
数百万文本块塞进MP4文件,还能闪电语义搜索!
GitHub上一个叫Memvid的开源项目,这次要颠覆我们对AI 记忆存储的认知——
它声称可以用MP4 视频文件完全替代昂贵的向量数据库,而且检索速度还能达到亚秒级。
你可能会问:
什么?MP4 不是我看小电影的视频文件格式吗,这和向量数据库、和AI 记忆有什么关系?

这个听起来像是愚人节玩笑的项目,却在技术圈引发了轩然大波。
MP4 数据库?
Memvid的核心思想看似疯狂,但其实也挺简单的——
它把文本数据编码成视频,让你能在数百万个文本块中进行闪电般的语义搜索。
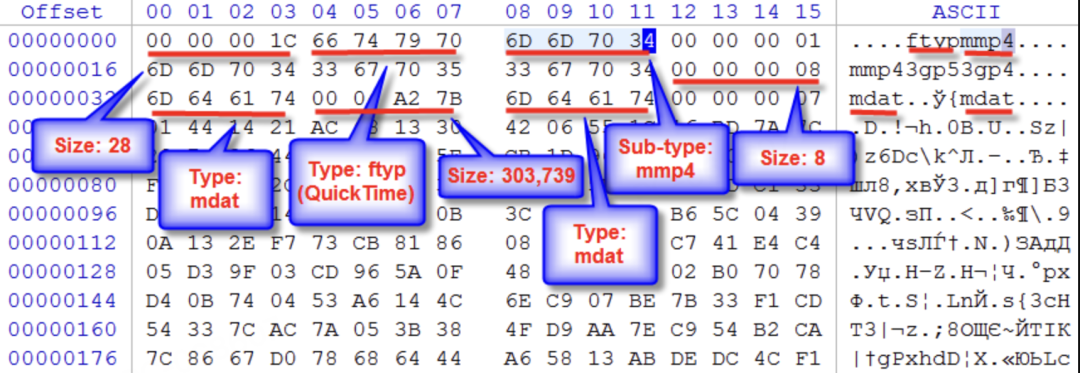
具体来说,它采用了一种巧妙的编码方案:每个文本块被转换成QR码图像,这些图像成为视频的帧。通过利用MP4的视频压缩算法,可以实现比传统文本存储高10倍的压缩率。
同时,系统会生成一个配套的JSON索引文件,记录每个文本块在视频中的位置信息。最关键的是,它使用sentence-transformers生成文本嵌入,通过FAISS进行相似度计算,实现语义搜索功能。
从技术架构来看,Memvid实际上是一个混合系统:视频文件负责存储原始数据,而向量索引负责实现快速检索。
这意味着,你可以把整个图书馆装进一个MP4文件里,然后用自然语言瞬间找到任何信息。
重要的是,这个系统完全开源免费,不需要任何数据库服务器,就是一个你可以随便复制的视频文件。
项目地址在:https://github.com/Olow304/memvid
技术细节
根据项目源码分析,Memvid的工作流程相当精妙。
在编码阶段,系统首先对文本进行分块处理:
# 文本块处理
encoder = MemvidEncoder(chunk_size=512, overlap=50)
encoder.add_chunks(text_chunks)
# 生成视频参数
encoder.build_video(
"output.mp4",
"index.json",
fps=30, # 每秒30帧 = 每秒30个文本块
frame_size=512 # 帧尺寸决定单帧数据量
)
在检索阶段,当用户输入查询时,系统会生成查询嵌入向量,然后FAISS在索引中找到最相似的文本块ID。
接着根据索引定位到视频中的具体帧,最后解码QR码还原文本内容。
这种设计的精妙之处在于:视频格式提供了极致的压缩和可移植性,而向量索引保证了检索性能。
性能数据亮眼
项目文档中展示的性能指标数据相当亮眼。项目中提供了与传统解决方案的详细对比:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在存储效率方面,100万个文本块(每块512字符)压缩后仅需约1GB存储空间,相比传统向量数据库节省90%以上的存储成本。
如果使用H.265编码,还能进一步提升压缩率。
检索速度同样出色:
-
语义搜索响应时间:<100ms
-
批量检索吞吐量:10000+ queries/second
-
支持并行处理和分布式架构
在扩展性上,单个MP4文件可存储数百万文本块,支持多文件分片存储更大规模数据,还可以通过调整FPS和帧大小优化存储密度。
争议与分析
Pierce Freeman(@piercefreeman)对这个项目进行了深入剖析,他指出了几个关键问题:
「这只是把文本存储为视频文件中的图像。它有一个单独的FAISS查找用于向量相似度搜索。FAISS仍然是一个向量数据库。视频只是文本的QR码存储。」
他的分析揭示了Memvid的真实架构——
文本嵌入和存储在FAISS索引中(memvid/index.py),FAISS缓存被写出为单独的.faiss文件,MP4只是作为文本的存储介质,而非真正的「数据库」。
但这并不意味着Memvid毫无价值。
它的创新点在于提供了独特的存储方案,将文本编码为视频是一种新颖的数据持久化方式。同时,视频编码器经过数十年优化,压缩效率极高。单个MP4文件包含所有数据,易于分发和备份。
更有意思的是,它可以从云存储直接流式传输,无需下载整个数据库。
实用场景
Memvid特别适合离线知识库的构建。根据项目文档,Memvid的应用场景包括:
数字图书馆:将数千本书索引到单个视频文件中。
教育内容:创建可搜索的课程材料视频记忆。
新闻档案:将多年的文章压缩成可管理的视频数据库。
企业知识库:构建全公司范围的可搜索知识库。
研究论文:在科学文献中快速进行语义搜索。
个人笔记:将你的笔记转换成可搜索的AI助手。
比如构建一个离线医学知识库:
# 构建离线医学知识库
encoder = MemvidEncoder()
encoder.add_pdf("medical_textbook.pdf")
encoder.add_pdf("drug_reference.pdf")
encoder.build_video("medical_kb.mp4", "medical_index.json")
# 离线查询
chat = MemvidChat("medical_kb.mp4", "medical_index.json")
response = chat.chat("青霉素的副作用有哪些?")
在边缘计算部署场景中,Memvid可以用于IoT设备上的本地知识库、无网络环境下的智能助手,以及移动设备上的大规模文本搜索。
对于内容分发网络,用户可以将知识库上传到CDN,实现流式访问而无需下载完整文件。
社区思考
技术社区的反应呈现出有趣的两极分化。
震惊派的代表Gillinghammer(@gillinghammer)直接问道:「什么鬼?」
Eru(@MysticEru)质疑:「这真的能和传统方案一样好用吗?」
RussellThor(@russellthor)更是表示:「Grok都给不出合理解释」。
兴奋派则完全是另一种态度。
m.r.(@86reality)兴奋地说:「我就知道会有这一天!」
hidE ☢️(@hide_oficial)更是脑洞大开:「你知道吗,有了这个你可以把数据库上传到YouTube等平台供全世界使用。天哪!」
理性分析派则在深入探讨技术细节。
atharv(@atharvvvg)问Pierce Freeman:「那你推荐用什么替代方案?」
Ewan Makepeace(@ewanmakepeace)提出:「我们是否在利用Apple Silicon等硬件对视频处理的定制支持?」
这也是技术社区对创新的不同态度——
有人看到潜力,有人质疑可行性,有人深入分析技术细节。
技术栈与依赖分析
Memvid的技术选择相当务实,使用了一系列成熟的开源技术:
-
sentence-transformers:用于语义搜索的最先进嵌入技术 -
OpenCV:计算机视觉和视频处理 -
qrcode:QR码生成 -
FAISS:高效的相似性搜索 -
PyPDF2:PDF文本提取
虽然Pierce Freeman指出它实际上还是使用了FAISS作为向量索引,但将文本编码到视频中这个想法本身就充满了创意。这种方法可能在某些特定场景下有其独特优势,比如易于分发、单文件存储等。
在可选组件方面,项目支持通过Docker容器使用H.265编码器获得更高压缩率,可以使用任何兼容的transformer模型作为自定义嵌入模型,还支持多worker 并行处理大规模数据。
性能优化
项目提供了多种优化手段。
在视频参数调优方面,可以通过提高帧率增加存储密度,减小帧尺寸降低文件大小,使用更高效的编码器,以及调整压缩质量参数:
# 最大压缩配置
encoder.build_video(
"compressed.mp4",
"index.json",
fps=60, # 提高帧率增加存储密度
frame_size=256, # 减小帧尺寸降低文件大小
video_codec='h265', # 使用更高效的编码器
crf=28 # 压缩质量参数(越低质量越高)
)
对于大规模数据处理,可以利用多核CPU加速:
# 利用多核CPU加速处理
encoder = MemvidEncoder(n_workers=8)
encoder.add_chunks_parallel(massive_chunk_list)
如果需要更强大的语义搜索能力,还可以使用自定义嵌入模型。
局限与展望
尽管Memvid展现了创新思维,但它也有明显的局限性。
虽然支持百万级文本块,但对于十亿级数据仍然力不从心。视频格式不支持高效的增量更新,每次修改都需要重新编码。
它只支持语义相似度搜索,不支持复杂的结构化查询。而且本质上仍然需要向量索引,只是存储介质创新。
但这个项目的意义远超其实用性。
它展示了跨界思维的力量——谁能想到成熟的视频编码技术可以用来存储文本数据库?
@drip(@patekgonia)提出了一个有趣的想法:
有没有办法提取让它快速的部分,并将其嵌入到新格式中?也许我们应该有aip4格式?
这或许是个可能的新方向:专门为AI 记忆存储设计的新文件格式。
Memvid可能不会真正「干掉」向量数据库,但它确实为我们打开了一扇窗——
在AI 时代,连最基础的数据存储方式都可能会被改造。
(文:AGI Hunt)