

在人工智能领域,语音识别和处理一直是研究热点。然而,传统的语音识别系统在复杂环境下的表现往往不尽如人意,尤其是在高噪声或多人说话的场景中。近年来,多模态学习逐渐成为解决这一问题的关键。通义联合深圳技术大学推出的CoGenAV模型,通过融合音频和视觉信息,为语音识别和处理带来了新的突破。

一、项目概述
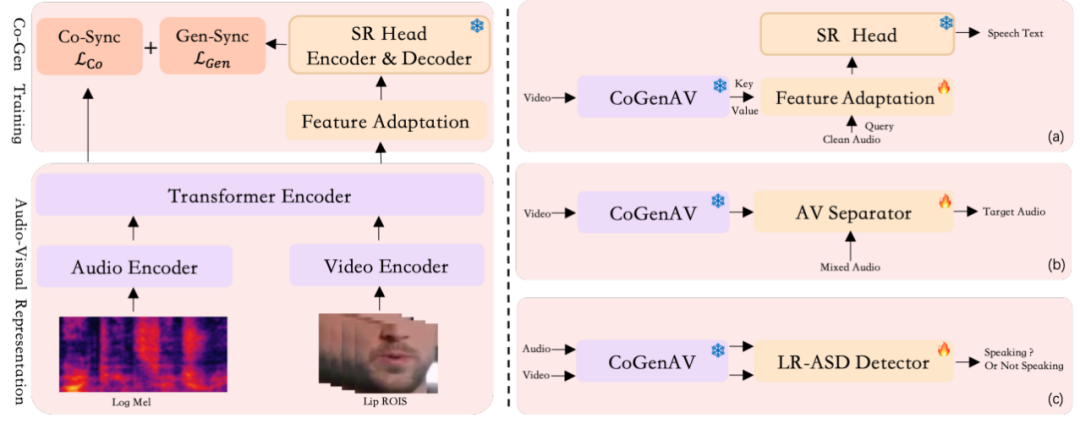
CoGenAV(Contrastive-Generative Audio-Visual Representation Learning)是由通义联合深圳技术大学共同开发的多模态学习模型,专注于音频和视觉信号的对齐与融合。该模型通过对比特征对齐和生成文本预测的双重目标进行训练,利用同步音频、视频和文本数据,学习捕捉时间对应关系和语义信息。CoGenAV仅需223小时的标记数据即可训练,展现出极高的数据效率,并在多种语音处理任务中表现出色。
二、技术原理
(一)特征提取
CoGenAV采用ResNet3D CNN分析视频中说话人的唇部动作,捕捉声音与口型之间的动态关联。同时,使用Transformer编码器从音频中提取语音信息,将音视频特征精确对齐。
(二)对比同步
CoGenAV采用Seq2Seq Contrastive Learning方法,通过最大化音频和视频特征之间的余弦相似性,增强两者之间的对应关系。引入ReLU激活函数过滤干扰帧,提升模型在复杂环境下的稳定性。
(三)生成同步
借助预训练的ASR模型(如Whisper),将音视频特征与其声学–文本表示对齐。通过设计轻量级适配模块(Delta Upsampler + GatedFFN MHA),有效提升跨模态融合效率。
三、主要功能
(一)音频视觉语音识别(AVSR)
CoGenAV 能够将音频和视觉信息(如说话者的嘴部动作)相结合,从而提高语音识别的准确率。在嘈杂的环境中,这种方法尤其有效,因为它可以利用视觉线索来补充音频信息,使得语音识别更加准确。
(二)视觉语音识别(VSR)
在某些特殊情况下,如在嘈杂的环境中或者当音频信号不可用时,CoGenAV 可以仅使用视觉信息(如说话者的嘴部动作)进行语音识别。这项功能拓展了语音识别的应用场景,使得在没有音频输入的情况下也能进行一定程度的语音识别。
(三)噪声环境下的语音处理
面对高噪声环境,CoGenAV 通过融合视觉信息辅助音频信号,提高语音处理的鲁棒性。视觉信息能够为语音处理提供额外的上下文,帮助模型更好地理解语音内容,减少噪声的干扰。
(四)语音重建与增强
CoGenAV 还可以用于语音重建和增强任务。通过多模态信息融合,它能够改善语音质量,使得语音更加清晰、自然。这对于语音通信、语音助手等应用具有重要意义,可以提升用户体验。
(五)主动说话人检测(ASD)
通过分析音频和视觉信号,CoGenAV 能够检测当前正在说话的人。这对于多说话人的场景,如会议、访谈等,具有重要的应用价值。它可以自动识别出正在说话的人,为后续的语音处理和分析提供基础。
四、应用场景
(一)智能助手与机器人
CoGenAV 的多模态表征可以集成到智能助手和机器人中。在复杂环境中,例如在嘈杂的工厂车间,CoGenAV 能够更好地理解和响应语音指令。它可以通过分析说话者的嘴部动作和语音信号,准确地识别出指令内容,从而实现更加自然、高效的人机交互。
(二)视频内容分析
CoGenAV 在视频内容分析和理解方面具有广泛的应用前景。通过分析视频中的音频和视觉信息,CoGenAV 可以为视频生成更准确的字幕。这对于听障人士或者在嘈杂环境中观看视频的用户来说是一个巨大的福音。同时,CoGenAV 还可以用于内容推荐系统。根据视频中的语音内容和视觉信息,为用户推荐更加符合其兴趣的视频。例如,在一个视频平台上,CoGenAV 可以分析用户观看的视频中的主题、情感等信息,然后推荐类似的视频,提高用户的观看体验。
(三)工业应用
在工业环境中,CoGenAV 可以用于语音控制设备和语音监控等场景。例如,在一个繁忙的工厂车间,工人可以通过语音指令控制设备的运行,而 CoGenAV 可以通过多模态信息融合提高语音控制的准确性和鲁棒性。同时,在工业监控方面,CoGenAV 可以对工厂内的语音和视频信息进行实时分析,及时发现异常情况并发出警报,提高生产的安全性和效率。
(四)医疗健康
CoGenAV 在医疗设备中的语音交互方面具有重要的应用价值。例如,智能医疗助手可以通过 CoGenAV 更好地理解医护人员或患者的语音指令,从而提供更加准确的服务。此外,在语音控制的医疗设备中,CoGenAV 可以提高语音控制的可靠性,减少误操作的风险。例如,在手术室中,医生可以通过语音指令控制设备的参数设置,而 CoGenAV 可以确保语音指令的准确识别,提高手术的安全性和效率。
五、快速使用
(一)环境准备
安装必要的依赖库,确保Whisper和fairseq已正确安装:
pip install -r requirements.txtpip install -U openai-whispergit clone https://github.com/pytorch/fairseqcd fairseqpip install --editable ./
(二)推理实践
1. 音频视觉语音识别(AVSR)
import whisperfrom whisper.model import AudioEncoderfrom infer_vsr_avsr import cogenav_forwardfrom models.cogenav import CoGenAV# 加载CoGenAV模型cogenav = CoGenAV(cfg_file="config/base.yaml", model_tensor="weights/base_cogenav.pt")# 加载Whisper模型作为SR头SR_Head = whisper.load_model("small", download_root="weights/whisper/")SR_Head.encoder.adapter = cogenav.adapter.half()# 准备输入数据input_ids = cogenav(video, audio).permute(0, 2, 1) # 音频和视频输入# 使用Whisper模型进行解码result = whisper.decode(SR_Head, input_ids, options)[0]
2. 音频视觉语音分离(AVSS)
from models.cogenav import CoGenAVfrom models.sepformer import build_Sepformer# 加载CoGenAV模型cogenav = CoGenAV(cfg_file="config/base.yaml", model_tensor="weights/base_cogenav.pt")# 加载Sepformer模型作为分离头sepformer_head = build_Sepformer().cuda()# 使用唇部特征分离目标语音lip_feature = cogenav(video, None, use_upsampler=False)sep_wav = sepformer_head.forward(audio_mix, lip_feature)
(三)运行脚本
使用以下命令运行推理脚本:
python infer_vsr_avsr.py --input_type cogenav_av --model_size large --cogenav_ckpt weights/large_cogenav.ptpython infer_avse_avss.py --task_type avse
六、结语
CoGenAV作为一款先进的多模态语音表征模型,通过融合音频和视觉信息,显著提升了语音识别和处理的性能。其在多种任务中的出色表现,展示了多模态学习在语音领域的巨大潜力。未来,随着技术的进一步发展,CoGenAV有望在更多场景中发挥重要作用。
七、项目地址
技术论文:https://arxiv.org/pdf/2505.03186
GitHub仓库:https://github.com/HumanMLLM/CoGenAV
(文:小兵的AI视界)