


本文作者来自马里兰大学的 CASE (Collaborative, Automated, Scalable, and Efficient Intelligence) Lab,主要参与者为博士生孙国恒与王子瑶,指导教师为李昂教授。
研究背景:在商业保护与用户知情间寻求平衡

-
论文标题:Invisible Tokens, Visible Bills: The Urgent Need to Audit Hidden Operations in Opaque LLM Services
-
arXiv 链接:https://arxiv.org/pdf/2505.18471
近年来,大型语言模型(LLM)在处理复杂任务方面取得了显著进展,尤其体现在多步推理、工具调用以及多智能体协作等高级应用中。这些能力的提升,往往依赖于模型内部一系列复杂的「思考」过程或 Agentic System 中的 Agent 间频繁信息交互。
然而,为了保护核心知识产权(如防止模型蒸馏或 Agent 工作流泄露)、提供更流畅的用户体验,服务提供商通常会将这些中间步骤隐藏,仅向用户呈现最终的输出结果。这在当前的商业和技术环境下,是一种保护创新、简化交互的常见做法。
近期,CASE Lab 团队将这类隐藏其内部工作流、仅返回最终结果但却按总 token 量计费的服务定义为「商业不透明大模型服务」(Commercial Opaque LLM Service, COLS)。如图 1 所示,无论是 Reasoning LLM 还是多智能体系统(Agentic LLMs)相关的服务,其内部都存在大量用户不可见的计费点。
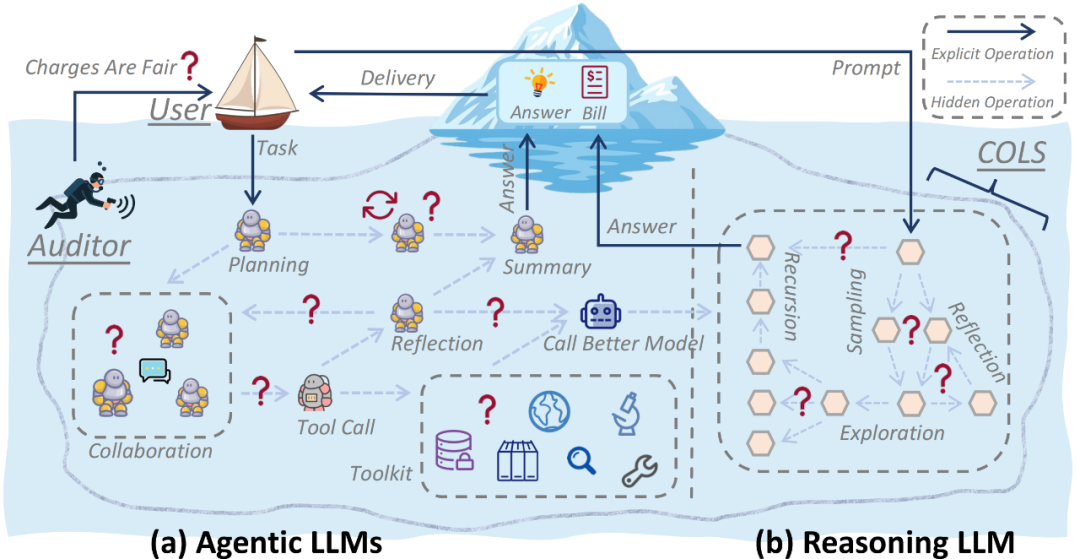
图 1:COLS 及其隐藏操作。
常见的 Reasoning LLM API 和 Agentic LLM APP 如图 2 所示,红框标识了隐藏操作。
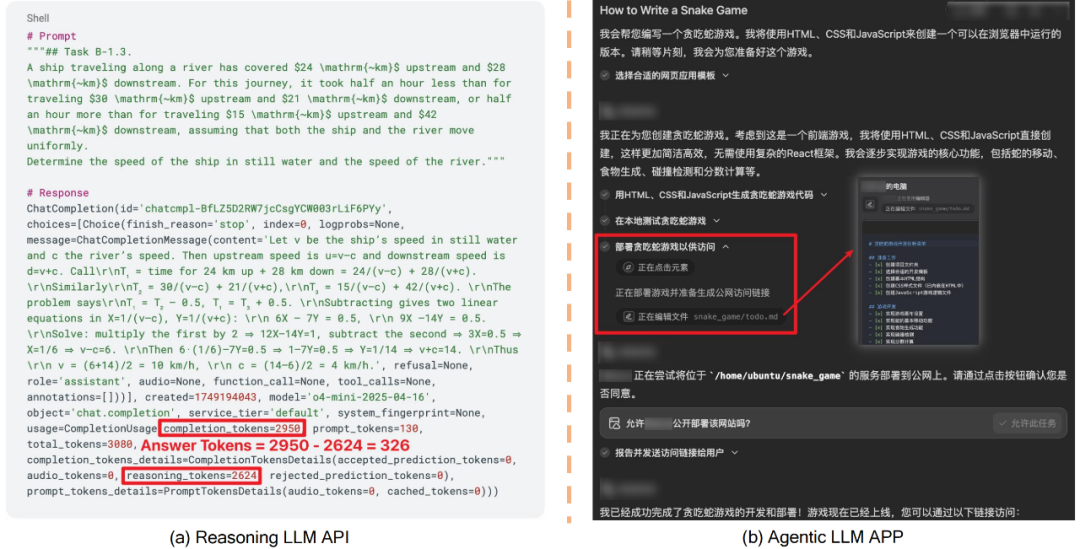
图 2:常见的 Reasoning LLM API 和 Agentic LLM APP。(a)主流的 Reasoning LLM API 按照包含推理步骤的 completion_tokens 计费,但是用户却只能看见 Answer。(b)主流的 Agentic LLM APP 执行的每个任务都将消耗通过付费订阅获得的积分,用户看不到中间过程的细节。
然而,这种商业模式也隐含出一种新型风险:由于用户无法看到、验证或质疑这些隐藏操作,一些不良的服务提供商在利益驱动下,可能通过「虚报消耗 token 数量」或对模型进行「偷梁换柱」来悄悄增加用户费用或降低自身成本。
图 3 以 Reasoning LLM API 为例,展示了主流模型隐藏的推理 tokens 数量,其常常是最终答案的几十倍之多。这意味着用户支付的绝大部分费用,都花在了他们看不见的地方,真实性无从考证。

图 3:Reasoning LLM API 在回答 open-r1/OpenR1-Math-220k 数据集中的部分问题时,推理 token 与答案 token 的比例。
团队对 Reasoning LLM 和 Agentic LLMs 中的主要风险给出了具体定义并给出了潜在解决方案,包括:
1. 数量膨胀(Quantity Inflation),即服务方通过夸大生成 token 数量或内部模型调用次数来虚增计费。具体表现为:
-
在 Reasoning LLM 中,可能通过冗余推理步骤(如重复检索、低效展开)造成 token 增长;
-
在 Agentic LLMs 中,则可能存在模型或工具调用的频率膨胀,甚至伪造通信行为。
2. 质量降级(Quality Downgrade),即服务方在保持计费标准不变的情况下,悄然替换为低成本模型或工具。例如:
-
在 Reasoning LLM 中调用小尺寸的或量化后的模型;
-
在 Agentic LLMs 中模拟工具调用而非真正执行,或者用成本更低的工具替代宣称的高成本工具,例如用本地知识库代替网络搜索。
此外,如图 4 所示,团队还提出了一个结构化的三层审计蓝图,旨在推动 COLS 行业建立标准化、可验证的审计基础设施:
-
第一层(服务执行层):记录 COLS 内部模型生成、Agent 通信与工具调用等核心操作;
-
第二层(安全承诺与记录层):将上述操作以加密摘要、哈希链、区块链等形式提交为可验证承诺;
-
第三层(审计与反馈层):允许用户或第三方审计机构对服务行为进行独立验证,并为用户提供账单合理性或服务一致性的反馈报告。
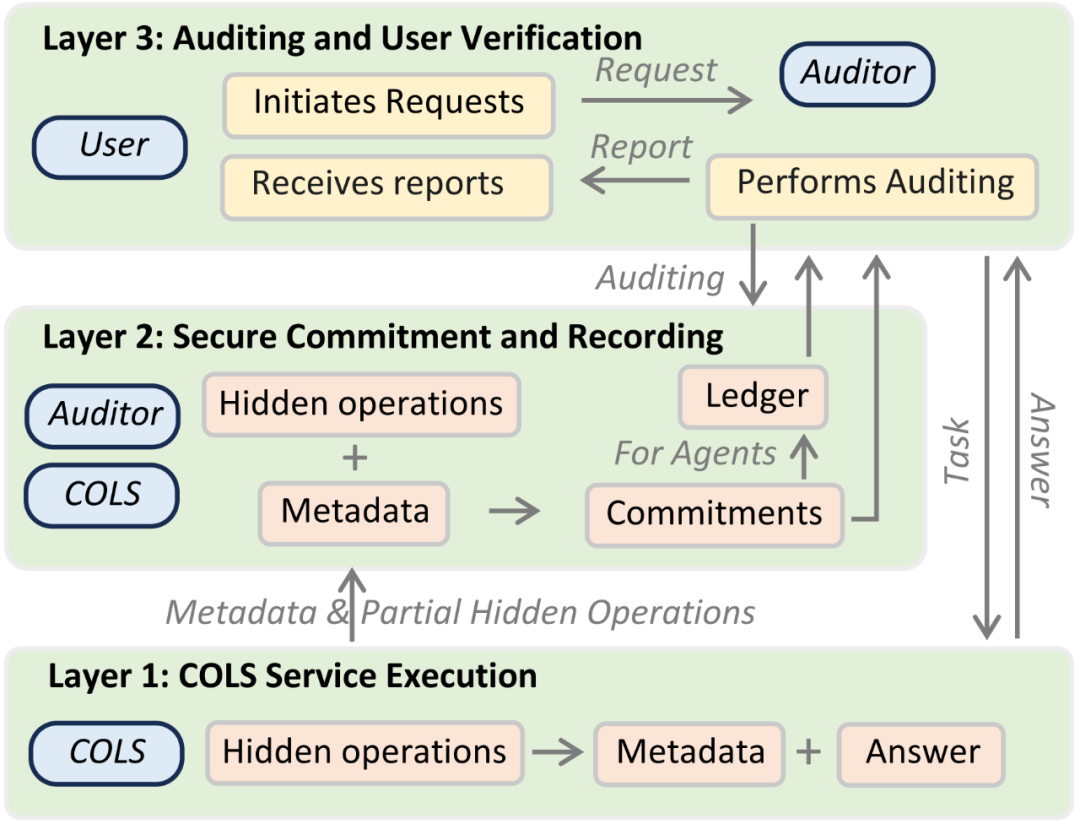
图 4:三层审计框架。
该框架基于「可验证但不泄密」的理念,鼓励未来的 COLS 服务商在保护商业敏感信息的同时,实现对用户透明、可信的服务承诺。这一体系既支持技术层面的透明性,也为政策制定与合规提供了实现路径。
CoIn:让隐藏操作可验证但不泄露

-
论文标题:CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs
-
arXiv 链接:https://arxiv.org/pdf/2505.13778
-
GitHub 链接:https://github.com/CASE-Lab-UMD/LLM-Auditing-CoIn
-
Hugging Face 链接:https://huggingface.co/collections/s1ghhh/coin-llm-auditing-6842a46feea043d46c0d338e
为了解决 Reasoning LLM API 的计费审计问题,该研究团队还提出了用于防止 token 数量膨胀(Quantity Inflation)的验证框架 CoIn,旨在提供一种技术可能性,在尊重和保护 COLS 的商业机密和知识产权的前提下,赋予用户验证服务真实性的途径,从而在用户和 COLS 之间搭建起一座「信任桥梁」。
如算法 1 所示,CoIn 包含适应性的多轮验证,其中每轮会验证 COLS 宣称的 Token 数量是否准确以及隐藏的 Reasoning Token 是否真正参与推导出答案,最终由 Verifier 来给出判断。对于正常样本,CoIn 会在早期便验证成功并结束,而对于较难判断的样本或者数量膨胀后的恶意样本,CoIn 会验证更多轮,避免漏判。

算法 1:CoIn 的适应性多轮验证。
CoIn 框架的单轮验证主要包含两大模块:
1.Token 数量验证 (Token Quantity Verification): 如图 5-(a) 所示,这一模块巧妙地运用了密码学中的默克尔树 (Merkle Tree) 技术。COLS 需将其所有隐藏 tokens 的「指纹」(即嵌入向量,embedding)作为叶子节点,构建一棵哈希树,并向审计方(可以是用户或独立的第三方平台)提供最终的哈希根(Merkle Root)。在审计时,审计方仅需请求并验证极少数随机抽取的 token “指纹” 及其在哈希树中的路径(Merkle Proof),便能高效地核实 token 总数是否与声明一致,而无需访问所有 token 的原始内容。
这种方法的核心优势在于,它能在泄露很少推理步骤的前提下,确保数量的准确性。更重要的是,由于哈希承诺的特性和用户质疑的随机性,恶意 COLS 的伪造必须做全套,并且在返回给用户结果时就得完成伪造,无法专门应对用户的质疑,大大提高了 COLS 的造假成本。
2. 语义有效性验证 (Semantic Validity Verification): 仅验证数量的准确性尚不足以完全打消用户的疑虑,因为理论上 COLS 仍可能产生大量与任务目标关联较弱的「无效」token 来冒充隐藏 token。 如图 5-(b) 所示,CoIn 设计了轻量级的「Matching Head」来分析被抽查的隐藏 token(的指纹)与最终答案之间的语义连贯性和逻辑相关性,并给出一个相关性评分。如果评分显著偏低,则可能表明这些隐藏 token 对最终结果的贡献有限。这一机制旨在确保用户支付的费用,对应的是真正服务于任务目标的有效推理过程。

图 5:CoIn 验证框架。
团队定义了 COLS 可能会实施的多种适应性数量膨胀攻击,并据此在医疗、代码、数学、通用推理等多个不同领域上构建了高难度的数据集,用于训练 CoIn 框架中的 Matching Head 和 Verifier,以及验证 CoIn 框架的性能。实验结果显示,CoIn 框架具有如下特性:
-
高效识别 token 数量膨胀:图 6 展示了 CoIn 在不同模拟场景下的检测成功率(Detection Success Rate, DSR),可以看到,随着膨胀率(Inflation Rate = 伪造的 token 数 / 真实 token 数)的增加,CoIn 的识别能力也相应增强。在高膨胀率的场景下(即 COLS 伪造的 token 占比超过 50%),即使面对经过特殊设计、语义上与原始内容相似的「自适应 token 膨胀 」场景,在仅暴露极少量信息的情况下,CoIn 的平均 DSR 也能达到 94.7%。而对于 COLS 仅仅虚报 10% tokens 的场景中,CoIn 也有约 40% 的平均 DSR。
-
可定制性:图 6 中的红线和蓝线分别代表两种类型的 Verifier,一种基于神经网络,一种基于规则。前者对于恶意样本具有很高的 DSR,但是对正常样本的误判率也比较高。而后者则可以由 COLS 和用户协商后设置参数,在减少对正常样本的误判和高效检测数量膨胀之间达到平衡。
-
极低的审计开销: 整个审计过程对用户和服务商而言开销较低。在验证过程中,审计方仅需访问不到 4% 的隐藏 token 信息(指纹),便能完成高精度的验证。如图 7 所示,默克尔树的构建在单核 CPU 上只需要一秒左右,对于拥有强大计算资源的 COLS 而言,其额外开销几乎可以忽略不计。
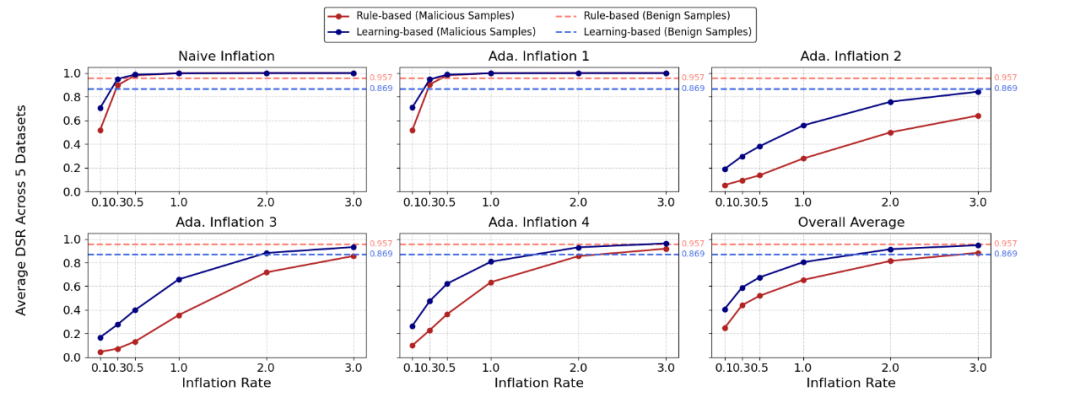
图 6:不同膨胀率(Inflation Rate)下,CoIn 应对多种数量膨胀攻击时的表现。
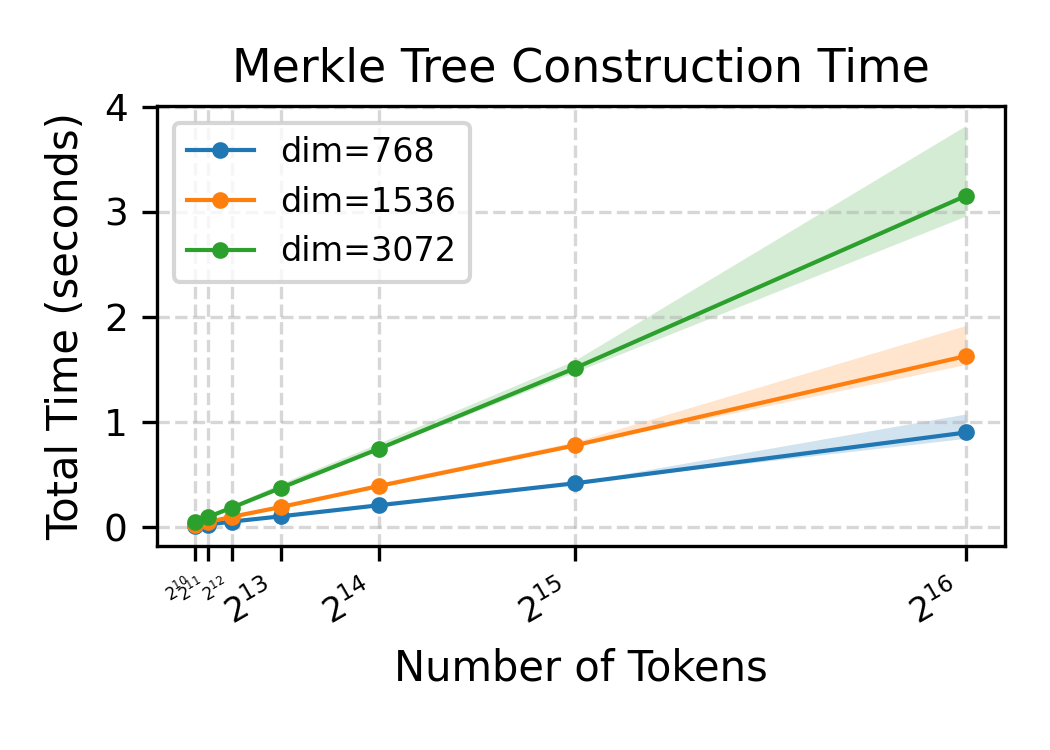
图 7:不同隐藏 Tokens 数量和 Embedding 模型 Hidden Dimension 下,Merkle 哈希树的构建成本。
总的来说,来自马里兰大学的 CASE Lab 团队首次系统性地分析了当前主流大模型服务在「隐藏操作」透明度方面面临的挑战,并提出了首个旨在解决 token 数量膨胀问题的审计框架 CoIn。
CoIn 的核心贡献在于,它探索出一条在平衡服务商知识产权保护与用户对服务透明度合理需求之间的技术路径,期望能为构建用户和服务商之间的相互信任提供有力的技术支撑。
截至目前,主流推理模型均不会暴露自己的推理过程,尽管这部分仍然需要用户付费。然而,已经有一些转变标识着各大 LLM API 提供商正在尝试达到知识产权保护和用户知情权的平衡。例如,几乎所有服务提供商都会提供返回摘要的服务;Claude 4.0 可以提供加密后的推理 tokens 以便用户检查真实性以及保障推理过程未被篡改。
CASE Lab 团队呼吁学界和业界共同关注这一新兴领域,共同推动建立更加透明、公平和可信的 AI 服务标准与实践。未来的研究方向可以包括开发更为完善和易于部署的审计协议或框架,探讨将此类审计机制作为行业准则或第三方认证标准的可行性,以及推动相关技术标准和最佳实践的形成。最终目标是促进整个大模型生态系统的健康、可持续发展,让前沿的人工智能技术能够在赢得公众持久信任的基础上,更好地服务于社会。
©
(文:机器之心)