


极市导读
本文介绍了LazyMAR 技术,通过巧妙地利用特征缓存机制,成功攻克了MAR模型在计算效率方面的瓶颈,不仅实现了高达 2.83 倍的加速效果,而且几乎不损失图像生成质量,为 MAR 模型在实际应用中的高效部署提供了全新的解决方案。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 LazyMAR:特征缓存加速自回归图像生成
(来自北理工,中南大学等)
1.1 LazyMAR 研究背景
1.2 MAR,KV Cache 和 CFG
1.3 Token 冗余
1.4 Condition 冗余
1.5 周期性缓存-复用-刷新
1.6 实验结果
太长不看版
通过特征缓存 (Feature Caching) 加速自回归图像生成。
Masked Autoregressive Model (MAR) 方法是图像生成领域很有前途的方法,相比传统的 Autoregressive Model,其并行解码的能力可以提高图像生成的效率。
但是 MAR 用的是 Bidirectional Self-attention,不是 Causal Self-attention。Bidirectional 注意力与 KV Cache 机制相冲突,破坏了预期的高效率。
为了解决这个问题,LazyMAR 利用两种类型的冗余来研究 MAR 的缓存机制:
-
Token 冗余:大部分 token 在相邻的解码步骤中表征十分相似,使得可以在前面的步骤中缓存它们,并在后面的步骤中重用这些 token。 -
Condition 冗余:Classifier-free Guidance 中 Conditional 和 Unconditional 的输出之间在相邻步骤中表现出非常相似的值。
LazyMAR 对于所有 MAR 模型都是无训练和即插即用的。LazyMAR 在生成质量几乎没有下降的情况下实现了 2.83× 的加速。
1 LazyMAR:特征缓存加速自回归图像生成
论文名称:LazyMAR: Accelerating Masked Autoregressive Models via Feature Caching
论文地址:
https://arxiv.org/pdf/2503.12450
代码链接:
https://lgithub.com/feihongyan1/LazyMAR
1.1 LazyMAR 研究背景
Masked Autoregressive Model (MAR) 相比于传统 Autoregressive Model 的优势之一是可以实现 token 的并行预测,提高计算效率,同时维持或者得到更好的生成质量。
但尽管现有的 MAR 具有并行解码的能力,但其计算效率仍不够高,因为 MAR 使用的是 Bidirectional Self-attention,不是 Causal Self-attention。 Causal Self-attention 允许使用 KV Cache,存储上一步计算的 token 的 Key,Value 矩阵,并在下次计算的时候直接加载)。而 Bidirectional Self-attention 需要同时访问所有 token,没法使用 KV Cache,从而降低 MAR 的效率。需要一种针对 MAR 量身定制的新的缓存机制。
1.2 MAR,KV Cache 和 CFG
传统自回归模型建模联合分布
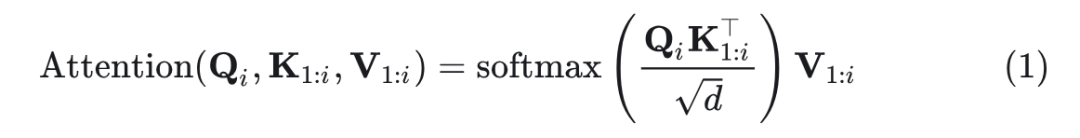
其中, 为第 个 token 的 query 向量。 为前 个 token 的 key,value 矩阵。KV Cache 可以存储之前步骤的 Key 和 Value: ,使得计算变成:
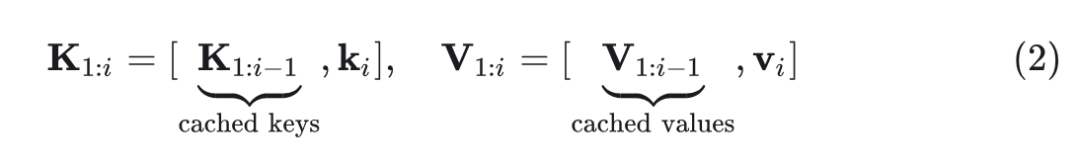
式中, 为当前的 step。上式将计算复杂度从 降到 。
Masked autoregressive model 预测 token 子集 的方法是 $p(\mathbf{X})=\prod_{k=1}^K p\left(\mathbf{X}^k \mid \mathbf{X}^{<k}\right)$ 。其中,=”” $\mathbf{x}^{<k}=”\cup_{j=1}^{k-1}” \mathbf{x}^j$=”” 。bidirectional=”” attention=”” 允许所有已知的=”” token=”” 进行交互:<=”” p=””>
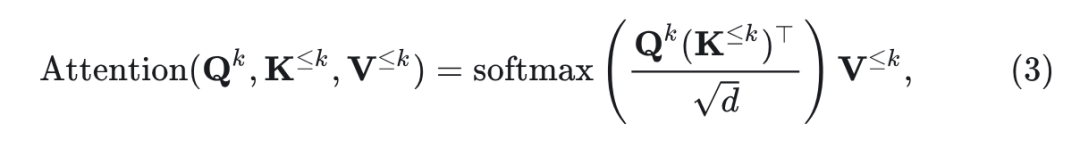
Bidirectional attention 与 KV Cache 不兼容。
Classifier-Free Guidance 是通过控制 Conditional 和 Unconditional 输出控制生成内容的一种方式。它包括一系列 conditional token,把条件信息 (language,class 等) 带到 image token 中。还包括一系列 fake conditional token:
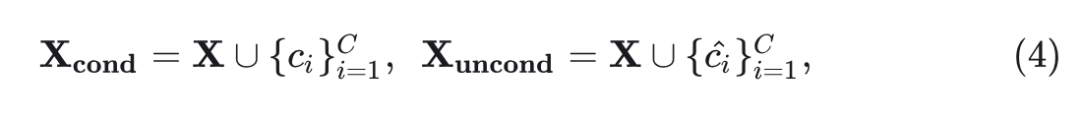
其中, 代表 conditional token, 代表其数量。 代表 fake conditional token。然后,通过将 MAR 表示为 ,conditional 和 unconditional 的输出可以表示为:
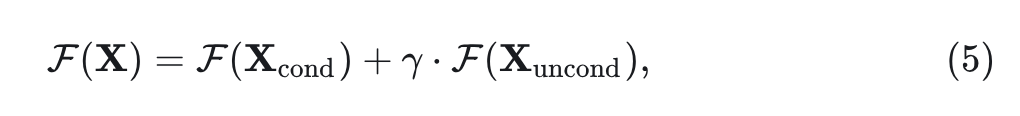
其中,是平衡它们的超参数。显然,CFG 中的两条路径使计算成本加倍。
1.3 Token 冗余
本文分析 MAR 中的计算冗余,包括 Token 冗余和 Condition 冗余。
Token 冗余
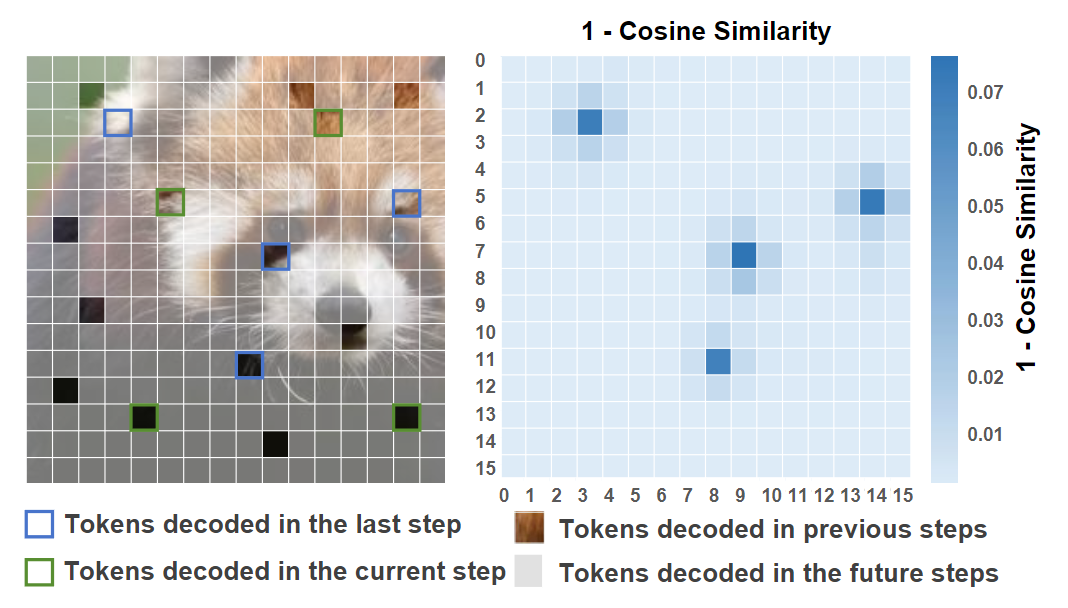
如图 1 所示,MAR 中的大多数 token 在相邻 decoding step 中呈现出非常相似的值,从而可以缓存上一步中 token 的特征,然后在接下来的步骤中复用这些 token。
MAR 中的 token 可以根据被解码的时间分为四组,包括:
-
这一步要解码的 token -
上一步解码的 token -
上一步之前已经解码过的 token $( -
未来解码的 token
图 1 的热图显示了当前 step 和上一个 step 的 token 表征之间的余弦距离。观察:大多数 token 在相邻的两步中展示出了相似性,除了上一步刚刚解码的 token。
解决方案:Token Cache
本文设计了两种 Token Cache 的策略如下。
-
基于观察的策略:即一个 token 是否应该从 Cache 中复用,是由其类型决定的。 -
基于相似度的策略:即一个 token 是否应该从 Cache 中复用,是由其与 Cache 中的 token 的相似度决定的。直觉上,较高的相似性意味着重用这个 token 带来的错误更低。
基于 Token 冗余,作者引入了 Token Cache:
存储之前步骤中 token,且在接下来的步骤中重用这些 token 进行加速。为了减少对生成质量的负面影响,仍然计算前几个 decoding step,因为这对于确定图像的基本内容至关重要。同时,通过存储这些步骤计算的特征来初始化 Token Cache。
在接下来的步骤中,计算神经网络前 3 层中的所有 token,然后重用 Token Cache 中的特征,对那些与上一步具有高余弦相似度的 token 跳过计算,只去计算相似度较低的 token 来维持生成质量。实验结果表明,Token Cache 平均可以在不损害生成质量的情况下跳过大约 84% 的 token。
总结:
-
在第一个 step,计算所有 token 的特征,存储它们的特征来初始化两个 Cache。 -
在后续 step 中,只计算前 3 层的所有 token,然后比较其与之前 step 的 token 的距离。在后续的层中,只计算差异度比较高的 token,那些差异度比较低的 token 就复用 token cache 中存的特征。 -
使用计算的 token 特征更新 token cache。
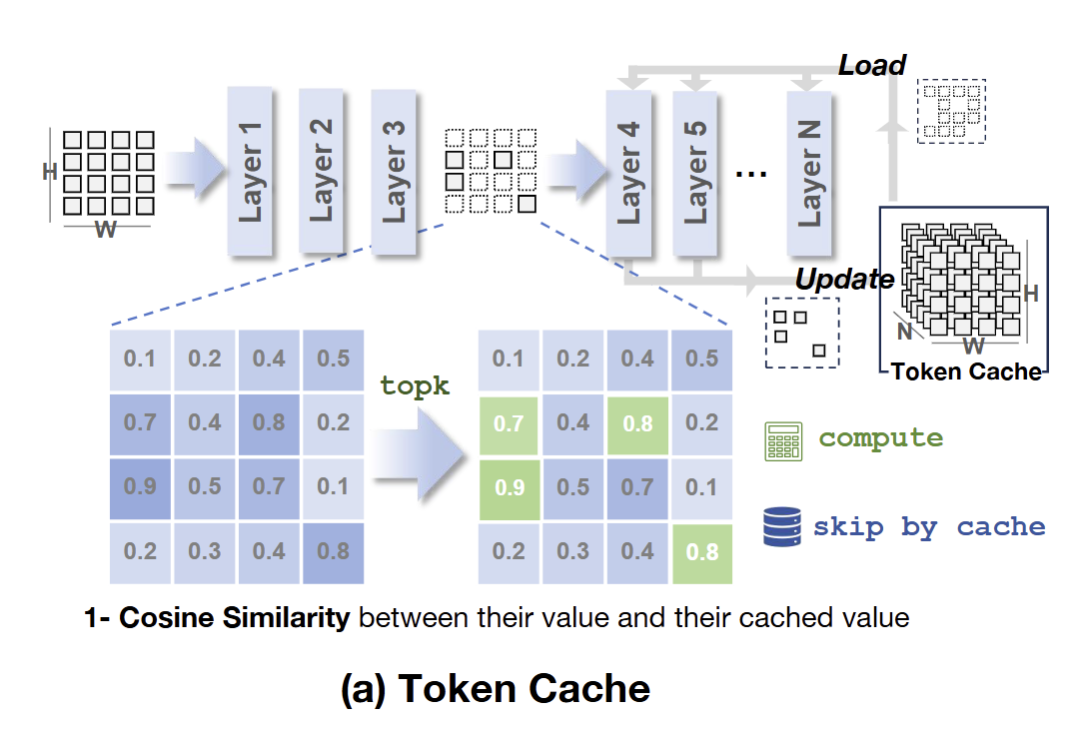
Token Cache 的 pipeline 如下:
假设某个周期,step 从 到 。在第一个 step ,计算所有的 token:
在中间的 step,比如第 $i+j(i+j<i+\tau)$ step,把所有的=”” token=”” 分成两组:计算组=”” $\mathcal{i}_{\text=”” {compute=”” }}$=”” 和=”” cache=”” 组=”” {cache=”” 。计算组=”” }}=”” \mathcal{i}_{\text=”” 选择相似度最大的=”” $n$=”” 个:<=”” p=””>
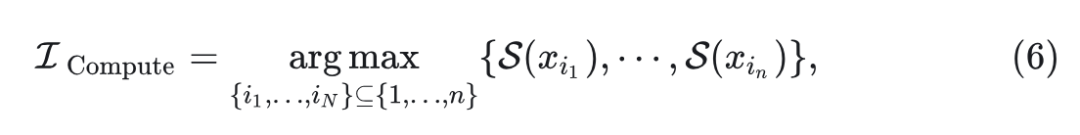
其中, 代表当前 step 和前面 step 的 token 的第 3 层特征的余弦相似度。 是 的剩余量。
然后,如图 2 所示,每一层的计算结果可表示为:
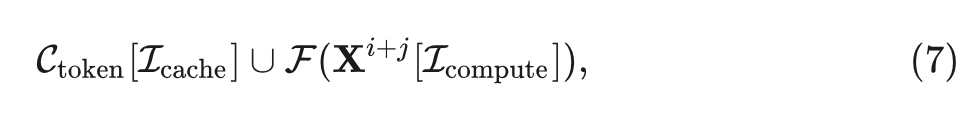
其中,左项表示从缓存中加载的结果,不需要计算成本,而右项表示计算的结果。通过将这种 Token Cache 应用于注意力和 MLP 层,可以跳过大量计算,从而获得更好的效率。
1.4 Condition 冗余
MAR 中广泛应用了 Classifier-Free Guidance (CFG)。CFG 通过两个并行输入来控制生成图像的内容,包括一个Conditional 的信息,和一个 Unconditional 的信息。这两个输入都在 MAR 中计算,其相应的输出以适当的比例混合。但这种双路径范式使 MAR 中的计算成本翻了一番。
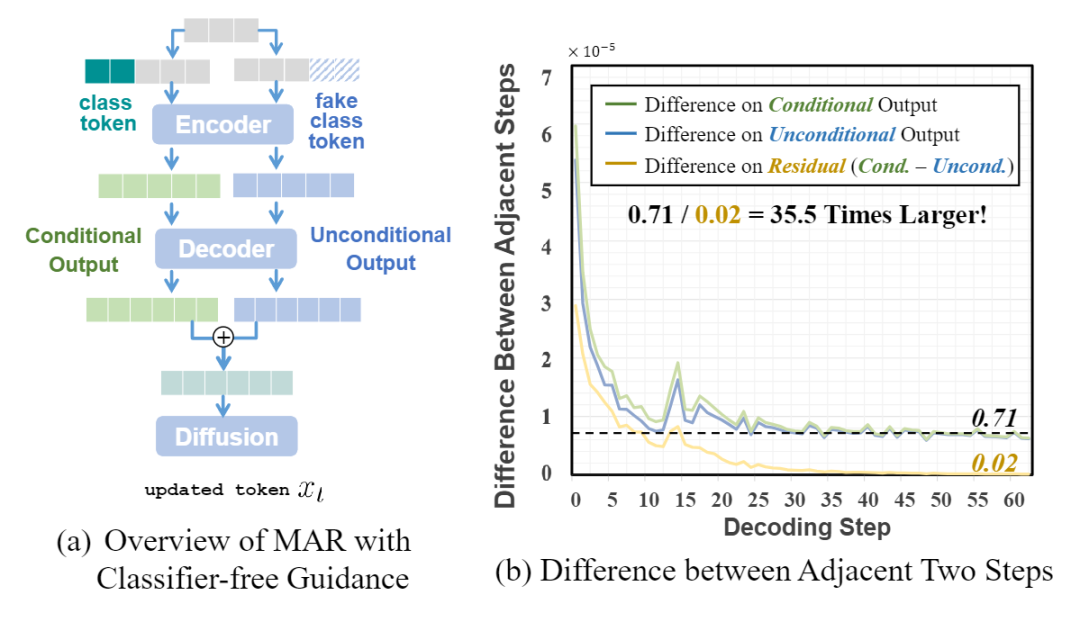
图 3 显示了在相邻的 decoding step 中,Conditional 和 Unconditional 的输出及二者差值 (cond. – uncond.) 的差别。值得注意的是,在相邻步骤中,Conditional 和 Unconditional 的输出都展示出了显著的距离都显示很大的值,唯独其差值展示出很小的值,小了大概 35.5 倍。换句话讲,Conditional 和 Unconditional 的差值 (cond. – uncond.) 在相邻的 step 中表现出非常小的值,提供了做 Cache 的可能性。
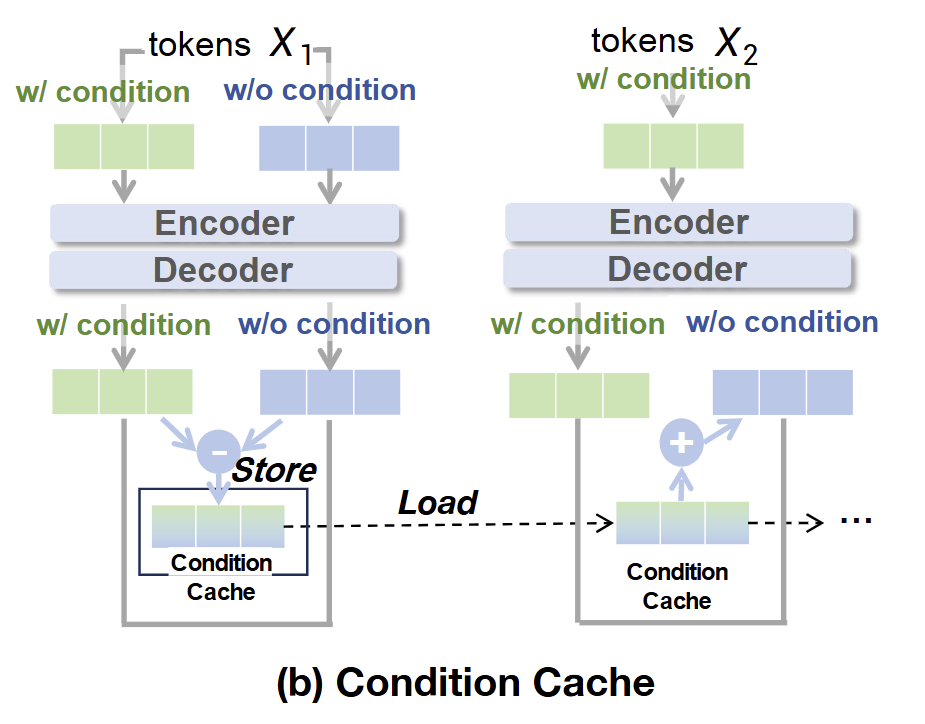
解决方案:Condition Cache
相邻 decoding step 中 Conditional 和 Unconditional 的差值很小,意味着可以在上一步中缓存这些残差,然后在后续步骤中重用它们。具体来说,在某一步计算 Unconditional Output 时候,我们可以拿这一步计算好的 Conditional Output 与之前缓存的差值来近似计算,无需真的去计算。显然,跳过两个分支中的一个将计算成本降低 50%。
将 Conditional Cache 表示为 ,对于从 到 的一系列 step,计算 Conditional 和 Unconditional 路径,并将它们第 step 的残差存一下。如图 4 所示,这个过程可以表述为:
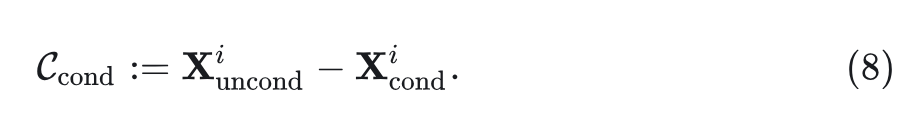
然后,在后续的第
通过这种方式,Condition Cache 使 MAR 能够节省一半的计算成本。
1.5 周期性缓存-复用-刷新
Token Cache 和 Condition Cache 在 MAR 的效率方面带来了显著的优势。但是,通过迭代地进行 cache 复用造成的近似误差的累积,会导致误差指数级放大。为此,本文提出周期性缓存-复用-刷新策略。每 个 decoding step,禁用缓存机制,计算所有 token 以及 Conditional 和 Unconditional 路径的结果,并使用这些真实值刷新缓存。
1.6 实验结果
为了全面评估本文方法的有效性,作者设置了两种不同的 decoding steps: 32 和 64。对于 decoding steps 为 32 的设置,从第 4 步开始缓存并设置 ,在每个 Cache decoding step 中跳过大约 250 个 token。对于 decoding steps 为 64 的设置,从第 5 步开始缓存并设置 ,在每个 Cache decoding step 中跳过大约 270 个 token。
作者在不同的加速度比下对 LazyMAR 和原始 MAR 进行了定性比较。如图 5 所示,在加速比为 2.8×,LazyMAR 也能保持较高的图像质量和语义保真度。在大多数情况下,LazyMAR 生成的图像与原始图像几乎无法区分。相比之下,通过减少解码步骤来加速通常会导致失真的图像,因为一个潜在的原因是在单个解码步骤中预测太多标记会损害当前步骤中解码的标记之间的协调和感知对齐。

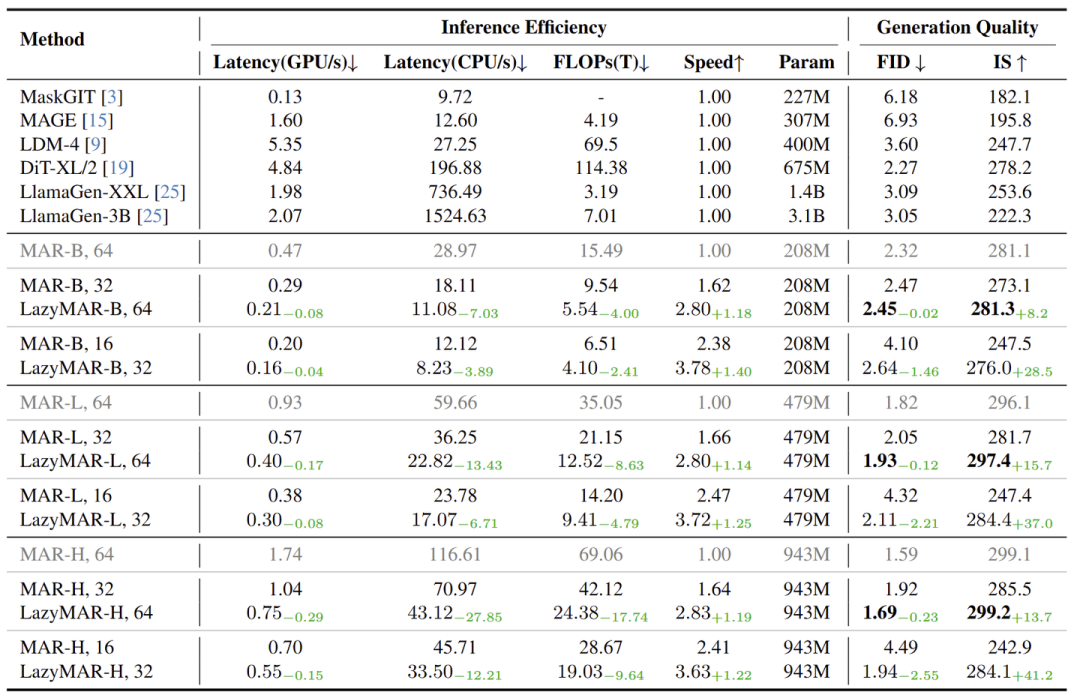
图 6 展示了本文方法的定量结果。可以观察到:
-
与具有相似 GPU/CPU Latency 的原始 MAR 相比,LazyMAR 在所有实验配置中实现了更好的 FID 和 IS,以及更好的加速比。 -
与原始 MAR 相比,LazyMAR 在保持可比较的图像生成质量的同时实现了大约 2.8 倍的加速。例如,LazyMAR-H, 64 实现了 2.83× 的加速,但性能上与原始 MAR (MAR-H, 64) 的最佳性能设置相比,FID 分数仅增加了 0.1,IS 也提升了 0.1。作为对比,MAR-H, 32 的加速比不如 LazyMAR-H, 64,但 FID 增加了 0.33,IS 下降了 13.6。 -
LazyMAR-H, 64 和 LazyMAR-L, 64 在计算效率和图像生成质量方面都优于较小的模型 (MAR-L, 64 和 MAR-B, 64)。
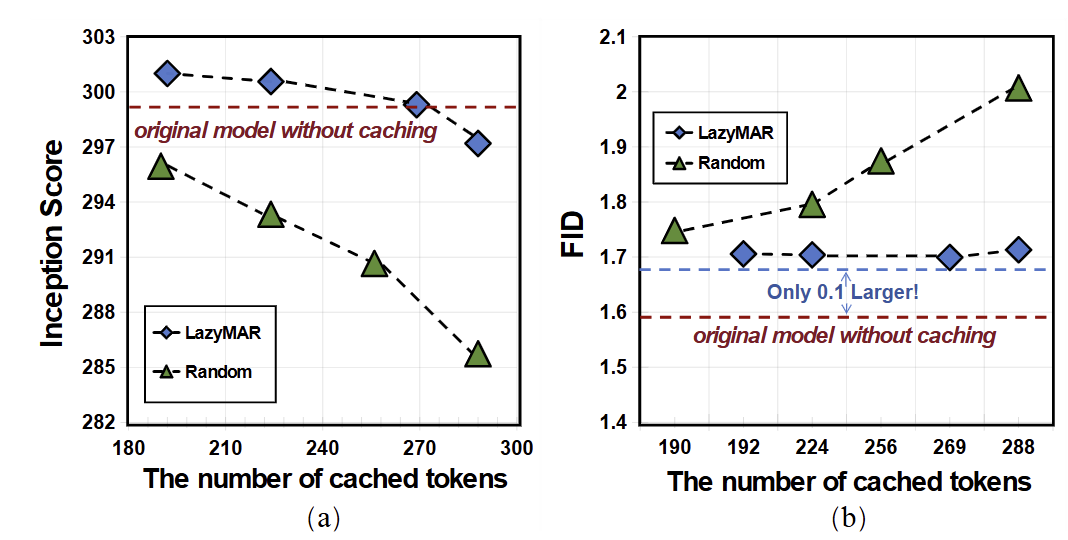
下图 7 展示了 LazyMAR 和 Random Cache 中的 Token Cache (即随机选择一些 token 进行 Cache 复用) 在具有不同数量的 Cache token 的 FID 和 Inception Score 的比较。与 Random Cache 相比,LazyMAR 在缓存相同数量的 token 时保持了更好的质量指标。很明显,随着缓存 Cache token 增加,LazyMAR 的指标变化不大。相比之下,Random Cache 的质量指标显着下降。值得注意的是,即使在缓存 90% (288/320) token 时,LazyMAR 仍然可以与原始模型相比保持可比较的 FID。
本文提出的两个缓存机制的有效性如图 8 所示。

实验结果揭示了两个关键发现:
-
每个缓存机制独立地有助于减少计算开销。 -
同时使用两种缓存机制时,LazyMAR 方法在同时保持生成图像的高保真度和质量的同时,实现了最佳加速。
(文:极市干货)