

今天是2025年6月21日,星期六,北京,晴
来看RAG问题,关于代码RAG怎么做chunk 切分,主要核心问题还是要考虑语义完整性。
所以看看代码RAG一般怎么做chunk切分以及改进AST的RAG-code切分方案cAST。
一、代码RAG一般怎么做chunk切分
我们来看代码RAG进展,增强代码检索增强生成,其中一个核心点就是代码分块(chunking)。
当前,有一些切分的工具,例如:
1)Python:AS模块生成语法树,按节点类型切分。
2)Java/C++:使用ANTLR或Tree-sitter解析器。
3)通用工具:LangChain的CodeTextSplitter支持多语言
来看两个问题:
1、有哪些切分思路?
1)基于语法结构的切分
利用代码的语法单元(如函数、类、代码块)作为切分边界,保持逻辑完整性。
例如:函数/方法级切分:以单个函数为单位,保留输入输出注释和参数说明;类级切分:将整个类作为切分单元,适合面向对象代码的检索。
这种方案可以保留代码的完整功能上下文,适合API文档或库代码的检索,但是长函数或复杂类可能导致块过大,需结合递归切分。
2) 基于逻辑块的切分
思路是按代码逻辑(如循环、条件分支、异常处理)划分。
例如将try-catch块或if-else分支作为一个单元。
这种方案增强生成答案的连贯性,适合代码片段问答,但是需依赖代码解析工具(如AST分析),对非结构化代码效果差。
3)混合切分策略
这种方式就是采用粗切分+精切分,先按函数/类切分,再对过长块按逻辑或行数二次分割,然后相邻块保留10%-20%重叠(如函数调用关系),避免上下文断裂,也就是常说的overlap。
2、存在哪些问题?
但是,上述这的方式容易破坏语义结构,分割函数或将无关代码合并,这可能会降低生成质量,也就是说,语法无关的分块常常会遗漏生成功能性代码所需的关键信息。
如下图所示,一个具体例子:
在这个例子中,固定大小的分块破坏了compute_stats方法的结构,导致模型丢失了关于其返回值的上下文信息。因此,模型基于对返回值的错误假设生成了错误的代码。
二、改进AST的RAG-code切分方案cAST
上面也说到AST可以通过抽象语法树进行分块,保留其原始结构, 但可以改良一下。
看一个工作 《cAST: Enhancing Code Retrieval-Augmented Generation with Structural Chunking via Abstract Syntax Tree》,https://arxiv.org/pdf/2506.15655,核心是,通过抽象语法树实现结构分块,递归地将大型AST节点分成更小的块,并在尊重大小限制的情况下合并兄弟节点。
切分的代码在: https://github.com/yilinjz/astchunk,可以直接pip install astchunk安装。

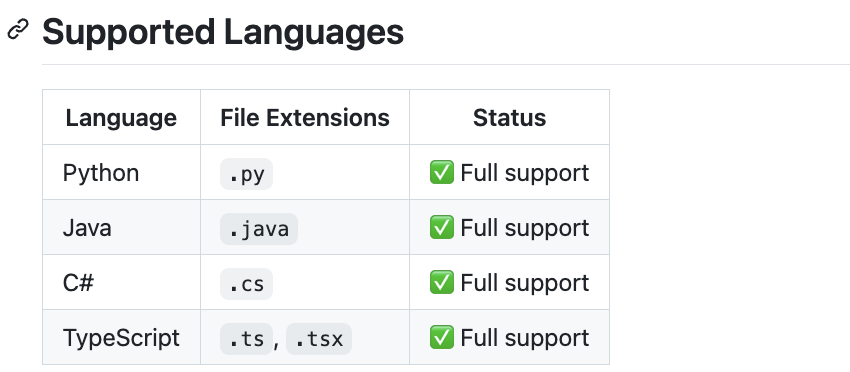
支持python、jave、C#、TypeScript 等语言。
1、什么是AST?
Abstract Syntax Tree (AST)是一种树状结构抽象,以层次化和语义丰富的方式捕获源代码的句法结构。与将代码视为纯文本不同,抽象语法树(AST)将语言构造(如函数、类、循环和条件语句)编码为结构化解析树中的不同节点,这使得能够精确地识别有意义的代码边界,确保分块操作尊重底层语法。
所以可以使用树爬虫库(Tree-sitter)进行AST树的解析。
3、怎么做递归分割?
有了AST树之后,采用一种递归的“分割后合并”算法将树结构转换为块,如图2所示。
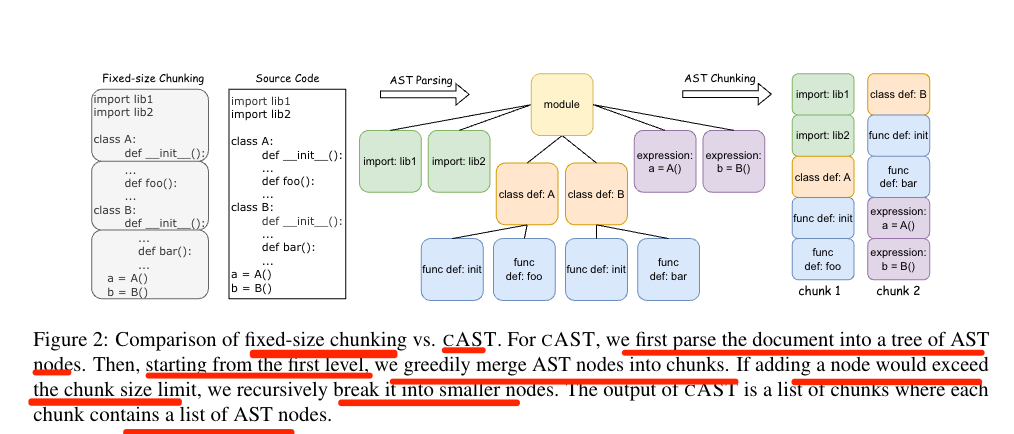
为了尽可能保留尽可能多的句法信息,首先以自上而下的方式遍历树,以便在可能的情况下将较大的AST节点放入单个块中。
对于那些因超出块大小限制而必须分割的节点,为了避免过多过小的块,进一步执行贪婪合并步骤,将相邻的小同级节点合并为一个块,以最大化每个块的信息密度。
4、怎么度量块大小?
为每个块选择一个合适的预算并非易事,两个具有相同行数的代码段可能包含大量不同的代码,而与AST对齐的块自然在物理跨度上有所不同(例如,单独的一行导入语句与整个类体)。
因此,通过非空白字符的数量而非行数来衡量块的大小,使文本块保持高密度的文本,并且在不同的文件、语言和编码风格之间是可比的。
5、最终效果如何?
最终结果如下:
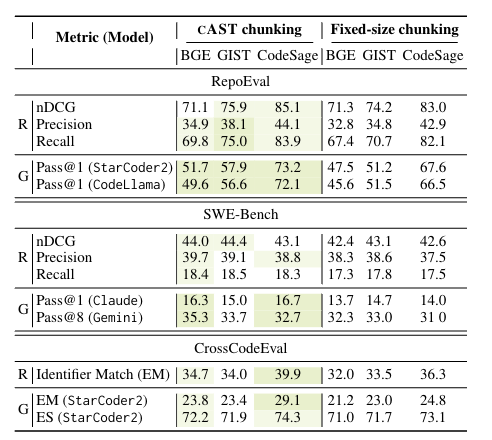
在Repoeval检索时将Recall@5提高了4.3分,在SWE-Bench生成时将Pass@1提高了2.67分。
具体如何用?看一个具体的例子:

参考文献
1、https://arxiv.org/pdf/2506.15655
(文:老刘说NLP)