系列更新外,还发布了 Imagen 4、Veo 3 以及头显、XR 眼镜等产品的最新进展。本文将对其中的重点更新进行介绍 ⬇️
Gemini 2.5 全系更新
Deep Think 能力强大
Gemini 2.5 的更新是人们意料之中的期待,却也惊喜满满。Google 在 3 月份推出了其迄今为止最智能的模型——Gemini 2.5 Pro,并在两周前提前为开发者带来了 Gemini 2.5 Pro Preview 版本更新,随后便在多个大模型评测榜单中抢占前列。
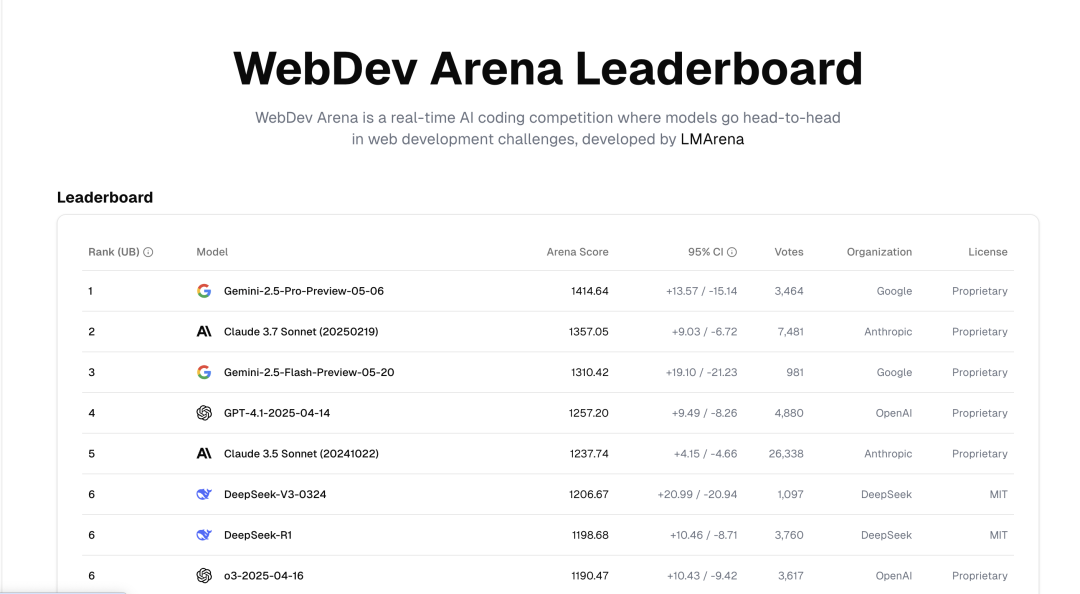
例如,在编程基准测试 WebDev Arena 中得分达到 1415,成功登顶。
为了进一步探索 Gemini 的思考能力,Google 开始测试一种名为 Deep Think 的增强推理模式。这种模式通过新的研究技术,使模型在回应前能够考虑多种假设。
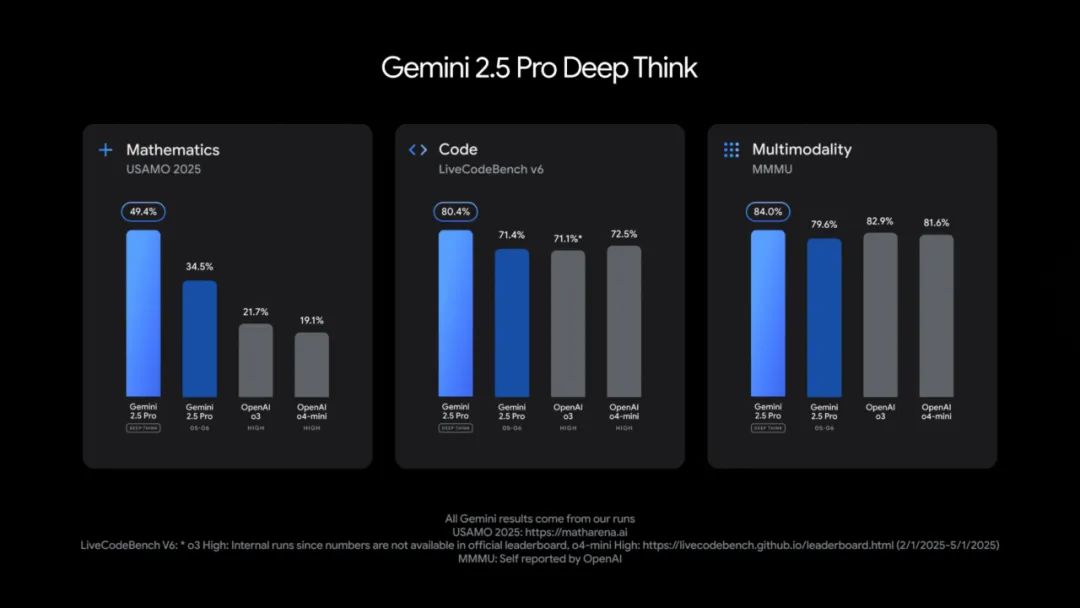
从效果上看,Gemini 2.5 Pro Deep Think 版本在多个高难度基准上表现出色,超越了 OpenAI o3 和 o4-mini。其中包括:
* 在 2025 年 USAMO(美国数学奥林匹克) 测试中取得了优异成绩;
* 在面向竞赛级编程能力的高难度基准 LiveCodeBench 上领先;
* 在 MMMU(多模态推理测试)中取得 84.0% 的高分,展现出卓越的多模态推理能力。
此外,Gemma 3 系列也迎来更新,为满足移动设备端的 AI 需求,Google 联合高通、联发科、三星等厂商提出了一个全新的前沿框架 Gemma 3n,其借助 Google DeepMind 的一项创新技术——逐层嵌入(Per-Layer Embeddings, 简称 PLE),实现了显著的内存使用优化。尽管模型的原始参数量分别为 50 亿(5B)和 80 亿(8B),但借助 PLE 技术,这些更大的模型可以在移动设备上运行或从云端实时推理时,内存开销仅相当于 20 亿(2B)或 40 亿(4B)参数模型,即只需 2GB 或 3GB 的动态内存即可运行。
Veo 3 与 Imagen 4,激发创造力
Veo 3 相比上一代产品,不仅在视频画质上有了显著提升,更重要的是首次实现了视频与音频的同时生成。无论是城市街道背景下的车流声、公园中的鸟鸣,甚至是角色间的对话,Veo 3 都能根据文本提示或用户需求自动加入音频元素。
该模型还在真实物理现象如口型同步等方面表现出色,能够理解复杂的场景描述并将其转化为动态视频。目前,Veo 3 已经上线,美国地区的 Ultra 订阅用户可以在 Gemini 应用及 Flow 中体验,企业用户则需通过 Vertex AI 平台获取使用权。
Imagen 4 是这次升级的重点之一,在保留了快速创建图像的优势基础上,进一步提升了图像细节表现力,无论是错综复杂的织纹、水珠还是动物毛发都能完美呈现。
此外,Imagen 4 在处理照片级写实和抽象风格图片方面同样卓越,能根据不同需求生成适用于打印、展示等场合的高质量图像。尤为值得一提的是它的排版能力得到了大幅提升,非常适合制作贺卡、海报乃至漫画书。当前,Imagen 4 已集成至Gemini、Whisk、Vertex AI 及 Google Workspace 中的幻灯片、视频、文档等多个套件内供用户使用。




戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)