

让 AI 像人一样理解世界并与环境互动。
Meta 重磅发布了 V-JEPA 2(Video Joint Embedding Predictive Architecture 2) 世界模型,并同时发布了三个全新的基准测试,用于评估现有模型通过视频对物理世界进行推理的能力。
这次,Meta 首席 AI 科学家 Yann LeCun 亲自出镜,并介绍了世界模型与其他模型的不同之处。
V-JEPA 2 是一款基于视频训练的先进 AI 系统,旨在赋予机器更深层次的物理世界理解、预测及交互能力,向着构建更通用的AI智能体迈出关键一步。
一经发布,便在 X 上引发了众多关注与讨论。

用百万小时视频打造「世界模型」
只靠 62 小时机器人数据就能上手控制
Meta 团队认为,未来 AI 的关键在于具备对现实世界进行计划与推理的能力,而“世界模型(World Models)”正是实现这一目标的核心路径。
此次,他们不仅开放了 V-JEPA 2 的模型代码与权重检查点,供研究与商业用途自由使用,也希望借此构建起更广泛的开源社区生态,推动世界模型领域的持续进展,加速 AI 与物理世界交互方式的革新。
V-JEPA 2 相关链接:
论文地址:https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
GitHub:https://github.com/facebookresearch/vjepa2
HuggingFace:https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6
V-JEPA 2 基于联合嵌入预测架构(JEPA)构建,核心由两大组件组成:
-
编码器(Encoder):接收原始视频输入,并输出嵌入表示,捕捉所观察世界状态中的关键语义信息;
-
预测器(Predictor):结合视频嵌入与具体的预测任务上下文,生成对应的预测嵌入结果。
-
在 Something-Something v2 动作识别任务中,仅通过冻结编码器特征并训练轻量注意力读出模型,V-JEPA 2 就取得了优异成绩。该任务强调对运动和操作行为的理解。 -
在 Epic-Kitchens-100 动作预测任务 中,通过冻结编码器和预测器,再训练注意力读出模块,V-JEPA 2 创造了新的 SOTA 纪录。该任务需要模型从第一人称视频中预测接下来 1 秒可能的动作(包括名词与动词)。 -
此外,将 V-JEPA 2 与语言模型结合,在视频问答基准任务上(如 Perception Test 和 TempCompass)也实现了领先的性能。

超 3000 人的「AI 产品及应用交流」社群,不错过 AI 产品风云!诚邀所有 AI 产品及应用从业者、产品经理、开发者和创业者,扫码加群:
进群后,您将有机会得到:

· 最新、最值得关注的 AI 产品资讯及大咖洞见
· 独家视频及文章解读 AGI 时代的产品方法论及实战经验
· 不定期赠送热门 AI 产品邀请码
-
短期任务(如物体拾取与放置):以图像形式设定目标,模型通过对当前状态与目标状态的嵌入,预测一系列动作后果,并实时重规划,执行最优动作。 -
长期任务(如将物体移动至指定位置):系统会设定一系列视觉子目标,机器人按顺序完成各阶段目标,类似人类的模仿学习过程。 -
最终,在完全新环境中,V-JEPA 2 在 新物体的拾取与放置任务中达成 65%~80% 的成功率,展示了“世界模型”在实现通用机器人智能方面的广阔潜力。

什么是世界模型?
-
理解(Understanding):AI的世界模型需能透彻理解对客观世界的观察,包括但不限于识别视频中的物体、行为及运动模式。 -
预测(Predicting):该模型应能准确预测世界的自然演化趋势,以及在智能体采取特定行动后世界可能发生的变化。 -
规划(Planning):基于其预测能力,世界模型必须能够有效地规划出一系列连贯行动,以实现预设的目标。

-
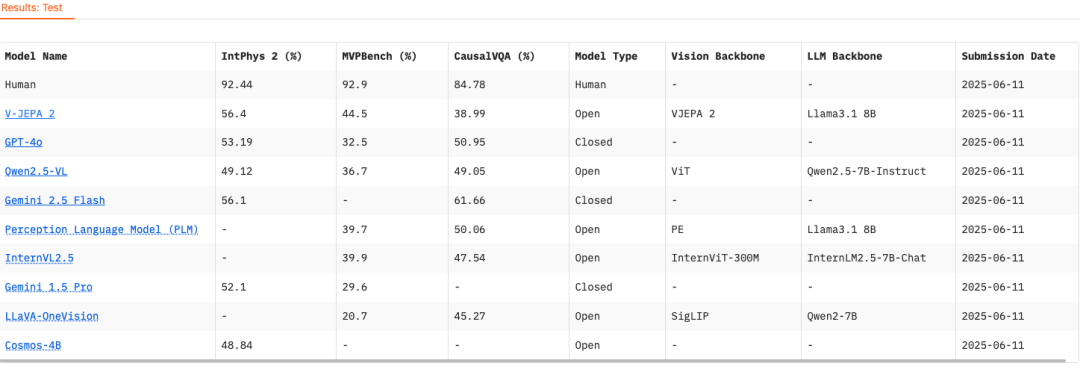
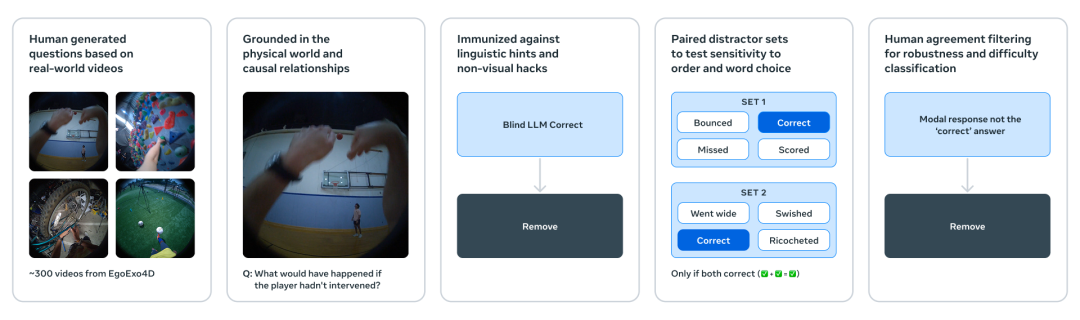
IntPhys 2:判断“哪一段违反了物理规律”,专注于测试模型是否具备直觉物理常识。
-
MVPBench 识别“细微差异下的真实因果”:通过构造一对几乎一致的视频和问题,迫使模型跳脱表层线索,真正理解视频中的物理因果关系。
-
CausalVQA:回答“如果、接下来、为了什么”,旨在测试视频模型对物理世界因果关系的理解深度

(文:AI科技大本营)