

在周四的首届开发者大会上,Anthropic 推出了两款新的人工智能模型,这家初创公司声称它们至少在流行基准测试中的表现属于行业最佳。
据Anthropic 公司介绍,Claude 4 系列模型中的新成员 Claude Opus 4 和 Claude Sonnet 4 能够分析大型数据集、执行长期任务并采取复杂行动。该公司表示,这两款模型针对编程任务进行了优化,特别适合编写和编辑代码。
付费用户和免费聊天机器人应用用户均可使用 Sonnet 4,但仅付费用户能访问 Opus 4。通过亚马逊 Bedrock 平台和谷歌 Vertex AI 提供的 Anthropic API 服务,Opus 4 定价为每百万 token 15/75 美元(输入/输出),Sonnet 4 则为每百万 token 3/15 美元(输入/输出)。
Token 是 AI 模型处理的基础数据单元。100 万 token 约等于 75 万个单词——比《战争与和平》全文字数还多出约 16.3 万词。
图片来源:Anthropic
Anthropic 推出 Claude 4 系列模型之际,该公司正寻求大幅提升营收。 据报道 ,这家由前 OpenAI 研究人员创立的公司目标是在 2027 年实现 120 亿美元收益,较今年 22 亿美元的预期大幅增长。Anthropic 近期敲定了 25 亿美元信贷融资,并从亚马逊及其他投资者处筹集了数十亿美元 ,以应对开发尖端模型带来的成本上升 。
竞争对手使得保持AI 竞赛领先地位并非易事。尽管 Anthropic 今年早些时候推出了旗舰级新 AI 模型 Claude Sonnet 3.7 及名为 Claude Code 的代理编码工具,但包括 OpenAI 和谷歌在内的竞争者正竞相通过自研的强大模型和开发工具超越该公司。
Anthropic 正全力以赴打造 Claude 4。
Anthropic 表示,今天发布的两款模型中性能更强的 Opus 4 能在工作流多个环节保持“专注执行“。而作为 Sonnet 3.7″直接替代品“设计的 Sonnet 4,该公司称其在编程和数学方面较前代模型有所提升,且能更精准地遵循指令。
Claude 4 系列相比 Sonnet 3.7 更不易出现“奖励黑客”行为,Anthropic 声称。奖励黑客,亦称规范博弈,指模型通过走捷径和钻漏洞来完成任务的行为。
需要明确的是,这些改进并未使模型在每个基准测试中都成为全球最佳。例如,尽管Opus 4 在评估编码能力的 SWE-bench Verified 上超越了谷歌的 Gemini 2.5 Pro 和 OpenAI 的 o3 及 GPT-4.1,但在多模态评估 MMMU 或针对博士级生物、物理、化学问题的 GPQA Diamond 测试中,它仍无法超越 o3。
Anthropic Claude 4,ANTHROPIC 内部基准测试的结果。
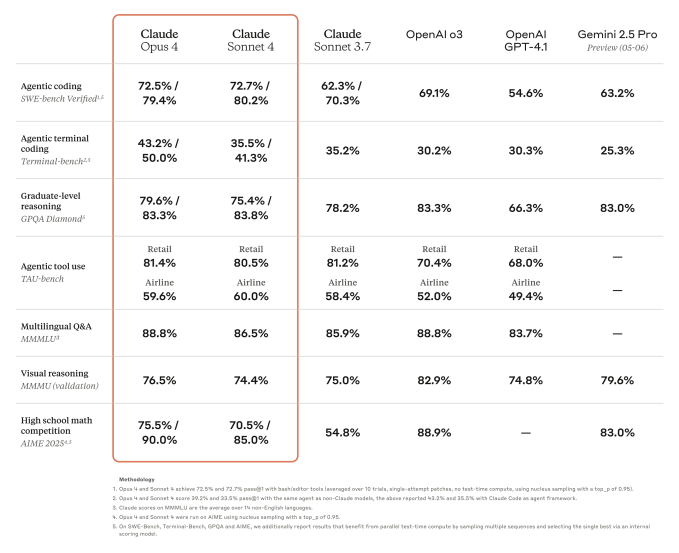
图片来源:Anthropic
尽管如此,Anthropic 仍在对 Opus 4 实施更严格的防护措施,包括增强的有害内容检测器和网络安全防御。该公司声称其内部测试发现,Opus 4 可能“显著提升“具有 STEM 背景者获取、生产或部署化学、生物或核武器的能力,达到了 Anthropic 的“ASL-3”模型规范 。
Opus 4 和 Sonnet 4 均为 Anthropic 所称的“混合型“模型,既能实现近乎即时的响应,也能进行深入推理所需的长时间思考(就 AI 能像人类理解那样“推理“与“思考“的程度而言)。开启推理模式后,这些模型在回答问题前会花费更多时间考量可能的解决方案。
随着模型进行推理,它们会展示一个“用户友好”的思考过程摘要,Anthropic 表示。为何不展示全部内容?该公司在提供给 TechCrunch 的博客文章草稿中承认,部分原因是为了保护 Anthropic 的“竞争优势”。
Opus 4 和 Sonnet 4 能够并行使用多种工具(如搜索引擎),并在推理与工具间交替切换以提升回答质量。它们还能提取并存储事实至“记忆“中,从而更可靠地处理任务,逐步构建 Anthropic 所称的“默会知识“。
为了让模型更便于程序员使用,Anthropic 正在对前述 Claude Code 进行升级。Claude Code 允许开发者直接从终端通过 Anthropic 的模型运行特定任务,现已集成至 IDE,并提供了让开发者将其与第三方应用连接的 SDK。
Claude Code SDK 于本周早些时候发布,支持在兼容操作系统上以子进程形式运行 Claude Code,为构建利用 Claude 模型能力的 AI 编程助手及工具提供了途径。
Anthropic 已为微软 VS Code、JetBrains 和 GitHub 发布了 Claude Code 扩展与连接器。GitHub 连接器允许开发者标记 Claude Code 以响应审阅者反馈,并尝试修复代码中的错误或进行其他修改。
AI 模型在编写高质量代码方面仍面临挑战。代码生成 AI 往往会引入安全漏洞 和错误 ,这源于其在理解编程逻辑等领域的能力缺陷 。然而它们提升编码效率的潜力正推动企业和开发者迅速采用这些技术 。
Anthropic 敏锐地意识到这一点,承诺将更频繁地更新模型。
“我们正转向更频繁的模型更新,持续提供一系列改进,从而更快地为客户带来突破性能力,”这家初创公司在草稿文章中写道。“这种方法能让您始终处于技术前沿,因为我们不断优化和增强我们的模型。”
根据彭博社消息,Anthropic 研究团队负责人 Krieger 表示,针对 Opus 4 的开发重点在于让模型能更长时间独立工作,并持续追踪其操作状态。早期测试方日本电商乐天集团已实现连续 7 小时使用 Opus 4 优化开源代码。
克里格表示:“过去,这个模型能制定出长达数小时的计划。”但最终它会“在某个环节卡住”或失去连贯性。
参考资料
https://www.bloomberg.com/news/articles/2025-05-22/ai-startup-anthropic-releases-more-powerful-opus-model-after-delay?srnd=phx-technology
https://techcrunch.com/2025/05/22/anthropics-new-claude-4-ai-models-can-reason-over-many-steps/
编译:ChatGPT
(文:Z Potentials)