


极市导读
本文提出一种自回归多模态模型Orthus,可同时生成离散文本和连续图像特征。其通过特定的扩散头和语言模型头分别处理图像和文本,且构建策略高效,72 小时内就能基于 8 块 A100 GPU 训练出基础模型,该模型在多模态理解和生成任务中展现出优异效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
LLM 自回归做理解,Diffusion Loss 做生成的生成理解统一模型。
Orthus 是一种生成理解统一架构,可以做图像生成,基于视觉输入回答问题,以及交织多模态数据生成。Orthus 完全基于自回归的训练模式。对于 text token,使用离散建模,和大多数自回归模型保持一致;而对于 visual token,使用连续的图片特征。使用 continuous 的视觉表征最小化了图像理解和生成的信息损失,而自回归建模则使得多种模态之间的相关性变得简单。
Orthus 的设计核心是使用了 modality-specific heads,对 text token 采用 language modeling (LM) head,对 visual token 采用 diffusion head。设计思路也不难,只需要把 visual token 的 Vector Quantization 过程替换成 Diffusion head,适当微调即可。
Orthus-base 可以进一步 Post-training,更好地建模交错图像和文本。
Orthus 在标准基准测试中超越了包括 Show-o 和 Chameleon 等 Baseline。Orthus 使用 7B 参数实现了 0.58 的 GenEval 分数和 1265.8 的 MME-P 分数。Orthus 还显示了出色的混合模态生成能力。
本文做了哪些具体的工作
-
提出一种命名为 Orthus 的 Unified Model: 以完全自回归的统一范式来训练文本和图像数据,通过 de-tokenizer 生成 discrete text token,通过 Diffusion head 生成 continuous image feature。 -
高效的训练方法: 借助已有的 Unified Model 进行微调,成本降低到仅 72 A100 GPU hours。 -
性能: Orthus 在各种理解和生成基准上优于 Chameleon 和 Show-o 等相关工作。
下面是对本文的详细介绍。
本文目录
1 Orthus:使用 Diffusion Loss 的生成理解统一模型
(来自上海交大,快手)
1 Orthus 论文解读
1.1 Orthus 模型
1.2 生成理解统一模型的 2 种范式
1.3 Orthus 方法
1.4 高效训练策略
1.5 多模态后训练
1.6 实验设置
1.7 实验结果
1Orthus:使用 Diffusion Loss 的生成理解统一模型
论文名称:Orthus: Autoregressive Interleaved Image-Text Generation with Modality-Specific Heads
论文地址:
https://arxiv.org/pdf/2412.00127
1.1 Orthus 模型
最近越来越多的研究集中在使用 Unified Model 来联合建模交错图像和文本。一种策略是将图像和文本映射到 discrete token 进行自回归建模,比如 Chameleon,Emu3,如下图 1 所示。但是,通常会产生 Vector Quantization (VQ) 的瓶颈,导致不可避免的信息损失,并且容易导致高频细节 (如 OCR 和人脸生成) 相关的视觉任务的性能次优。

最近的工作,包括 Transfusion,Monoformer 等,提出将对 discrete text token 采用自回归建模,对 continuous image token 采用扩散模型建模,如图 2 所示。但是,扩散模型处理噪声图像的性质使得视觉生成和视觉理解的联合建模具有挑战性。

为了解决这个问题,本文提出 Orthus。通过将 Diffusion 与 Transformer Backbone 解耦,将无损的 continuous 的图像特征和统一的跨模态自回归建模结合到一起。Orthus 把 discrete text token (通过现成的 tokenizer 得到) 和 continuous patch-wise image feature (通过预训练的 VAE 得到) 编码到相同的表征空间中,然后通过一个自回归 Transformer 来建模模态之间以及模态内部的相互依赖。Orthus 定义了 2 个特定于模态的 head,其中一个作为常规语言建模 (LM) 头来预测 discrete text token,另一个 Diffusion head 来生成 continuous image feature。推理过程中,Orthus 按照自回归的范式预测下一个 text token 或 image patch。

Orthus 的另一个重要贡献是高效的训练策略。作者发现 Orthus 与主流基于完全自回归的 Unified Model Chameleon 的区别仅仅只在输入和输出 head,因此使用 Chameleon 初始化 Orthus。作者在训练 Orthus 时只在 10K 的训练数据上,微调 Embedding modules 和 Diffusion head (共计 0.3B 参数),毫不费力地获得 Orthus 基础模型。而且,可以进一步采用 Post-training 来增强其对交错图像文本建模的能力。
1.2 生成理解统一模型的 2 种范式
生成理解统一模型一般包括一个视觉 VAE,一个 text tokenizer,和一个 Transformer Backbone。视觉 VAE 的 Encoder 把输入图片映射为一系列的 patch-wise features 是 patch 的数量。text tokenizer 把输入 text 映射为一系列的 text tokens 是 sequence length。Transformer 同时处理 和 以产生有意义的输出,然后可以将其 detokenized 为文本或由 Decoder 解码成图像。
关于 Transformer 的训练有 2 种模式:
1) 完全自回归
LWM 和 Chameleon,利用矢量量化(VQ)技术将连续图像特征 V 转换为离散标记,以实现图像和文本混合的完全自回归建模。具体来说,VQ 引入了 个离散代码 ,根据下式决定使用哪个:
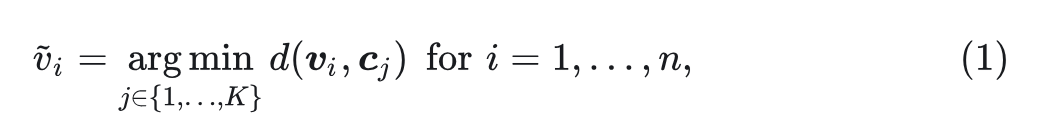
其中, 是 distance metric。
离散 image tokens 表示为 ,完全自回归模型把 和 编码为 维度的特征。具体而言, 对应的 embedding 为:

其中, 代表 embedding weights。然后 Transformer 使用 Causal attention 处理这些 embedding,其中输出头自然产生下一个 token 的预测。对于训练,目标只是 AR loss。
尽管简单,但完全自回归式模型可能会受到信息损失的影响,因为 VQ 使 Transformer 无法直接查看图像特征 。
2) 自回归-扩散混合
Unified Model 的另一种做法是自回归-扩散混合架构,对图像使用扩散模型建模,对文本使用自回归建模,共享一个 Transformer 架构。
比如 Transfusion[1],其输入是 image features 的 noisy 版本,用 表示。其他输入是 text tokens。为了便于同时处理 和 ,Transformer 的 attention mask 采用了独特的配置:在 之间具有 full attention 架构,在 之间使用 causal attention。然后使用 Diffusion 过程预测 的噪声,然后 的输出通过一个 LM head 做 next-token prediction。
训练的目标是 AR Loss 和 Denoising Loss 的结合。
在推理时,模型在生成 text 时作为 AR 模型来运行,在生成 image 时作为 Diffusion 模型来运行。
然而,扩散建模本质上需要向模型输入噪声,阻碍了视觉理解 (需要干净的图像) 和生成 (需要有噪声的图像) 的联合建模。
1.3 Orthus 方法
如下图 4 所示,Orthus 直接处理 continuous image features 以及 discrete text tokens ,为输入。这个做法避免了对 image feature 做量化或者加噪带来的信息损失。 和 被编码到一个 维度的表征里面。然后使用 Transformer Backbone 配和纯 causal attention 建模模态内以及模态间的关系。
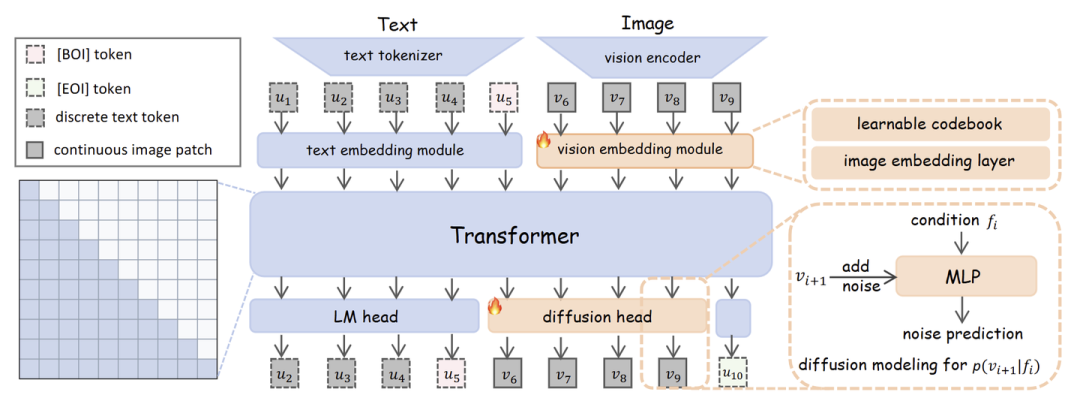
Orthus 使用了 2 个特定模态的 head:
Diffusion head:预测下一个 image patch。
LM head:预测下一个 token。
令 代表对于 image feature 的输出特征, 代表 diffusion head 的参数,diffusion head 的目的是为了在以 为条件时,预测输出特征 。diffusion head 的训练目标可以写成:
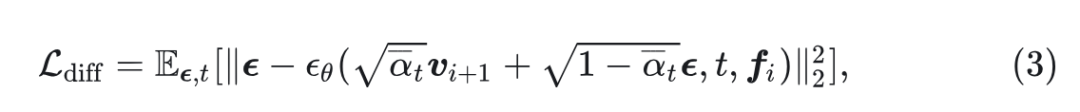
其中, 是高斯噪声, 是随机采样的时间步长, 是噪声调度。实践中,可以是小 MLP。另一方面,LM head 仍然是 linear projection+softmax,预测下一个 token在整个词汇表上的概率。
1.4 高效训练策略
Orthus 和完全自回归模型之间的差异在:output head 和 vision embedding。从头开始预训练多模态模型成本太高,而且 LWM 和 Chameleon 等完全自回归模型很容易从开源社区访问,作者希望借助它们训练 Orthus。
可微分的 vision embedding 模块
上式 1 和 2 可以写成:
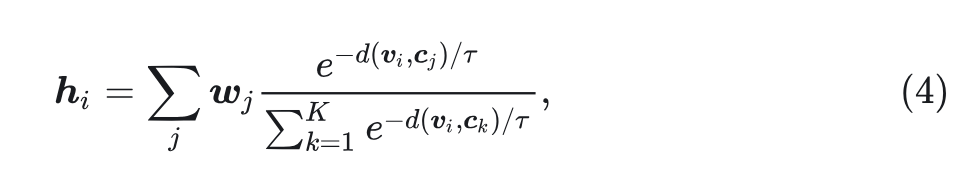
其中, 。这样,codebook 也成为输入模块的一部分,因此可以直接训练它们适应多模态学习任务。这与在训练期间冻结 codebook 的 AR 模型矛盾。
Orthus 从预训练的 AR 模型开始,将其输入模块转换为可微模块,并引入 Output diffusion head 初始化 Orthus。因为这些修改主要关注视觉部分,因此作者在一组图像上微调初始化模型。
作者只将图像输入到 Orthus 中以获得隐藏状态 ,并利用式 3 中的 diffusion loss 来重建 next patch 来训练 vision embedding 模块和 diffusion head。在训练期间,温度 设置为 1。
Orthus 使用 Chameleon-7B 做初始化,使用 8 A100 GPU 在 10k 高质量图像上进行 9 小时训练后,可以获得图像处理能力,同时保留 Chameleon-7B 的文本生成能力。将此模型指定为 Orthus-base。下图 5 展示了它的图像和文本 (以及混合模态) 的生成结果。

1.5 多模态后训练
遵循多模态模型的典型训练过程,作者通过在高质量的文本图像对和 instructional data 上对其进行微调来进一步细化 Orthus-base。
除了 vision autoencoder 的参数外,所有参数都进行了调整。遵循 Chameleon 的输入格式。为图像特征 的前后加上特殊 token[BOI]和[EOI]环绕,再与文本特征作拼接。[SEP] token 用于分离每个对话中用户输入和模型的输出。
令 表示文本 token 的 AR Loss。Orthus 的整个训练目标是:
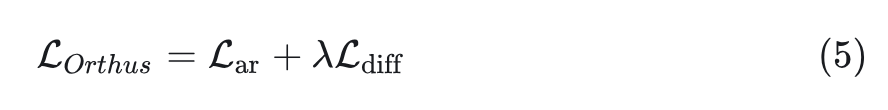
其中, 是系数。这个目标训练的模型表示为 Orthus,与 Orthus-base 区分开。
在推理过程中,Orthus 在 next-token predition 和 next-patch prediction 之间交替,生成交错的文本和图像。当在 next-token prediction 过程中采样到[BOI]token 时,算法将移动到 next-patch prediction。一旦生成了固定数量的 个图像 patch,就会附加[EOI],算法再切换到 next-token prediction 过程。
1.6 实验设置
Diffusion head: 3 个残差块组成的 MLP,每个块依次应用 AdaLN,线性层 (宽度 1536)、SiLU 激活和另一个线性层。
将条件向量 添加到扩散模型的 time embedding 中,然后通过 AdaLN 合并。扩散模型噪声训练时 1000 步。在 Orthus-base 的训练中,使用学习率为 1e-4 的 AdamW 和余弦衰减。在从 Orthus-base 到 Orthus 的训练后,以 1:1 的比例混合 LLaVA-v1.5-665K 指令微调数据和高质量的文本生图数据(JourneyDB 和 LAION-COCO-aesthetic,从 ShareGPT-4v 重新打字幕),以 1e-5 的学习率进行优化。后训练的 \lambda 设置为 100。
推理时,对于图像生成,采用具有 100 步的 DDIM 采样器。在采样期间采用 Classifier-Free Guidance (CFG),scale 设置为 5。所有图像都以 512×512 的分辨率生成。训练和评估都在配备 8 个 NVIDIA A100 80GB GPU 的服务器上进行。
对比模型
-
图像理解模型:包括 LLaVA、InstructBLIP、Qwen-VL-Chat、mPLUG-Owl2 和 IDEFICS-9B。
-
图像生成模型:包括 LlamaGen、SDv1.5、PixArt-α、SDv2.1、DALL-E 2、SDXL 和 SD3。
-
理解生成统一模型:Emu、NExT-GPT、SEED-X、Gemini-Nano-1、LWM、Transfusion 和 Show-o。
还对比了与 Orthus 相同的高质量数据集微调后的 Chameleon,以提供 apple-to-apple 的对比。
1.7 实验结果
多模态理解
下图 6 总结了 Orthus 在特定领域视觉问答和一般视觉理解任务方面的能力。与使用相同数据集训练的 Chameleon 相比,Orthus 在所有基准测试中始终表现出卓越的性能。这些结果通过采用图像的无损表示来验证 Orthus 建模的优越性。在 GQA 基准测试中,Orthus 优于更大、仅理解的模型,例如 InstructBLIP-13B 和 IDEFICS-9B。此外,它与 Qwen-VL-Chat 和 mPLUG-Owl2 等模型相当,这些模型已经在特定于任务的多样化 VQA 数据集上进行了训练。此外,Orthus 在所有基准测试中优于使用单个 Transformer (例如 LWM 和 Show-o) 的模型,突出了它 Unified 建模的有效性。与更大的使用额外的扩散模型的模型相比 (例如 NExT-GPT-13B),Orthus 在 VQAv2 基准测试中取得了不错的结果。可以合理地推测,Orthus 在多模态理解问题方面的潜力可以通过扩大训练计算和数据来进一步释放。

视觉生成
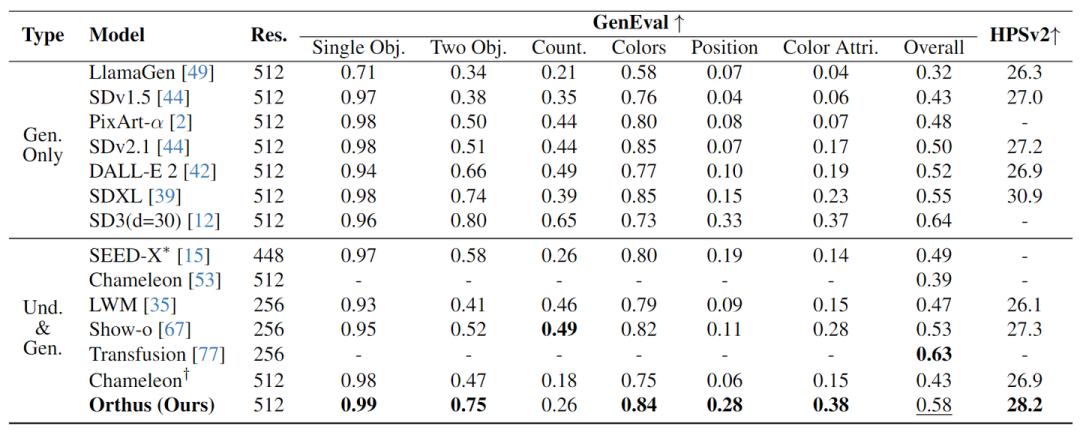
作者评估了 Orthus 在 GenEval 上的视觉生成性能,检查图像生成模型的组合能力。此外,也评估了 HPSv2,一种基于人类偏好的基准。
在图 8 中报告了 6 个维度的 GenEval 分数和 HPSv2 分数。与专门的文生图模型 (例如 DALL·E 2 和 SDXL) 相比,Orthus 在 GenEval 上分别实现了 0.06 和 0.03 的改进。与 Chameleon 及其后训练版本相比,Orthus 在 GenEval 和 HPSv2 上都表现出了显著的优越性。这一优势可归因于连续图像表示和基于扩散的连续建模的利用率,这有助于生成具有更丰富细节的高质量图像,并与人类偏好对齐更强。与其他 unified model 相比,Orthus 获得了更好的性能。Orthus 也取得了与 Transfusion 相当的结果,后者在预训练期间利用了更大的文本图像对数据集。Orthus 在 HPSv2 优于 SDv1.5 和 SDv2,显示了它能够生成与人类偏好一致的高质量、美观的图像。

图 7 展示了 Orthus 生成的图像以及其他统一模型的结果,包括 Chameleon 和 Show-o。Orthus 能够以 512×512 的分辨率生成多样化、引人入胜和逼真的视觉图像。
混合模态生成
作者还研究了 Orthus 的混合模态生成能力。作者首先表明 Orthus-base 可以生成连贯的交错图像-文本段序列,如图 5 左侧所示。为了进一步验证 Orthus 在建模交错数据方面的优势,作者在 StoryStream 数据集上使用统一的学习目标微调 Orthus-base,其中包括来自卡通系列的图像集合和相应的叙述。如图 5 右侧所示,经过训练后,Orthus 可以在给定初始图文对和指令 “Please continue this story” 的情况下,生成一些图片和相应叙述性的文本。
值得注意的是,图像和文本之间存在很强的对齐 (例如猴子脸上的微笑) 以及图像之间的一致细节 (例如男孩的橙色帽子)。这些结果突出了 Orthus 在各种应用中的潜力,包括报告生成、教育内容创建和其他需要多模态内容交织生成的应用。
参考
-
Transfusion: Predict the next token and diffuse images with one multi-modal model
(文:极市干货)