

本文使用Dify v1.0.0-beta.1版本。模型插件结构基本是模型供应商(模型公司,比如siliconflow、xinference)- 模型分类(模型类型,比如llm、rerank、speech2text、text_embedding、tts)- 具体模型(比如,deepseek-v2.5)。本文以xinference为例,介绍Dify中的自定义模型插件开发例子。
自定义模型指的是需要自行部署或配置的 LLM,默认包含模型类型和模型名称两个参数,无需在供应商 yaml 文件定义。供应商配置文件无需实现 validate_provider_credential。Runtime会根据用户选择的模型类型或模型名称,自动调用对应模型层的 validate_credentials方法进行验证。
一.xinference模型插件
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,可使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。
1.多层模型分类
│ xinference_helper.py
│
├─llm
│ llm.py
│ __init__.py
│
├─rerank
│ rerank.py
│ __init__.py
│
├─speech2text
│ speech2text.py
│ __init__.py
│
├─text_embedding
│ text_embedding.py
│ __init__.py
│
└─tts
tts.py
__init__.py
2.通过API秘钥配置
安装Xinference插件后,通过输入API密钥等信息进行配置。如下所示:
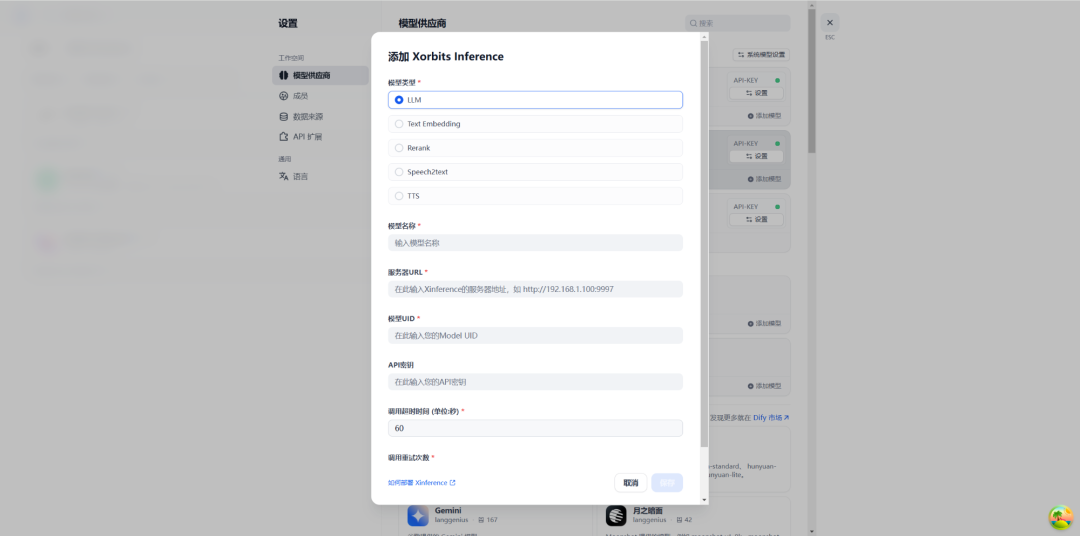
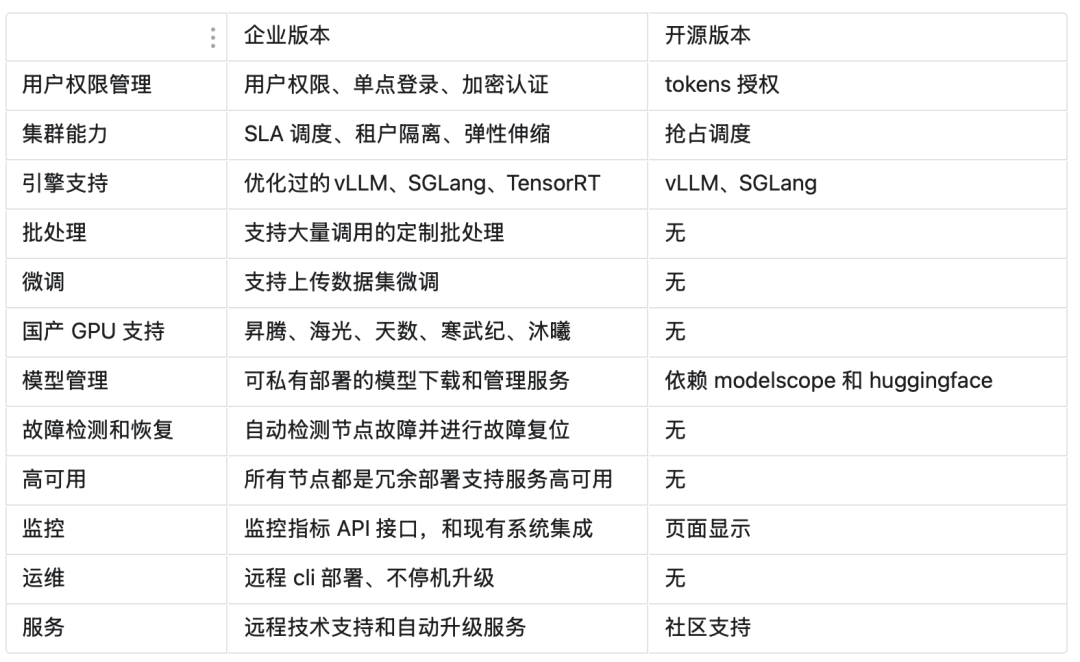
除社区支持开源版外,也提供企业版本,Xinference企业版和开源版本的对比[7],如下所示:
二.创建模型供应商
通过Dify插件脚手架工具,创建项目就不再介绍了,主要是选择模型插件模版和配置插件权限等操作[1][2]。
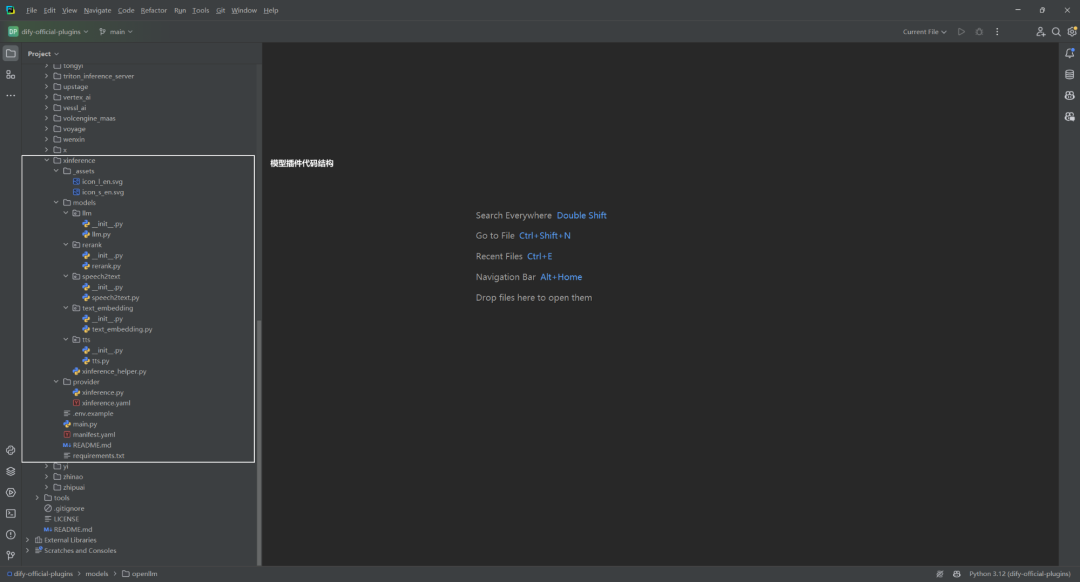
1.创建模型供应商配置文件
明确自定义模型中所包含的模型类型。在插件项目的 /provider 路径下,新建 xinference.yaml 文件。
Xinference 家族模型支持 LLM、Text Embedding 和 Rerank 等模型类型,因此需要在xinference.yaml 文件中包含上述模型类型。
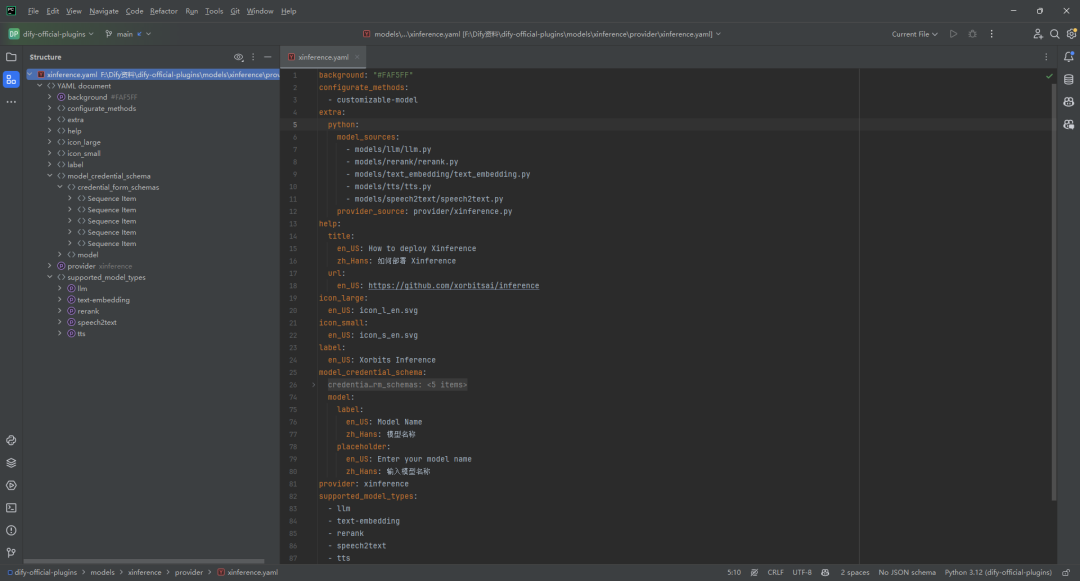
background: "#FAF5FF"
configurate_methods:
- customizable-model
extra:
python:
model_sources:
- models/llm/llm.py
- models/rerank/rerank.py
- models/text_embedding/text_embedding.py
- models/tts/tts.py
- models/speech2text/speech2text.py
provider_source: provider/xinference.py
help:
title:
en_US: How to deploy Xinference
zh_Hans: 如何部署 Xinference
url:
en_US: https://github.com/xorbitsai/inference
icon_large:
en_US: icon_l_en.svg
icon_small:
en_US: icon_s_en.svg
label:
en_US: Xorbits Inference
model_credential_schema:
credential_form_schemas:
- label:
en_US: Server url
zh_Hans: 服务器URL
placeholder:
en_US: Enter the url of your Xinference, e.g. http://192.168.1.100:9997
zh_Hans: 在此输入Xinference的服务器地址,如 http://192.168.1.100:9997
required: true
type: secret-input
variable: server_url
- label:
en_US: Model uid
zh_Hans: 模型UID
placeholder:
en_US: Enter the model uid
zh_Hans: 在此输入您的Model UID
required: true
type: text-input
variable: model_uid
- label:
en_US: API key
zh_Hans: API密钥
placeholder:
en_US: Enter the api key
zh_Hans: 在此输入您的API密钥
required: false
type: secret-input
variable: api_key
- default: "60"
label:
en_US: invoke timeout (unit:second)
zh_Hans: 调用超时时间 (单位:秒)
placeholder:
en_US: Enter invoke timeout value
zh_Hans: 在此输入调用超时时间
required: true
type: text-input
variable: invoke_timeout
- default: "3"
label:
en_US: max retries
zh_Hans: 调用重试次数
placeholder:
en_US: Enter max retries
zh_Hans: 在此输入调用重试次数
required: true
type: text-input
variable: max_retries
model:
label:
en_US: Model Name
zh_Hans: 模型名称
placeholder:
en_US: Enter your model name
zh_Hans: 输入模型名称
provider: xinference
supported_model_types:
- llm
- text-embedding
- rerank
- speech2text
- tts
configurate_methods为customizable-model,即Xinference为本地部署的供应商,并且没有预定义模型,需要用什么模型需要根据 Xinference 的文档进行部署,因此此处的方法为自定义模型。如果接入的供应商提供自定义模型,需要添加model_credential_schema 字段。
2.编写模型供应商代码
对于像 Xinference 这样的自定义模型供应商,可跳过完整实现的步骤。只需创建一个名为 XinferenceProvider 的空类,并在其中实现一个空的 validate_provider_credentials 方法。
import logging
from dify_plugin import ModelProvider
logger = logging.getLogger(__name__)
class XinferenceAIProvider(ModelProvider):
def validate_provider_credentials(self, credentials: dict) -> None:
pass
• XinferenceProvider 是一个占位类,用于标识自定义模型供应商。
• validate_provider_credentials 方法虽然不会被实际调用,但必须存在,这是因为其父类是抽象类,要求所有子类都实现这个方法。通过提供一个空实现,可以避免因未实现抽象方法而导致的实例化错误。
三.接入预定义模型
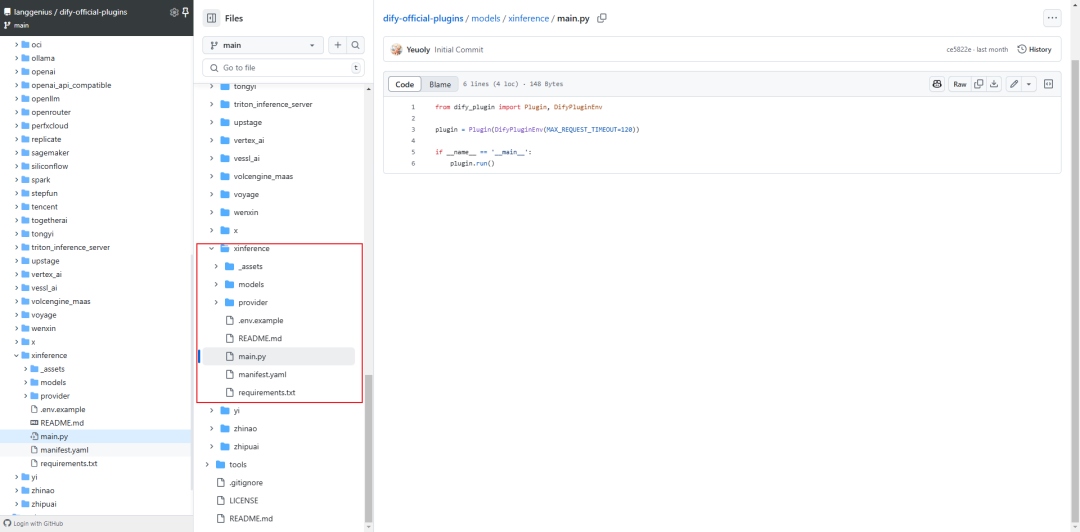
1.按模型类型创建不同模块结构
模型供应商下可能提供了不同的模型类型,需在供应商模块下创建相应的子模块,确保每种模型类型有独立的逻辑分层,便于维护和扩展[3]。当前支持模型类型如下:
2.编写模型调用代码
(1)llm.py
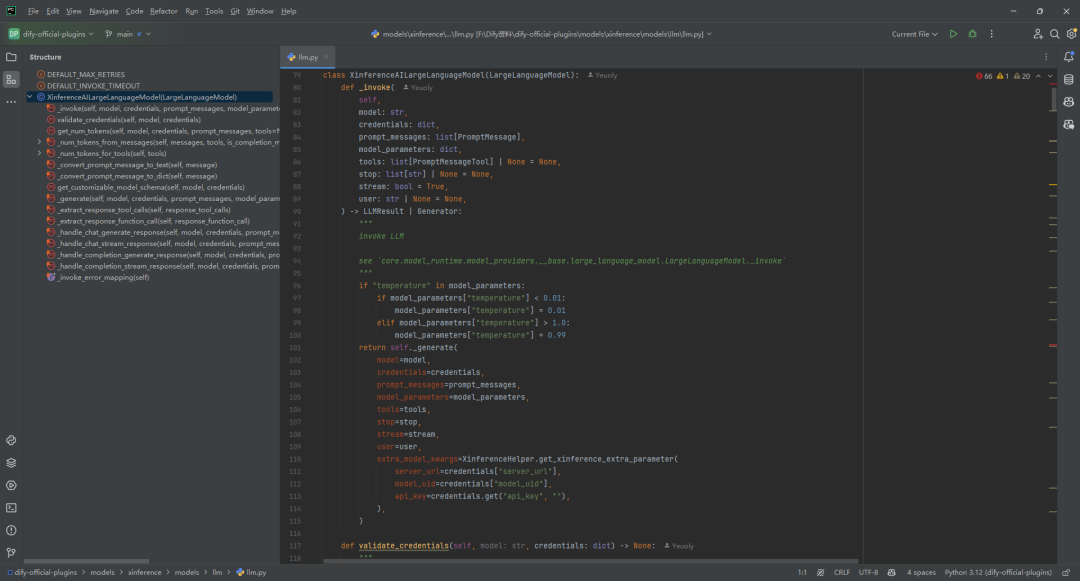
与预定义类型模型不同,由于没有在 yaml 文件中定义一个模型支持哪些参数,因此,需要动态时间模型参数的Schema。比如 Xinference支持max_tokens 、temperature 、top_p 这三个模型参数。但是有的供应商根据不同的模型支持不同的参数,比如供应商 OpenLLM 支持top_k,但是并不是这个供应商提供的所有模型都支持 top_k,这里举例A模型支持 top_k,B 模型不支持top_k,那么需要在这里动态生成模型参数的Schema,如下所示:
def get_customizable_model_schema(self, model: str, credentials: dict) -> AIModelEntity | None:
"""
used to define customizable model schema
"""
rules = [
ParameterRule(
name='temperature', type=ParameterType.FLOAT,
use_template='temperature',
label=I18nObject(
zh_Hans='温度', en_US='Temperature'
)
),
ParameterRule(
name='top_p', type=ParameterType.FLOAT,
use_template='top_p',
label=I18nObject(
zh_Hans='Top P', en_US='Top P'
)
),
ParameterRule(
name='max_tokens', type=ParameterType.INT,
use_template='max_tokens',
min=1,
default=512,
label=I18nObject(
zh_Hans='最大生成长度', en_US='Max Tokens'
)
)
]
# if model is A, add top_k to rules
if model == 'A':
rules.append(
ParameterRule(
name='top_k', type=ParameterType.INT,
use_template='top_k',
min=1,
default=50,
label=I18nObject(
zh_Hans='Top K', en_US='Top K'
)
)
)
"""
some NOT IMPORTANT code here
"""
entity = AIModelEntity(
model=model,
label=I18nObject(
en_US=model
),
fetch_from=FetchFrom.CUSTOMIZABLE_MODEL,
model_type=model_type,
model_properties={
ModelPropertyKey.MODE: ModelType.LLM,
},
parameter_rules=rules
)
return entity
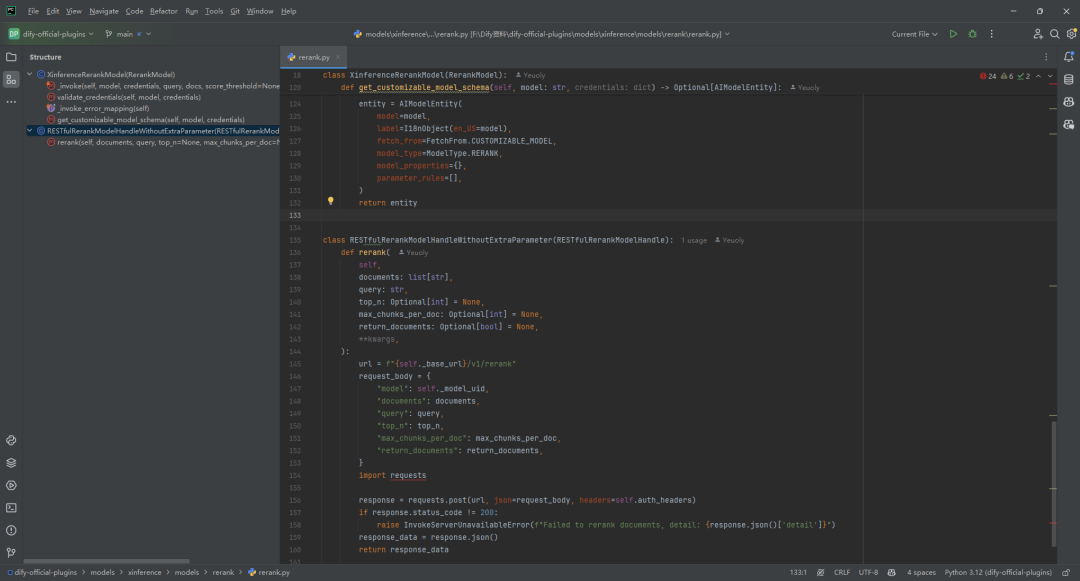
(2)rerank.py
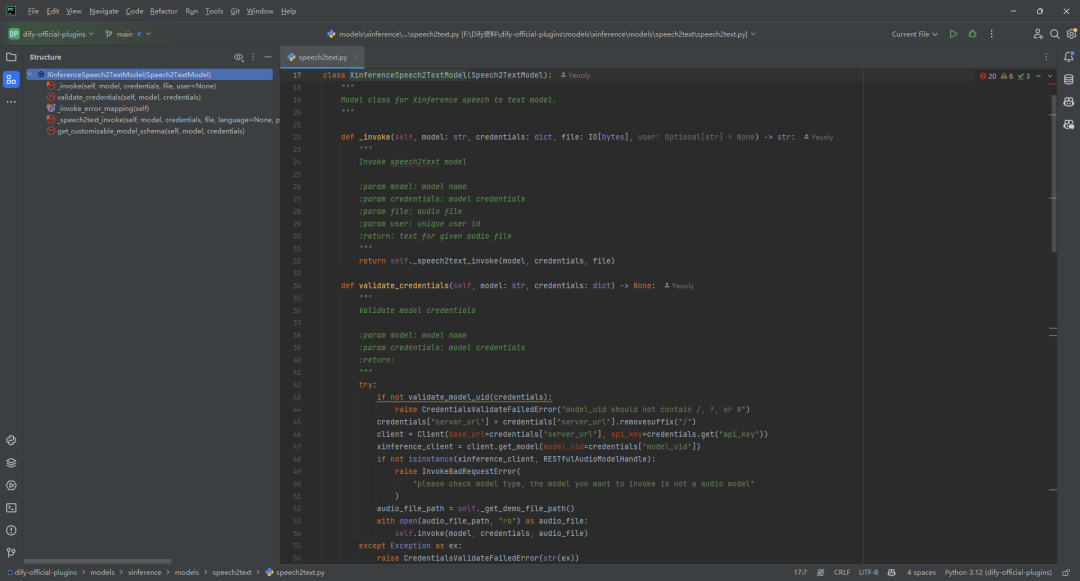
(3)speech2text.py
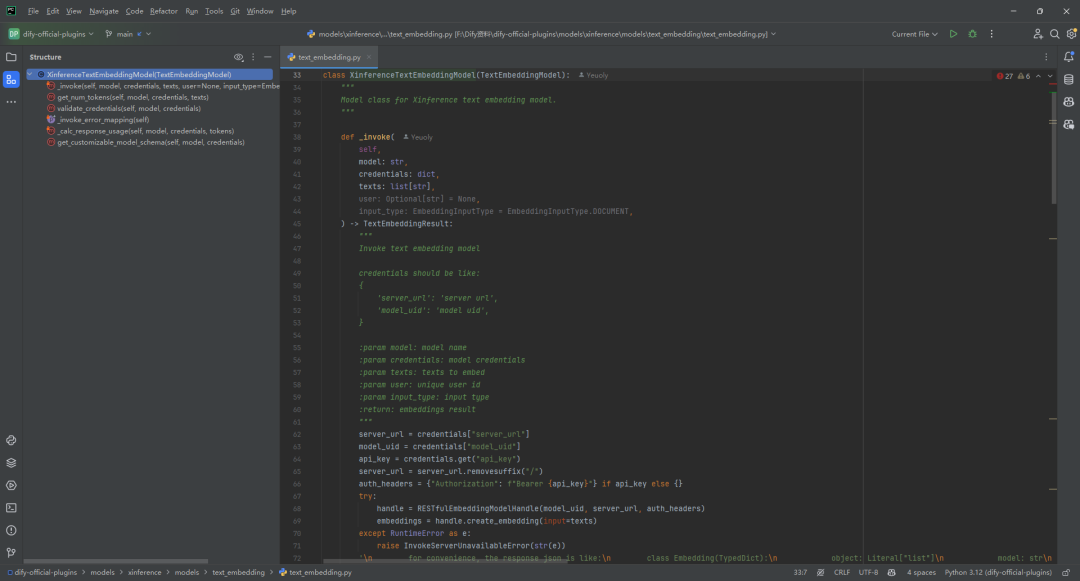
(4)text_embedding.py
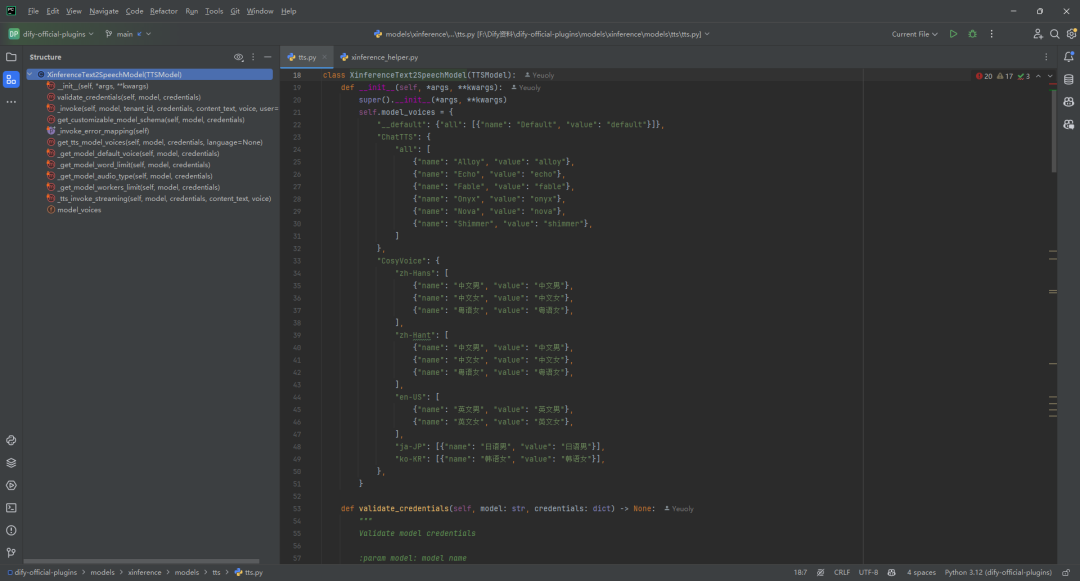
(5)tts.py
4.调试和发布插件
调试和发布插件不再介绍,具体操作参考文献[2]。
参考文献
[1] Model 插件:https://docs.dify.ai/zh-hans/plugins/quick-start/developing-plugins/model
[2] Dify中的GoogleSearch工具插件开发例子:https://z0yrmerhgi8.feishu.cn/wiki/Ib15wh1rSi8mWckvWROckoT2n6g
[3] https://github.com/langgenius/dify-official-plugins/tree/main/models/xinference
[4] 模型设计规则:https://docs.dify.ai/zh-hans/plugins/api-documentation/model/model-designing-specification
[5] 模型接口:https://docs.dify.ai/zh-hans/plugins/api-documentation/model/mo-xing-jie-kou
[6] AIModelEntity:https://docs.dify.ai/zh-hans/plugins/api-documentation/model/model-designing-specification#aimodelentity
[7] Xinference企业版和开源版本的对比:https://xorbits.cn/features
[8] Dify中的自定义模型插件开发例子:以xinference为例(原文链接):https://z0yrmerhgi8.feishu.cn/wiki/Wi9Rw5lCPiNgUTkpkO5c3M5vn6d
(文:NLP工程化)