
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
1.93bit量化之后的 DeepSeek-R1(0528),编程能力依然能超过Claude 4 Sonnet?
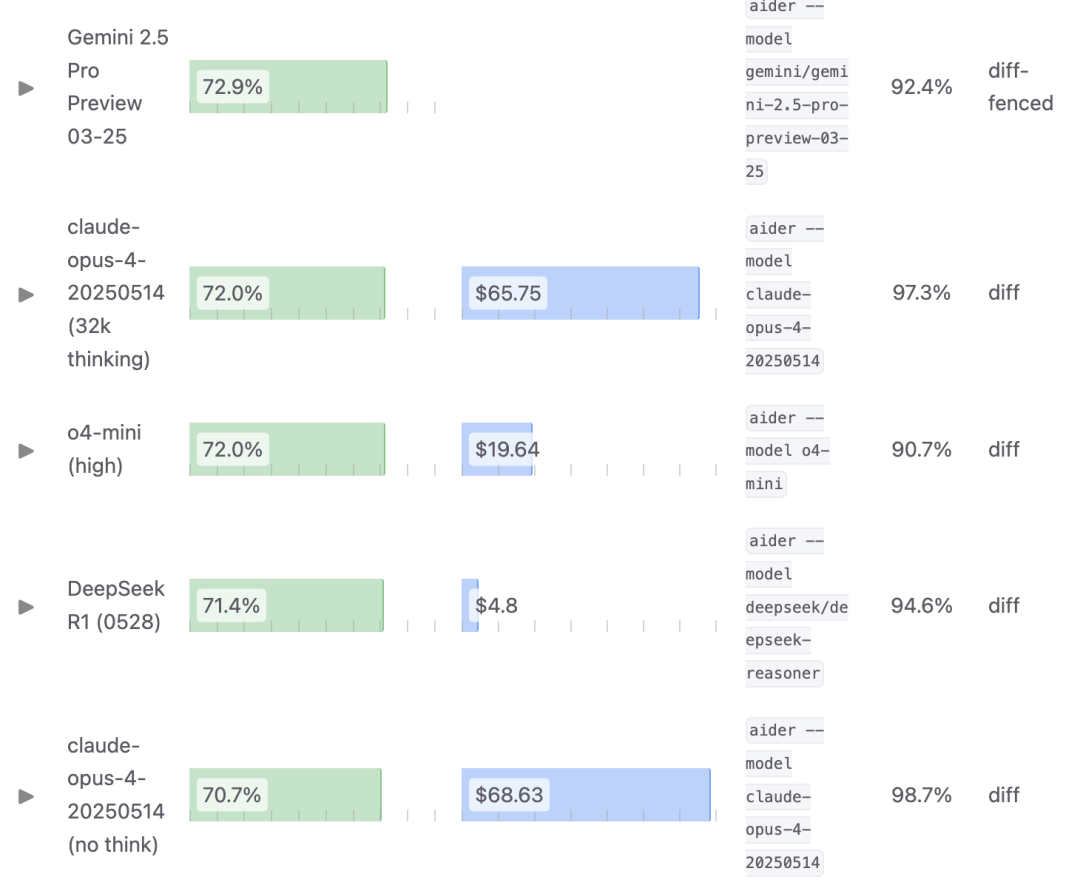
最新优化版R1在编程榜单aider上取得了60%的成绩,不仅超过了Claude 4 Sonnet的56.4分,也超过了1月版的满血R1。
并且aider是一个接近现实软件工程任务的榜单,不是靠做题就能取胜。

△图中R1为一月份的0120满血版
体积方面,相比8bit原始版,这个1.93bit版本,文件大小降低了70%以上。
看到如此轻量级的版本能有这样的表现,连作者本人都感到震惊。
而R1-0528的满血版在aider上则是取得了71.4分,超过了不开启思考的Claude 4 Opus。
量化版R1,不用GPU也能跑
这个量化版本来自Unsloth工作室,从1.66到5.5bit,Unsloth一共制作了9个量化版本。
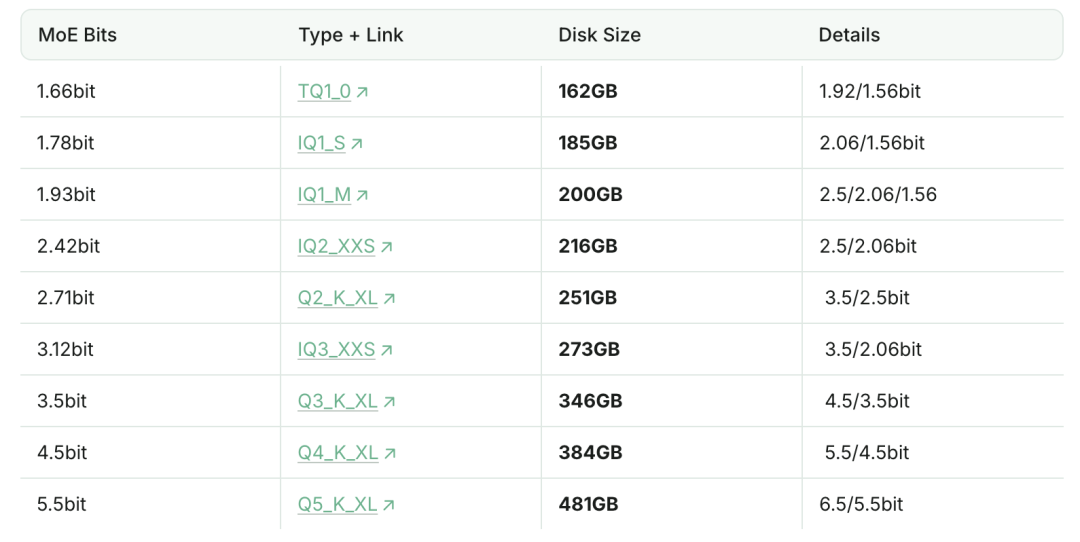
最小的1.66bit版,gguf文件大小仅162GB,比8bit版减小了近80%,1.93bit版也减小了70%。
按照Unsloth的说法,较小的版本没显卡也能跑,比如1.x级中间的1.78bit版本搭配64GB内存,每秒可以跑1个token。
如果放进24GB显存的显卡(比如3090),搭配128GB内存可以跑到每秒5个token。
不过Unsloth还是推荐至少180GB的统一内存,或者RAM和显存加起来超过180GB也可以,这样速度可以提到每秒5个token以上。

对于其他版本,也给出了简单的计算方式——内存和显存加起来(或统一内存)不低于下载的文件大小。

在众多版本当中,为了实现更好的大小与精度平衡,Unsloth更建议使用2.4bit和2.7bit的版本。
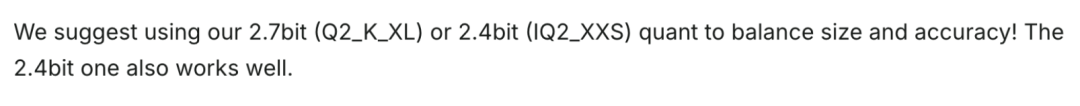
说完R1的这些量化版本,再来看看制作它们的Unsloth。
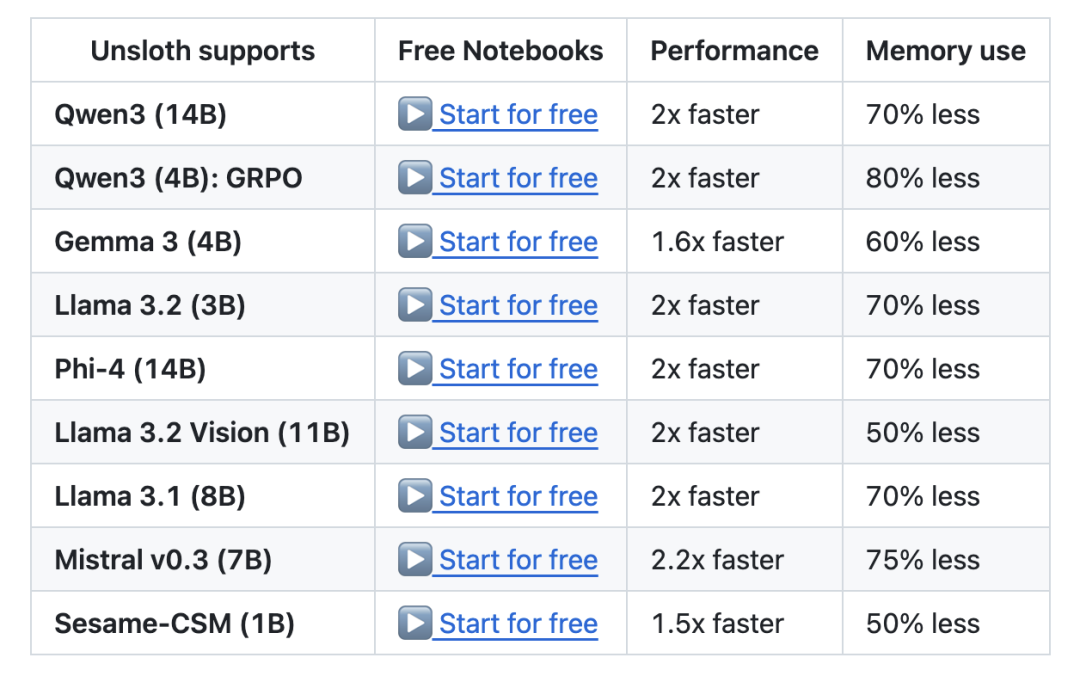
团队主要工作就是微调模型使其更高效运行,除了DeepSeek,阿里的Qwen、微软的Phi,还有Mistral、Llama也都被这个团队微调过。
这些模型当中,内存占用最少降低了一半,速度最少提升50%。
并且团队的GitHub仓库拥有4万多星标。
另外Unsloth这次还推出了用R1-0528蒸馏的Qwen3-8B模型,据介绍可以达到与Qwen3-235B相同的性能,并且“几乎可以适应任何配置”。

R1-0528打游戏超越o4-mini
说完量化,再看看R1本身。
一个名为Hao AI Lab的机构推出了一套让大模型玩人类游戏的评测基准Lmgame Bench,并公布了R1-0528取得的成绩。
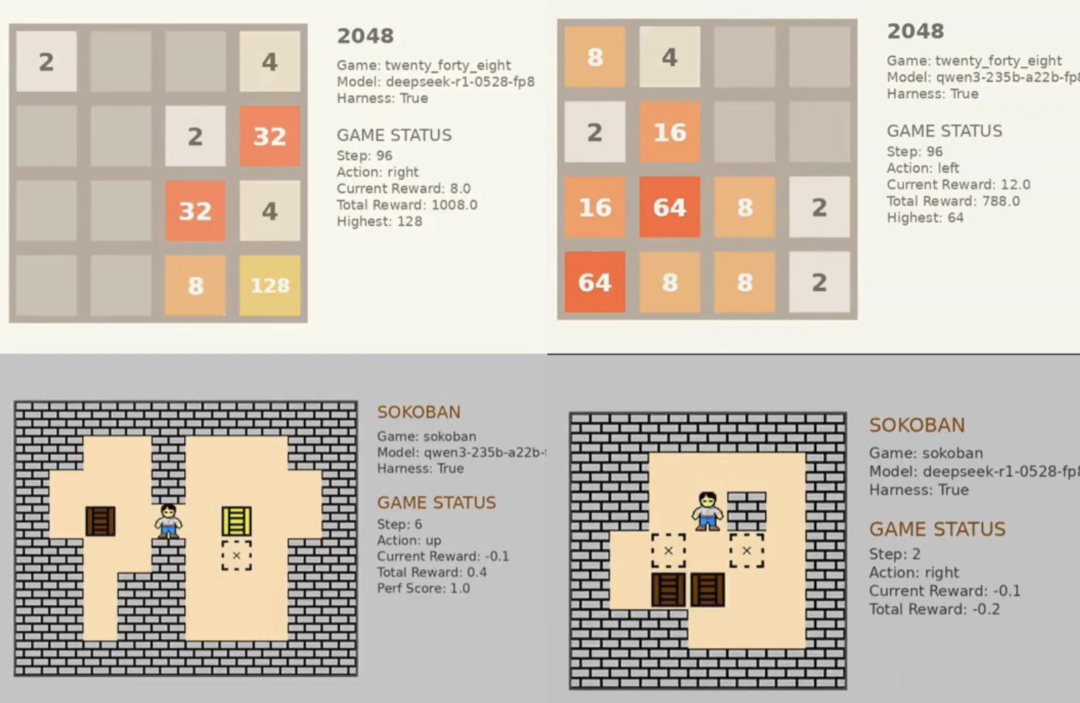
这套基准一共包含了六款游戏——俄罗斯方块、2048、推箱子、马里奥兄弟、逆转裁判和糖果传奇。
其中,和1月的版本比较,0528在俄罗斯方块上的提升非常明显。
如果和其他家模型相比,0528的俄罗斯方块成绩超过了o4-mini,仅次于o3。
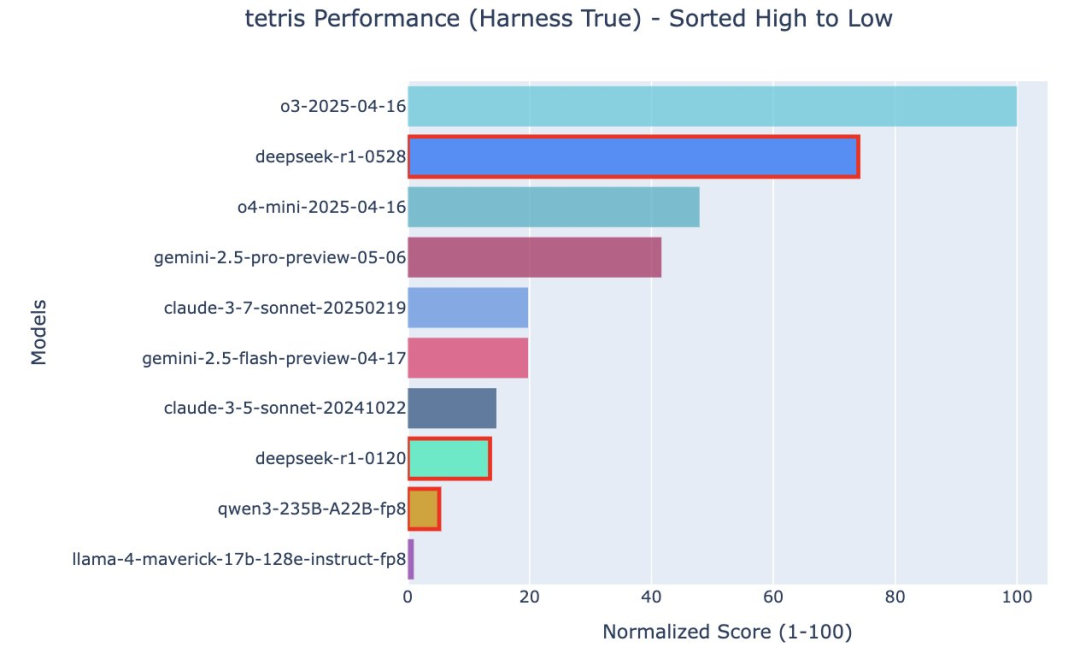
直观感受就是,四个模型同时开始游戏,而R1-0528坚持到了最后。

除了俄罗斯方块,R1-0528在推箱子、2048和糖果传奇上的表现也大幅超过1月版本,在糖果传奇中还名列前茅,仅次于最强的o3。
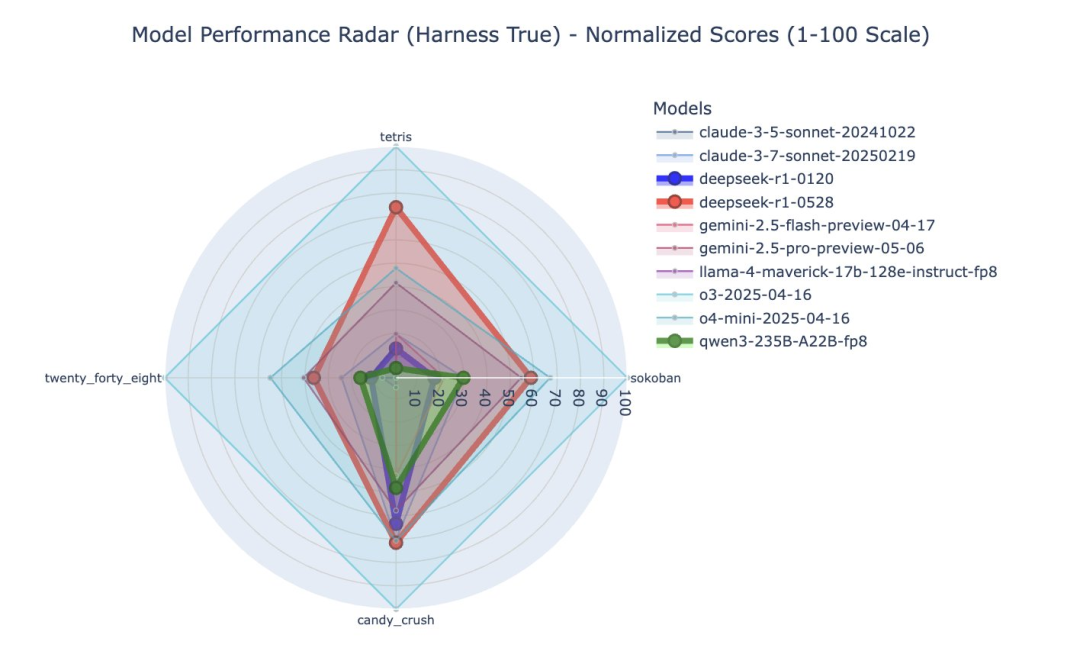
其中,2048、推箱子和俄罗斯方块一样,评价方法是看谁最后Game Over。
这里官方只展示了R1和Qwen的可视化对比。
而糖果传奇则是在规定的步数内看谁的得分最多,R1-0528取得了548分,领先o4-mini近20分。

你觉得R1还能挑战哪些人类游戏呢?
(文:量子位)