

“ 大模型只是一种可插拔组件,提示词才是核心。”
关于提示词的重要性应该没什么好说的了,可以说现在所有的基于大模型构建的应用都是以提示词作为核心切入点;不管是RAG还是智能体,无外如是。
对从事大模型应用的开发者来说,重要的不是大模型的部署和运维,其核心是怎么写好提示词;以目前市面上的开发框架或开源项目来看,大模型都是一个可插拔的组件,只要配置好模型参数,在业务场景中可以随意切换不同的模型。
模型只是可插拔组件,提示词才是应用的灵魂
现在关于大模型的应用千奇百怪涉及到各种领域,但如果我们真的深入研究会发现;事实上真正和大模型交互的功能并不是很多,大部分都是一些工程性代码,而大模型的交互接口也就那一两个,然后就是根据不同的业务场景封装的提示词。

为什么说“大模型只是一个可插拔组件”?
-
基础设施化: 大型语言模型(LLM)本身越来越像一种基础计算资源(如同CPU、GPU、数据库)。开发者通过API或本地部署调用其能力,无需从头训练(成本极高)。
-
模型即服务: 云服务商(OpenAI, Anthropic, Google, 阿里云,百川,月之暗等)提供多种不同能力、规模和价格的模型供选择。应用开发者可以根据需求(成本、速度、能力、合规性)轻松切换底层模型。
-
接口标准化: 主要的LLM提供商都提供相对统一的API接口(输入文本/提示词,输出文本/结构化数据)。这使得替换底层模型对上层应用逻辑的影响相对可控(当然,效果会有差异)。
-
能力趋同与差异化并存: 虽然顶级模型(如GPT-4, Claude 3 Opus)在复杂任务上仍有差距,但许多基础任务上,不同模型的表现差异在缩小,使得“可插拔”更具可行性。同时,特定场景下(如长文本、代码、中文理解、开源部署)仍有差异化选择。
✅ 为什么说“提示词才是大模型应用的核心”?
-
能力的解锁与定向: LLM本身拥有海量知识和潜能,但它是“未聚焦”的。提示词就像指令、引导和约束,告诉模型:
-
做什么? (任务定义:总结、翻译、写邮件、分析数据、角色扮演…)
-
怎么做? (推理步骤、输出格式、风格要求、限制条件…)
-
参考什么? (提供上下文、示例、知识片段…)
-
避免什么? (偏见、幻觉、无关信息、不安全内容…)
-
扮演谁? (专家、助手、特定角色…)
-
效果的决定性因素: 对于同一个模型,不同的提示词可以导致天壤之别的输出结果。精心设计的提示词可以:
-
显著提高任务完成度。
-
极大减少错误和“幻觉”。
-
精确控制输出的风格、格式和细节。
-
引导模型进行更复杂、更符合逻辑的推理。
-
应用差异化的关键: 当底层模型变得“可插拔”且逐渐同质化时,如何构建一个独特、有效、用户体验好的AI应用?核心就在于:
-
提示工程: 设计高效、鲁棒、能应对各种边缘情况的提示词模板。
-
提示编排: 将复杂任务分解为多个子步骤,设计串联或并联的提示链。
-
上下文管理: 如何高效、准确地为模型提供完成任务所需的相关信息(检索增强、记忆管理)。
-
工具集成: 通过提示词指导模型调用外部工具(计算器、搜索引擎、API、数据库)。
-
成本与效率的杠杆: 优秀的提示词可以用更少的计算资源(更短的上下文、更少的推理步骤)得到更好的结果,或者让稍弱一些的模型达到接近顶级模型的效果,从而显著优化应用的成本效益。

🔄 辩证看待:提示词并非万能,模型仍是基础
-
模型能力是天花板: 无论提示词多么精妙,都无法让一个基础模型完成超出其能力范围的任务(例如,让一个只懂英文的模型完美处理复杂中文古文,或者让一个7B模型完成需要70B模型才能处理的复杂逻辑推理)。提示词是在模型能力边界内进行引导和优化。
-
模型特性影响提示设计: 不同模型对提示词的敏感度、对指令的遵循能力、上下文窗口大小、对特定格式(如XML tags, JSON)的理解程度都不同。为A模型优化的提示词,直接用在B模型上效果可能打折扣,需要调整。“可插拔”并不意味着“无缝替换”。
-
提示词的局限性:
-
幻觉风险: 再好的提示词也不能完全消除模型捏造事实的可能。
-
脆弱性: 提示词可能对措辞的微小变化敏感。
-
复杂性管理: 对于极其复杂的任务,仅靠提示词编排可能变得难以维护和调试,需要结合传统编程或Agent框架。
-
安全与对齐: 仅靠提示词约束模型行为有时不够可靠,需要模型本身有良好的基础对齐。
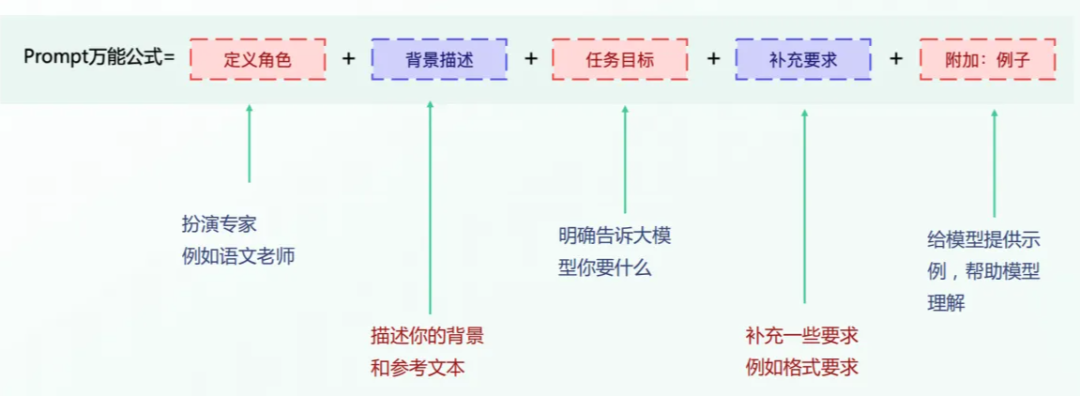
🧠 结论:提示词是应用层的“操作系统”和“灵魂”
-
你的观点在应用开发视角下非常精准: 对于构建基于LLM的产品和服务,核心的竞争力和价值创造点确实越来越集中于如何设计、管理和优化提示词(以及相关的上下文、工具链、流程编排)。模型更像是提供基础计算能力的“引擎”。
-
这是一种范式的转变: 从传统的“训练模型解决特定问题”转向了“用自然语言指令(提示词)引导通用模型解决广泛问题”。这使得AI应用的开发门槛降低、迭代速度加快。
-
未来的方向:
-
提示工程自动化: 自动优化和生成提示词。
-
更强大的Agent框架: 提供管理复杂提示链、记忆、工具使用和决策的底层架构,让开发者更专注于任务定义(本质也是高级提示)。
-
模型与提示的协同进化: 模型会更擅长理解复杂指令和上下文,降低提示工程难度;同时提示工程的发展也会推动模型能力的更有效释放。
在当前的LLM应用生态中,提示词及其工程化实践确实是撬动大模型价值、构建差异化应用的核心杠杆和关键技能。 理解并掌握它,是构建下一代智能应用的基础。把大模型视为强大但可替换的“计算单元”,而将智慧和设计投入到提示词这个“控制中枢”上,是高效应用AI的明智之道。
(文:AI探索时代)