跳至内容
腾讯最近开源了一个声音驱动画面的模型,叫HunyuanVideo-Avatar(混元-阿凡达)。
通过简单试用,我感觉这类工具即将快速普及,对短视频以及直播行业冲击非常大。
可以出离谱的一眼AI但非常有趣的视频,可以出以假乱真替代真人的视频。
然而,仍然存在几个关键挑战:(i) 在保持角色一致性的同时生成高度动态的视频,(ii) 在角色和音频之间实现精确的情感对齐,以及 (iii) 启用多角色的基于音频的动画。
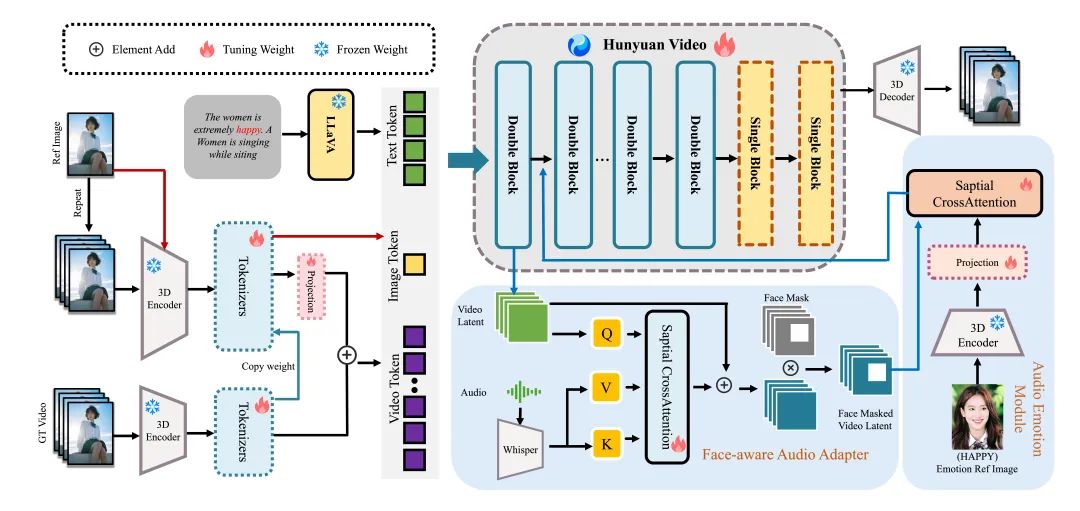
为了解决这些挑战,我们提出了一种基于多模态扩散变换器(MM-DiT)的模型——HunyuanVideo-Avatar,该模型能够同时生成动态、情感可控和多角色对话视频。
具体来说,HunyuanVideo-Avatar 引入了三个关键创新:(i) 设计了一个角色图像注入模块,以替代传统的基于加法的角色条件方案,从而消除训练和推理之间的固有条件不匹配。 这确保了动态运动和强烈的人物一致性;(ii) 引入了音频情感模块(AEM),以从情感参考图像中提取和转移情感线索到目标生成的视频中,实现精细的情感风格控制;(iii) 提出了面向面部的音频适配器(FAA),以隔离由音频驱动的人物,并通过跨注意力机制实现多人物场景中的独立音频注入。
这些创新使 HunyuanVideo-Avatar 在基准数据集和一个新提出的野外数据集上超越了最先进的方法,生成了在动态、沉浸式场景中的逼真 avatar。
https://hf-mirror.com/tencent/HunyuanVideo-Avatar/tree/main
https://hunyuan.tencent.com/modelSquare/home/play?modelId=126
(文:路过银河AI)