

新智元报道
新智元报道
【新智元导读】CVPR 2025奖项重磅揭晓!华人博士生王建元凭借创新论文摘得最佳论文奖。Hao Su、谢赛宁获年轻研究者奖,贾扬清十年前论文获「时间检验奖」。本届大会投稿量激增13%,接收率22.1%,全球超9000名学者齐聚,学术盛况空前。
就在刚刚,CVPR 2025大会最佳论文等奖项发布!
今年共有14篇论文入围最佳论文角逐,最终5篇脱颖而出:1篇摘得最佳论文奖,4篇获得最佳论文荣誉提名。
此外,还有1篇最佳学生论文和1篇最佳学生论文荣誉提名。
大会官方统计,今年的投稿量再创新高!
来自全球4万多名作者的13008篇论文蜂拥而至,比去年(11532篇)增长了13%。
最终,2872篇论文被接收,每篇论文由3位审稿人和1位领域主席评审,总体接收率为22.1%。
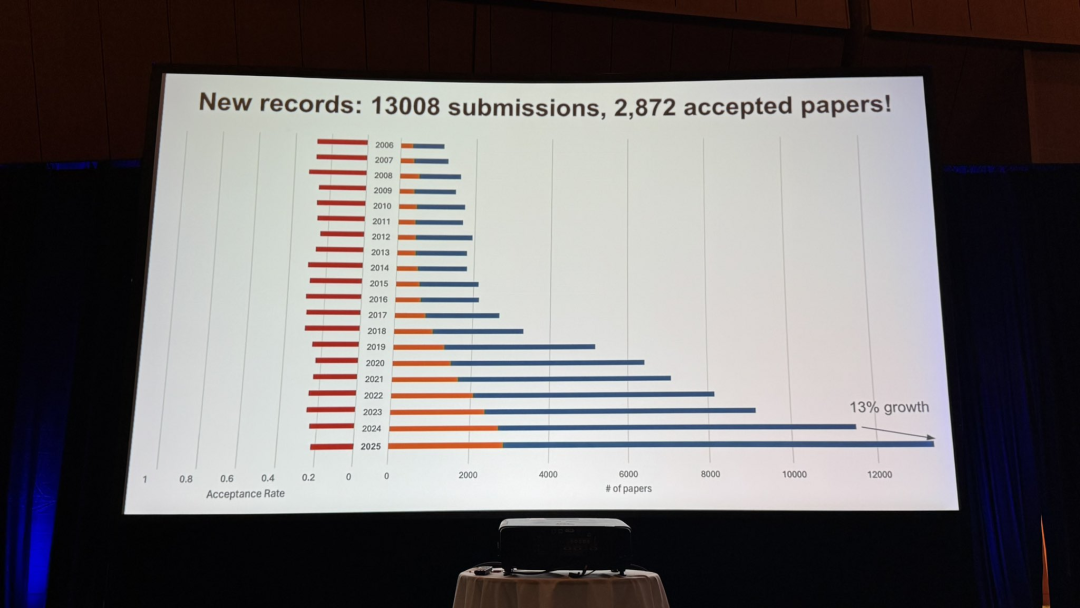
其中,96篇(3.3%)入选Oral报告,387篇(13.7%)被选为Highlight展示。

投稿作者、审稿人和领域主席(AC)的数量都创下了历史新高。
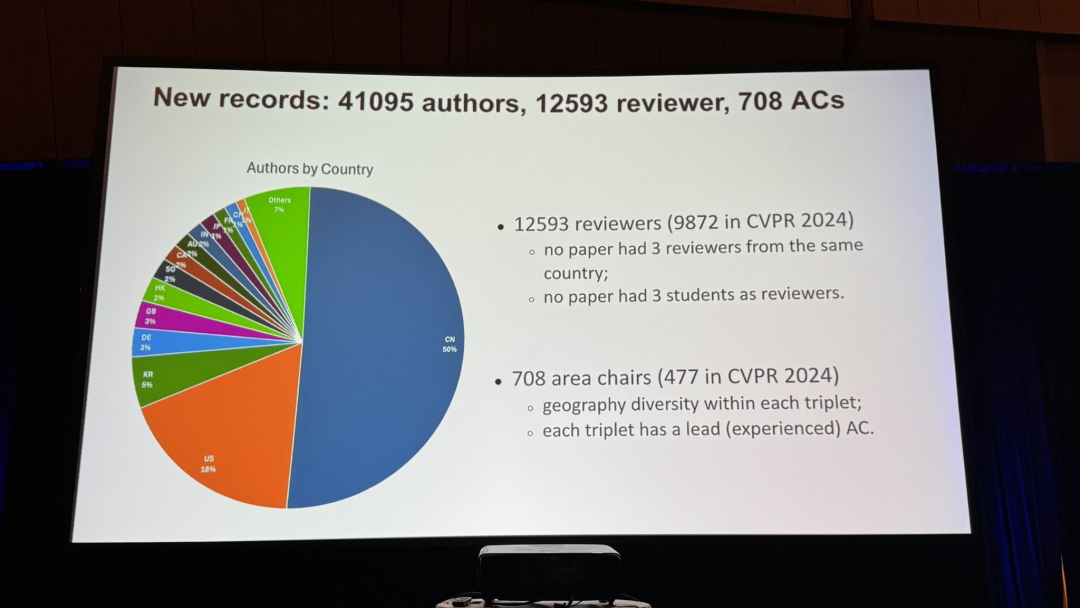
现场参会人数也相当壮观,超过9000名学者从70多个国家和地区赶来。
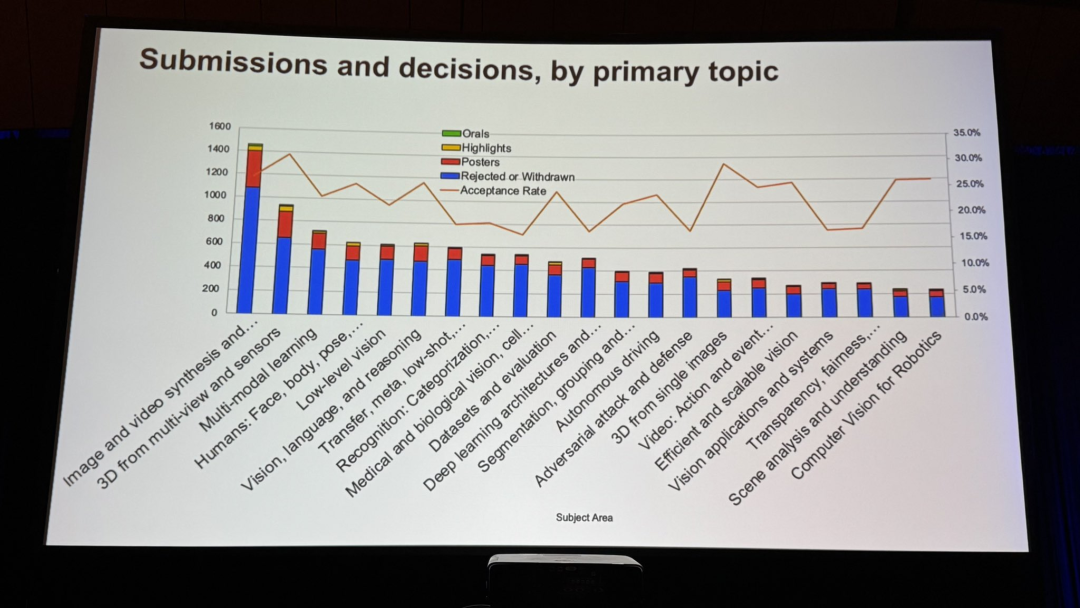
CVPR 2025官方还公布了各细分领域的论文接收情况:图像与视频生成领域的接收数量最多,而多视角/传感器3D和单图像3D领域的接收率最高。
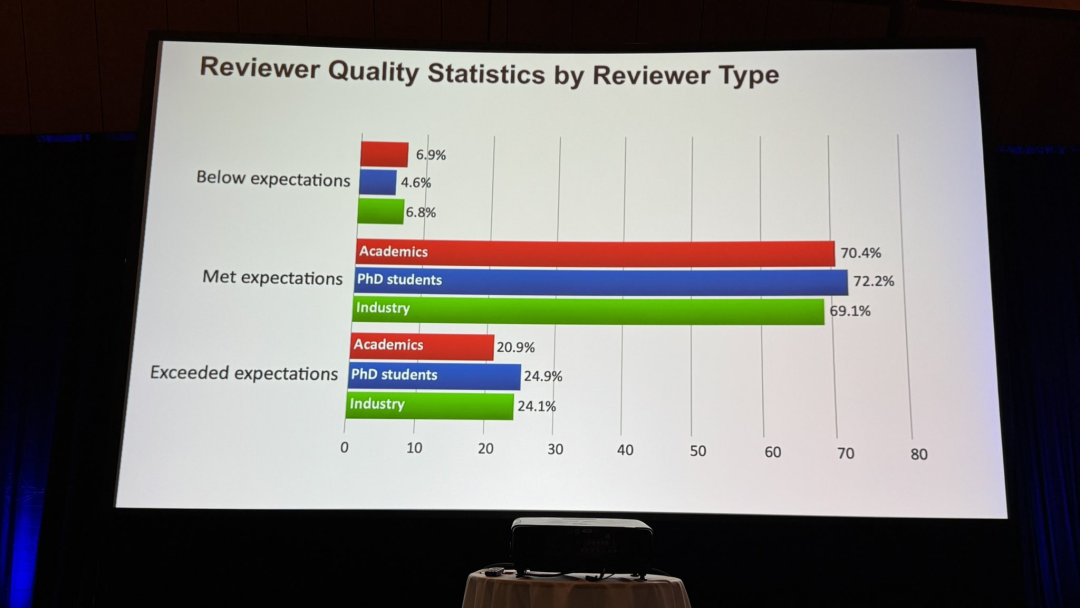
审稿人质量统计显示,学术界审稿人中有70.4%达到预期水平,PhD学生和产业界审稿人分别有24.9%和24.1%的表现超出预期,展现了较高水平的评审能力。
低于预期的比例则相对较低,学术界为6.9%、PhD学生为4.6%、产业界为6.8%,表明整体审稿质量较为稳定。
值得一提的是,最佳论文奖评审委员会中还有我们熟悉的AI大牛——ResNet的作者何恺明!

本次大会颁发了两个年轻研究者奖,获奖者分别是加州大学圣迭戈分校的副教授Hao Su和纽约大学计算机科学助理教授谢赛宁。
这个奖项每年都会颁给在计算机视觉领域有突出研究贡献的年轻学者,但获奖者拿到博士学位的时间不能超过七年。

Hao Su,北京航空航天大学应用数学博士,斯坦福大学数学与计算机科学博士,现在是加州大学圣迭戈分校的副教授。
他的研究方向很广,覆盖了计算机视觉、计算机图形学、机器学习、通用人工智能和机器人技术。
去年,他还参与创立了一家叫Hillbot的机器人公司,担任CTO。

谢赛宁,2013年从上海交通大学本科毕业,2018年在加州大学圣迭戈分校计算机科学与工程系拿到了博士学位,研究方向主要是深度学习和计算机视觉。
之后,他加入了Facebook人工智能研究室(FAIR)做研究科学家。
2022年,他和William Peebles一起发表了DiT论文,首次把Transformer和扩散模型结合了起来。

荣誉提名
获得荣誉提名的是Ishan Misra,在Meta的GenAI团队担任研究科学家主任,领导视频生成模型的研究工作。
在此之前,他在Meta的FAIR团队,专注于计算机视觉的自监督学习和多模态学习。
他在卡内基梅隆大学拿到了博士学位。2024年,因为在计算机视觉和机器学习方面的研究贡献,获得了卡内基梅隆大学颁发的近期校友成就奖。

作者:Jianyuan Wang,Minghao Chen,Nikita Karaev,Andrea Vedaldi,Christian Rupprecht,David Novotny
机构:牛津大学,Meta AI
论文地址:https://arxiv.org/abs/2503.11651
代码模型:https://github.com/facebookresearch/vggt
本次CVPR 2025最佳论文来自牛津大学、Meta AI,提出了一种前馈神经网络,能够从场景的单个、少量或数百个视图中直接推断出其所有关键三维属性,包括相机参数、点图、深度图和三维点轨迹。
在三维计算机视觉领域,模型通常仅限于并专用于单一任务,而这种方法代表了该领域的一大进步。
它还兼具简洁与高效的特点,能在一秒内完成图像重建,并且其性能优于那些需要采用视觉几何优化技术进行后处理的替代方案。
该网络在多项三维任务中均取得了SOTA的结果,包括相机参数估计、多视图深度估计、密集点云重建以及三维点跟踪。
文中还证明,使用预训练的VGGT作为特征主干网络,能显著增强下游任务的性能,例如非刚性点跟踪和前馈式新视角合成。

论文第一作者Jianyuan Wang为Facebook AI Research和牛津大学视觉几何组(VGG)的联合博士研究生。
他的博士研究专注于打造创新的端到端几何推理框架,主导开发了PoseDiffusion、VGGSfM,以及本次提出的通用3D基础模型VGGT。
同样是Jianyuan Wang作为第一作者的VGGSfM研究被CVPR 2024接收,并入选Highlight论文。
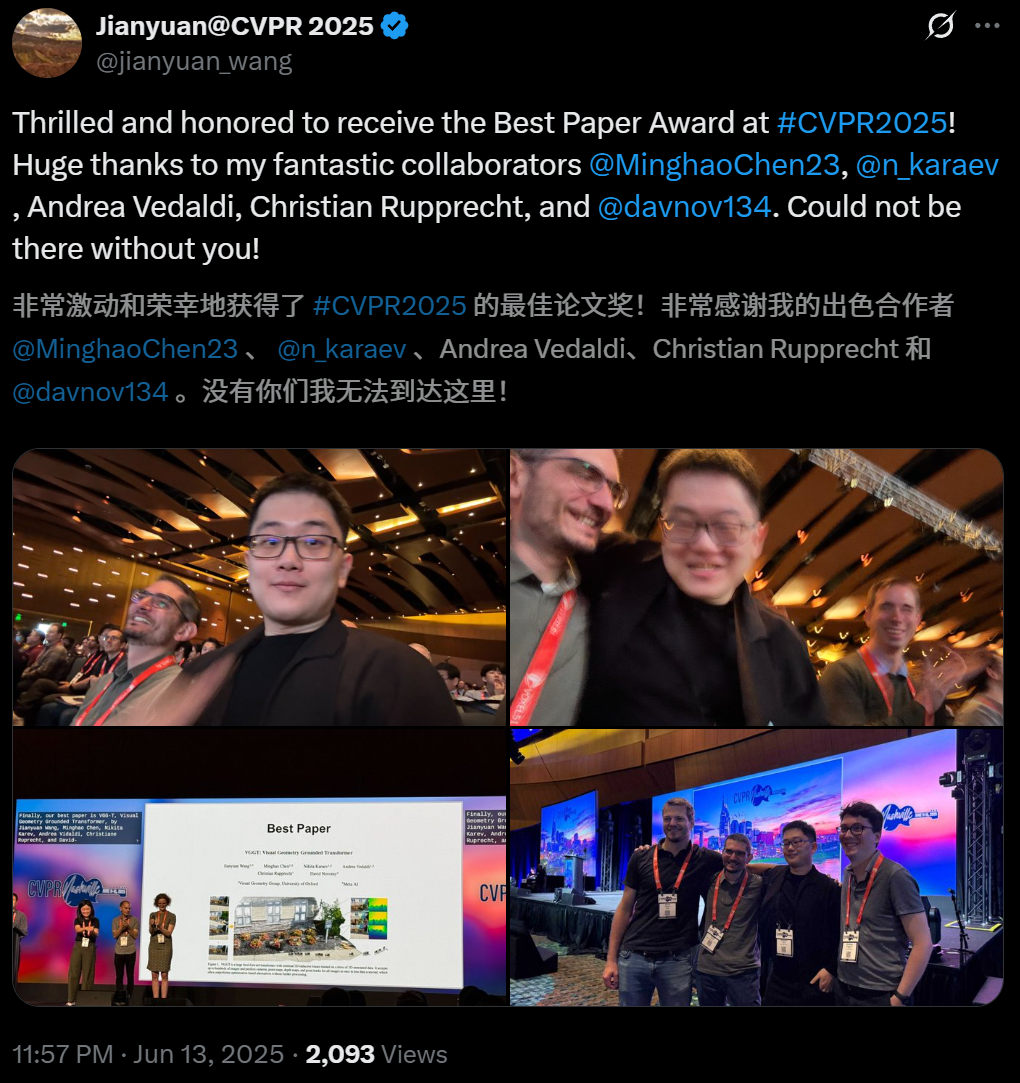
另一位华人作者Minghao Chen是牛津大学的博士生,导师是Andrea Vedaldi教授和Iro Laina博士。同时,也在Meta GenAI进行研究科学家实习。
此前,他曾在石溪大学攻读博士学位,师从Haibin Ling教授。期间在微软亚洲研究院实习,合作导师为Houwen Peng博士。
他分别在哥伦比亚大学获得硕士学位,在北京航空航天大学获得学士学位。

作者:Anagh Malik,Benjamin Attal,Andrew Xie,Matthew O’Toole,David B. Lindell
机构:多伦多大学,Vector Institute,卡内基梅隆大学
论文地址:https://arxiv.org/pdf/2506.05347
最佳学生论文来自多伦多大学、Vector Institute以及CMU,提出了基于物理的神经逆渲染,利用多视角视频中的光传播进行处理。
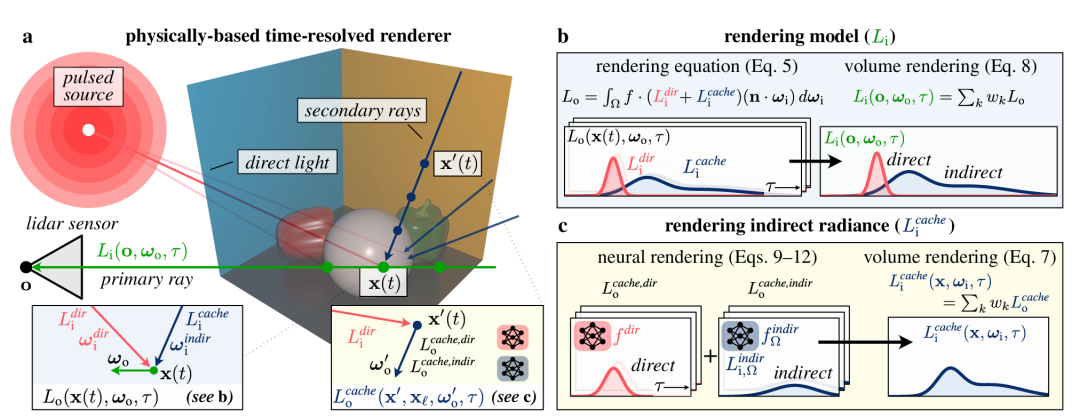
该方法依赖于神经辐射缓存的时序扩展技术——这种技术通过存储从任意方向到达任意点的无限次反射辐射来加速逆渲染。
由此生成模型能精确模拟直接和间接光传输效应,结合闪光激光雷达系统的捕捉数据,即使在强间接光环境下也能实现顶尖的3D重建。
此外,本文展示了光传播的视图合成、自动分解捕捉数据为直接和间接分量,以及对捕获场景进行多视图时间分辨重新照明等新功能。
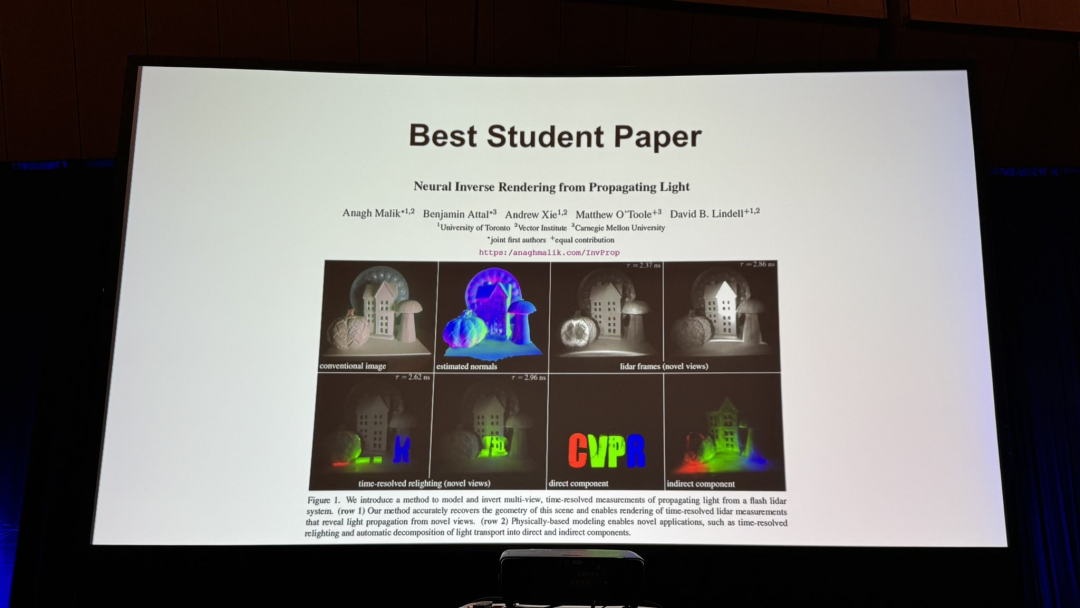
本文的时间分辨渲染器结合基于物理的主射线渲染和神经渲染的间接辐射缓存,计算传感器像素处的入射辐射。优化场景外观和几何形状,确保渲染与捕获测量一致。
与基线相比,本文中的方法能够恢复更准确的法线以及相似或更优的强度图像(见激光雷达帧插图中的箭头)。


论文1:MegaSaM: Accurate, Fast and Robust Structure and Motion from Casual Dynamic Videos
作者:Zhengqi Li,Richard Tucker,Forrester Cole,Qianqian Wang,Linyi Jin,Vickie Ye,Angjoo Kanazawa,Aleksander Holynski,Noah Snavely
机构:Google DeepMind,加州大学伯克利分校,密歇根大学
论文地址:https://arxiv.org/abs/2412.04463

论文2:Navigation World Models
作者:Amir Bar,Gaoyue Zhou,Danny Tran,Trevor Darrell,Yann LeCun
机构:Meta,纽约大学,伯克利AI研究院
论文地址:https://arxiv.org/abs/2412.03572

论文3:Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
作者:Matt Deitke,Christopher Clark,Sangho Lee,Rohun Tripathi,Yue Yang,Jae Sung Park,Reza Salehi,Niklas Muennighoff,Kyle Lo,Luca Soldaini,Jiasen Lu,Taira Anderson,Erin Bransom,Kiana Ehsani,Huong Ngo,Yen-Sung Chen,Ajay Patel,Mark Yatskar,Chris Callison-Burch,Andrew Head,Rose Hendrix,Favyen Bastani,Eli VanderBilt,Nathan Lambert,Yvonne Chou,Arnavi Chheda-Kothary,Jenna Sparks,Sam Skjonsberg,Michael Schmitz,Aaron Sarnat,Byron Bischoff,Pete Walsh,Christopher Newell,Piper Wolters,Tanmay Gupta,Kuo-Hao Zeng,Jon Borchardt,Dirk Groeneveld,Crystal Nam,Sophie Lebrecht,Caitlin Wittlif,Carissa Schoenick,Oscar Michel,Ranjay Krishna,Luca Weihs,Noah A. Smith,Hannaneh Hajishirzi,Ross Girshick,Ali Farhadi,Aniruddha Kembhavi
机构:艾伦人工智能研究所,华盛顿大学,宾夕法尼亚大学
论文地址:https://arxiv.org/abs/2409.17146

论文4:3D Student Splatting and Scooping
作者:Jialin Zhu,Jiangbei Yue,Feixiang He,He Wang
机构:伦敦大学学院
论文地址:https://arxiv.org/abs/2503.10148

论文:Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
作者:Kaihang Pan,Wang Lin,Zhongqi Yue,Tenglong Ao,Liyu Jia,Wei Zhao,Juncheng Li,Siliang Tang,Hanwang Zhang
机构:浙江大学,南洋理工大学,北京大学,华为新加坡研究所
论文地址:https://arxiv.org/abs/2504.14666
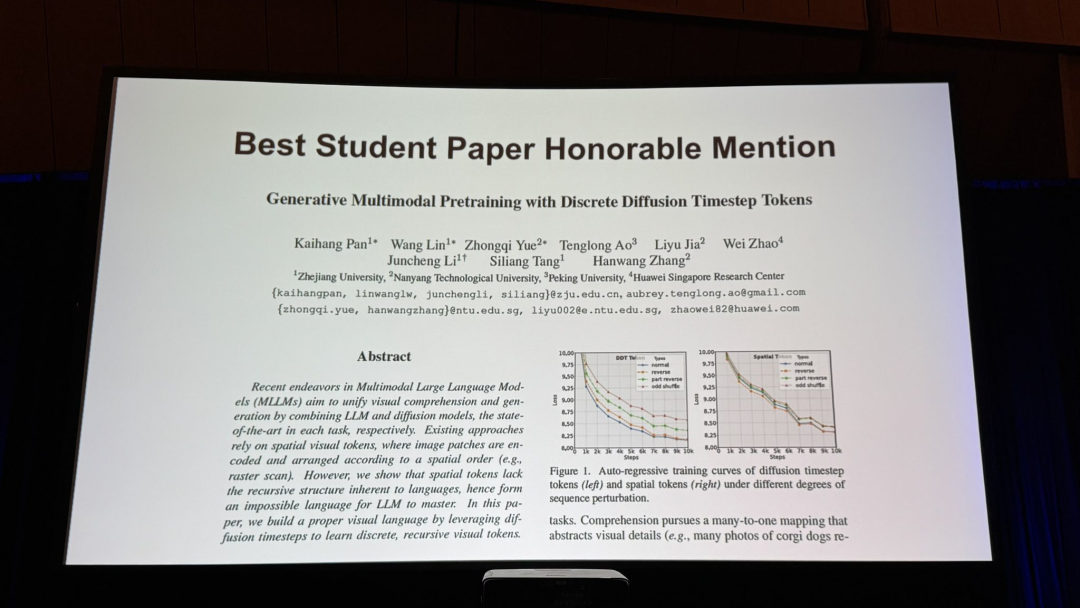
可以说,在整个最佳论文的候选名单中,不仅有大量的华人作者,还有很多来自国内的高校和机构。
比如浙江大学,西湖大学,香港中文大学,香港科技大学(广州),湖南大学,华中科技大学,南京大学,以及商汤等等。

完整名单:https://cvpr.thecvf.com/virtual/2025/events/AwardCandidates2025
(上下滑动查看)



上下滑动查看
Thomas S. Huang纪念奖表彰的是在科研、教学与指导以及为计算机视觉学术社区服务方面堪为楷模的研究人员。每年授予一名博士毕业至少7年的研究者,处于职业生涯中期(博士毕业不超过25年)的学者将获优先考虑。
该奖设立于CVPR 2020,自2021年起每年颁发一次,旨在纪念已故的Thomas S. Huang教授。
今年获奖的Kristen Grauman在FAIR担任研究科学家,同时也是德克萨斯大学奥斯汀分校计算机科学系的教授。
她于2006年获得了麻省理工学院的博士学位,是IEEE Fellow、AAAI Fellow、斯隆学者,并荣获了「计算机与思想奖」。
她的研究方向为计算机视觉与机器学习,专注于视觉识别、视频分析、第一人称视角感知和具身智能。

Longuet-Higgins奖以理论化学家和认知科学家H. Christopher Longuet-Higgins的名字命名,授予的是在10年前发表且对计算机视觉研究产生重大影响的CVPR论文。
今年获得该奖的论文共有两篇。据介绍,贾扬清参与的这篇论文有个更知名的名字——Inception或者Googlenet。当年模型的大小是6M参数,妥妥的小模型。
论文1:Going deeper with convolutions
作者:Christian Szegedy,Wei Liu,Yangqing Jia,Pierre Sermanet,Scott Reed,Dragomir Anguelov,Dumitru Erhan,Vincent Vanhoucke,Andrew Rabinovich
机构:谷歌,北卡罗来纳大学教堂山分校,密歇根大学

论文2:Fully Convolutional Networks for Semantic Segmentation
作者:Jonathan Long,Evan Shelhamer,Trevor Darrell
机构:加州大学伯克利分校

(文:新智元)