
今天是2025年6月10日,星期二,北京,晴
我们继续回到文档解析话题,来看看在真实使用场景中,会出现哪些问题,例如ppocrv5模型的具体表现?布局检测的问题?阅读顺序的问题?文档背景的干扰问题?文档目录层级解析问题?长表格的拼接问题等等。
我们可以将其归并为文档解析处理中的检测问题和语义解析问题两大块内容,共计8个小问题。
一、文档解析处理中的检测问题
检测问题,主要包括布局检测以及阅读顺序问题。
1、布局检测和公式检测使用了两个模型的逻辑:https://github.com/opendatalab/PDF-Extract-Kit/issues/206
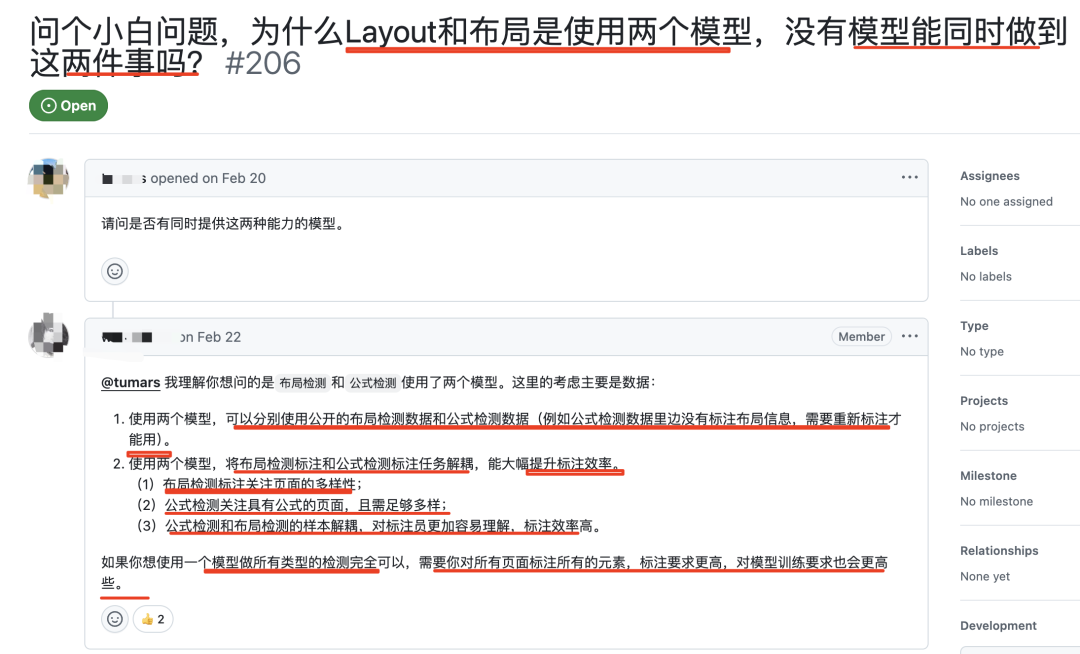
实际上,在进行文档布局检测的时候,的确要根据不同的对象特征进行区分对待,使用两个模型,可以分别使用公开的布局检测数据和公式检测数据(例如公式检测数据里边没有标注布局信息,需要重新标注才能用)。
使用两个模型,将布局检测标注和公式检测标注任务解耦,能大幅提升标注效率。布局检测标注关注页面的多样性;公式检测关注具有公式的页面,且需足够多样;公式检测和布局检测的样本解耦,对标注员更加容易理解,标注效率高。
2、布局检测的问题,这说的是模型泛化性的问题。https://github.com/opendatalab/MinerU/issues/2303,

这种问题是因为文档block块之间的间距太大了,判定为一个整体的特征并不明显。至于解法,可以补充相应的数据集。
3、阅读顺序的错误识别问题
还有版面分析左右布局阅读顺序的识别错误,https://github.com/opendatalab/MinerU/issues/1882

又如:
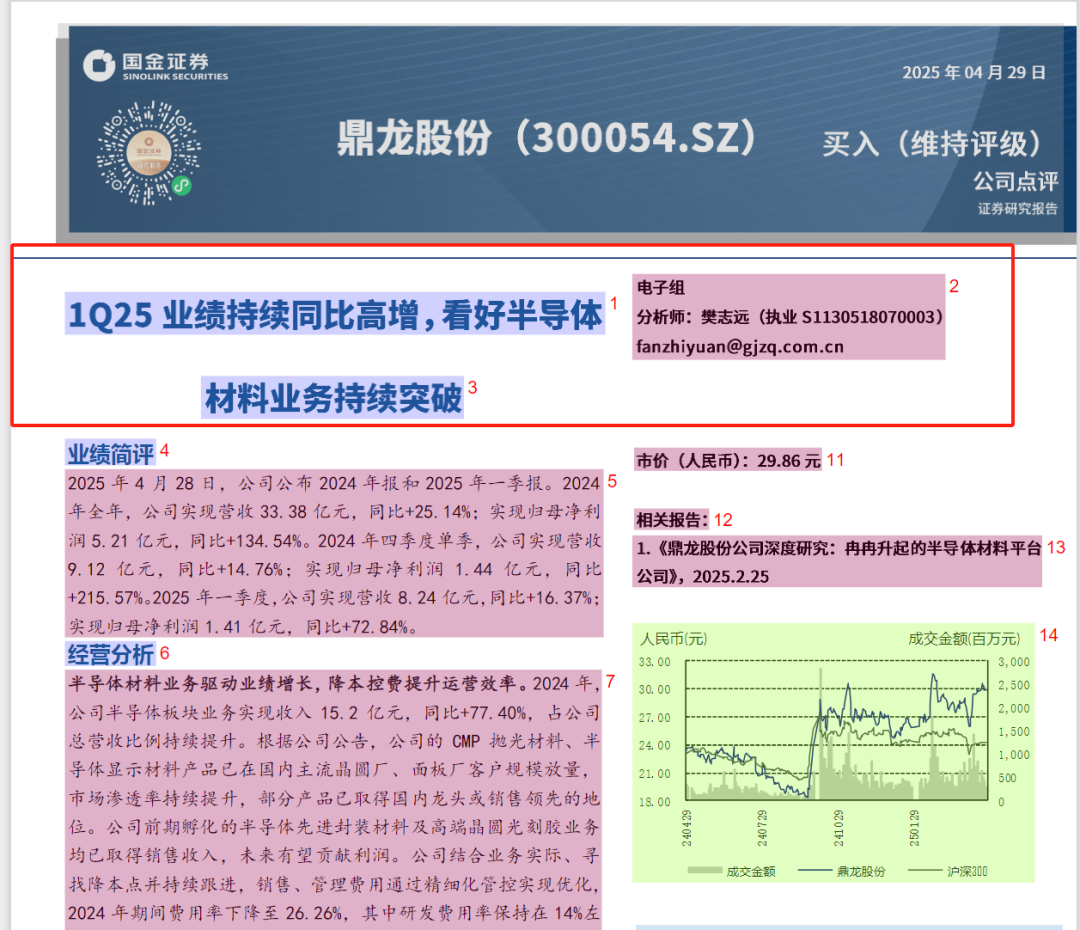
基于这种检测手段,在后续解析的过程中,会明显出现对标题截断分成了两个标题的情况,并且中间还存在标题右侧的相关信息。
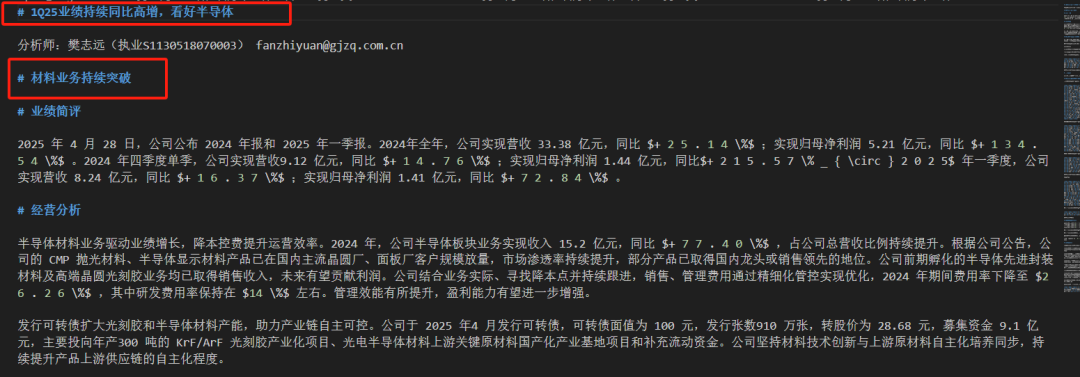
而至于阅读顺序,这个一直是文档处理的很难甚至说不太成立的事情,单纯的xycut规则适用性不强,需要做特定的layoutreader处理,又如下面的这个干扰性问题:

二、文档解析中的语义解析问题
语义解析问题,具体包括ocr、语义合并、文档层级结构以及长表格合并问题。
1、ppocrv5模型的更新测试结论,https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md

结论就是:ppocrv5(server)对手写文档效果有一定提升,但在其余类别文档的精度略差于v4_server_doc,由于ppocrv5强化了手写场景和特殊字符的识别能力,因此可以在日繁混合场景以及手写文档场景下选择使用ppocrv5模型
2、文档背景的干扰问题。段落结束,会莫名出现几个乱码或字符,可能是纸张背面的文字,这个问题也蛮有趣的,https://github.com/opendatalab/MinerU/issues/2515
这个的确是文档图像质量的问题,图像不干净,就会带来更大噪声,至于解法,可以做个背景去噪。
3、语义合并的问题,一个跨页正文合并策略的问题,https://github.com/opendatalab/MinerU/issues/2480,正文合并,比如单双栏,目前是通过规则进行合并的,大部分情况下可以合并的段落宽度会比较接近,因此我们加入了段落宽度的限制,以避免合并不该合并的段落,但是规则本身所覆盖的场景并不是很够,所以,通常还是需要上学习模型,比如序列标注,判定转移概率。
4、文档层级结构问题
因为层级结构,在目前pipeline的方案上,能够获取的输入信息,只有布局检测后的结果,也就是只有title标签,那么,如果想燃title进一步细分出多级的标签,最直接的方式,就是将title自动变成多级的,当然还是需要借助大模型进行处理,例如:https://github.com/opendatalab/MinerU/blob/dev/magic_pdf/post_proc/llm_aided.py

输入的内容是一篇文档中所有标题组成的字典,请根据以下指南优化标题的结果,使结果符合正常文档的层次结构。
当然,除了这种基于大模型的方案,还有其他的一些基于规则的做法,例如:
由于标题识别之后可以知道标题的bbox的高度,根据高度进行聚合,进行排序, 但是,一篇文档的字体大小完全是不受限制的,文中出现的字体大小可能有非常多,且正文页完全有可能比标题还大或者相同;
又如,针对标题层级的提取,只能根据特定的文档格式按照规则进行提取,不太能有普世的提取方式。例如:针对国内的一些金融行业的投研文档可以按照特定的标题格式提取,按照规则设定标题等级,对于字体大小这种方式,在本地也测试过,一是文档的字体大小不受限制,对于页眉页脚这种瞎搞的,在统计当页的字体大小的时候,就需要去除不符合要求的异常数据,确实是比较难搞,而且在转成pdf后,很多文本型pdf是丢失了层级信息。所以,标题的形式太多了,段落间距,字体,颜色,粗细,背景都能决定是不是标题。很难有普世的方法。
5、跨页长表格解析问题
表格问题也是常见的一类解析问题,尤其是跨页表格的问题,如https://github.com/opendatalab/MinerU/issues/1344,当前跨页解析结果生成了多个表格,跨页的生成的表格没有表头数据。处理方式是,跨页表格能生成一个表格或者可以生成多个表格,但是每个表格要有表头。
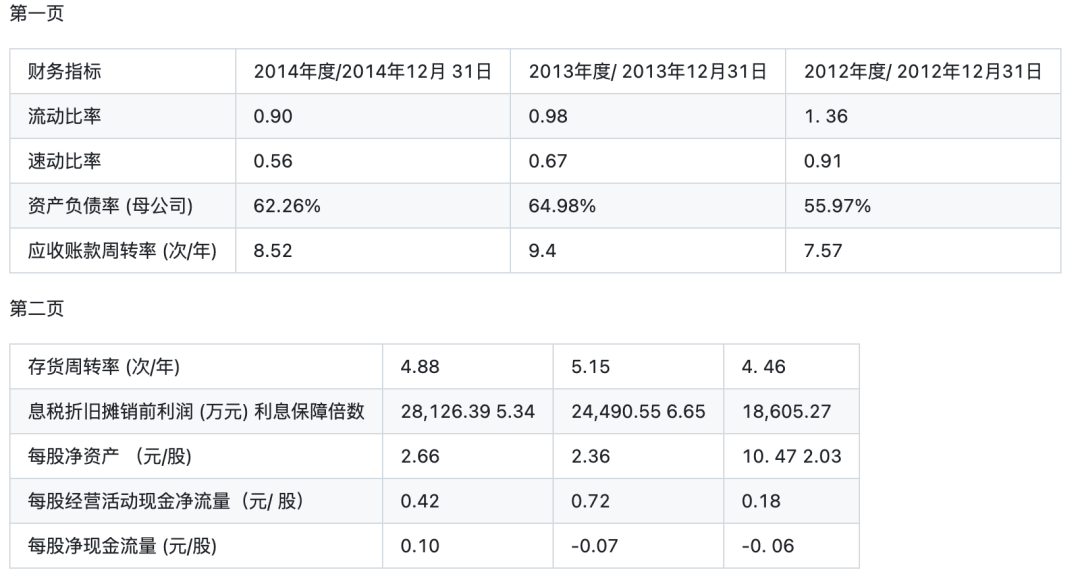
对于这种情况,可以加一个后处理规则,加了个手动处理的逻辑,判断相邻表格,如果表格间没有换行符之外的其他符号,且表格的最大列数一致,则认为这两个表格应该合并。
具体的,拿到解析结果之后:正则检索markdown中所有table标签,如果两个table之间没有除了换行、空格之外的其他符号,且table的最大列数一致且content.json里边的这两个表格不在同一页,就认为是同一个表格,将第二个表格拼接到一起。
(文:老刘说NLP)